Обучение интеллектуальных противников с помощью самостоятельной игры с ML-агентами


В последнем выпуске инструментария ML-Agents Toolkit (v0.14) мы добавили функцию самостоятельной игры, которая позволяет обучать агентов-соперников в состязательных играх (как в играх с нулевой суммой, где выигрыш одного агента равен проигрышу другого). В этом блоге мы представим обзор самовоспроизведения и продемонстрируем, как оно обеспечивает стабильное и эффективное обучение на демонстрационной среде Soccer из набора инструментов ML-Agents.
В наборе инструментов Unity ML-Agents Toolkit агенты противостоят друг другу в качестве противников в средах для игры в теннис и футбол. Обучение агентов в таких сценариях может быть довольно сложным. На самом деле, в предыдущих версиях ML-Agents Toolkit надежное обучение агентов в таких средах требовало значительных затрат на разработку вознаграждения. В версии 0.14 мы предоставили пользователям возможность обучать агентов в играх посредством обучения с подкреплением (RL) на основе самостоятельной игры. Этот механизм является основополагающим для ряда наиболее известных результатов в области RL, таких как OpenAI Five и AlphaStar от DeepMind. В самоигре в качестве оппонентов используются нынешние и прошлые "я" агента. Это позволяет создать естественно совершенствующегося противника, против которого наш агент может постепенно совершенствоваться, используя традиционные алгоритмы RL. Полностью обученный агент может быть использован в качестве конкурента для опытных игроков.
Самостоятельная игра создает условия для обучения, аналогичные тому, как люди строят конкуренцию. Например, человек, обучающийся игре в теннис, будет тренироваться с соперниками схожего уровня мастерства, потому что слишком сильный или слишком слабый соперник не способствует обучению игре. С точки зрения совершенствования своих навыков, начинающему теннисисту гораздо полезнее соревноваться с другими начинающими, чем, скажем, с новорожденным ребенком или Новаком Джоковичем. Первые не могли вернуть мяч, а вторые не подавали им мяч, который они могли бы вернуть. Когда новичок достигает достаточной силы, он переходит на следующий уровень турнирной игры, чтобы сразиться с более сильными соперниками.
В этом блоге мы даем некоторые технические сведения о динамике самостоятельной игры, а также предоставляем обзор наших примеров окружений Tennis и Soccer, которые были рефакторизованы для демонстрации самостоятельной игры.
Понятие "самоиграй" имеет долгую историю в практике создания искусственных агентов для решения и конкуренции с людьми в играх. Одним из самых ранних вариантов использования этого механизма была система игры в шашки Артура Сэмюэля, разработанная в 50-х годах и опубликованная в 1959 году. Эта система стала предшественницей основополагающего результата в RL, TD-Gammon Джеральда Тесауро , опубликованного в 1995 году. TD-Gammon использовал алгоритм обучения временной разности TD(λ) с самоиграйкой для обучения агента для игры в нарды, который почти сравнялся с экспертами-людьми. В некоторых случаях было замечено, что TD-Gammon превосходит по позиционному пониманию игроков мирового класса.
Самостоятельная игра сыграла важную роль в ряде современных знаковых результатов в РЛ. В частности, она способствовала обучению сверхчеловеческих агентов в шахматах и го, элитных агентов DOTA 2, а также сложных стратегий и контрстратегий в таких играх, как рестлинг и прятки. В результатах, полученных с помощью самостоятельной игры, исследователи часто отмечают, что агенты обнаруживают стратегии, которые удивляют человеческих экспертов.
Самостоятельная игра в игры наделяет агентов определенной креативностью, не зависящей от программистов. Агенту дают только правила игры и сообщают, когда он выигрывает или проигрывает. Исходя из этих первых принципов, агент должен сам определить грамотное поведение. По словам создателя TD-Gammon, эта основа для обучения освобождает "...в том смысле, что программе не мешают человеческие предубеждения или предрассудки, которые могут быть ошибочными или ненадежными". Благодаря такой свободе агенты открыли блестящие стратегии, которые изменили представление человеческих экспертов о некоторых играх.
В традиционной задаче RL агент пытается выучить политику поведения, которая максимизирует некоторое накопленное вознаграждение. Сигнал вознаграждения кодирует задачу агента, например, навигацию к цели или сбор предметов. Поведение агента зависит от ограничений, накладываемых окружающей средой. Например, гравитация, наличие препятствий и относительное влияние собственных действий агента, таких как приложение силы для перемещения, - все это ограничения окружающей среды. Они ограничивают возможные варианты поведения агента и являются теми силами окружающей среды, с которыми он должен научиться справляться, чтобы получить высокую награду. Иными словами, агент вступает в борьбу с динамикой окружающей среды, чтобы посетить наиболее выгодные последовательности состояний.
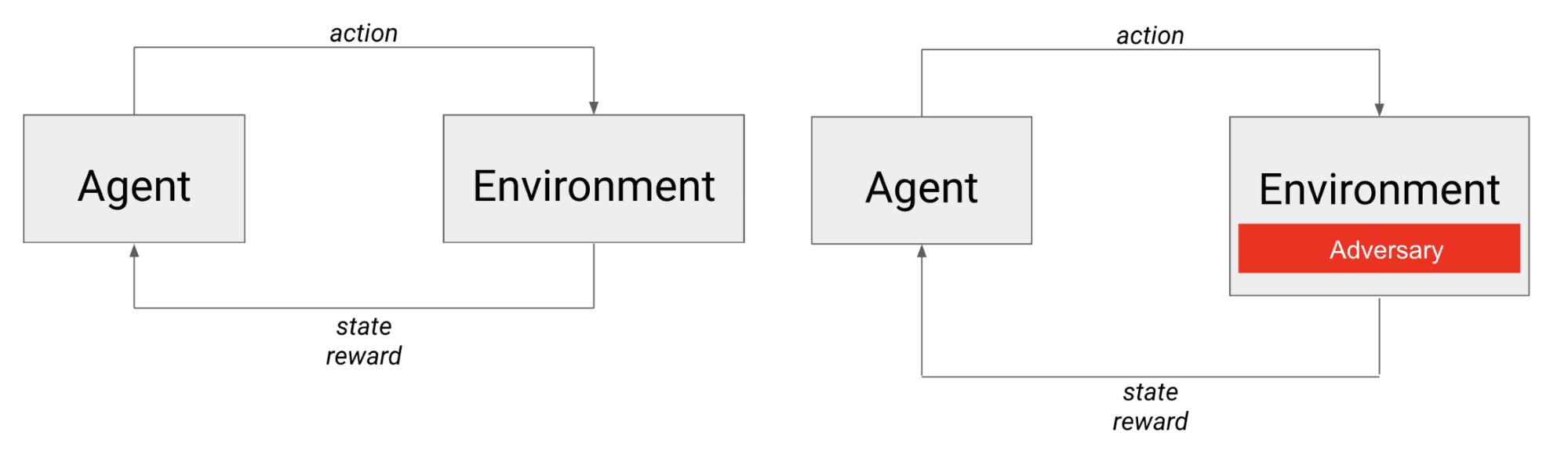
Слева - типичный сценарий RL: агент действует в среде и получает следующее состояние и вознаграждение. Справа - сценарий обучения, в котором агент соревнуется с противником, который, с точки зрения агента, фактически является частью среды.
В случае с состязательными играми агент противостоит не только динамике окружающей среды, но и другому (возможно, интеллектуальному) агенту. Можно считать, что противник встроен в среду, поскольку его действия напрямую влияют на следующее состояние агента, а также на получаемое им вознаграждение.

Давайте рассмотрим демо-версию теннисного турнира ML-Agents. Синяя ракетка (слева) - это обучающийся агент, а фиолетовая ракетка (справа) - противник. Чтобы перебить мяч через сетку, агент должен учесть траекторию полета мяча и скорректировать угол и скорость, чтобы противостоять гравитации (окружающей среде). Однако просто перебросить мяч через сетку - это только половина успеха, когда есть противник. Сильный противник может вернуть победный бросок, в результате чего агент проиграет. Слабый противник может попасть мячом в сетку. Равный противник может вернуть мяч, тем самым продолжив игру. В любом случае, следующее состояние и вознаграждение определяются как окружающей средой, так и противником. Однако во всех трех ситуациях агент попадал в одну и ту же точку. Это делает обучение в состязательных играх и тренировку конкурентного поведения агентов сложной задачей.
Соображения по поводу подходящего противника не являются тривиальными. Как показали предыдущие рассуждения, относительная сила соперника оказывает значительное влияние на исход отдельной игры. Если соперник слишком силен, агенту, начинающему с нуля, может быть слишком сложно его улучшить. С другой стороны, если противник слишком слаб, агент может научиться побеждать, но выученное поведение может оказаться бесполезным против другого или более сильного противника. Поэтому нам нужен соперник, примерно равный по уровню мастерства (сложный, но не слишком сложный). Кроме того, поскольку наш агент улучшается с каждой новой игрой, нам нужно эквивалентное увеличение противника.
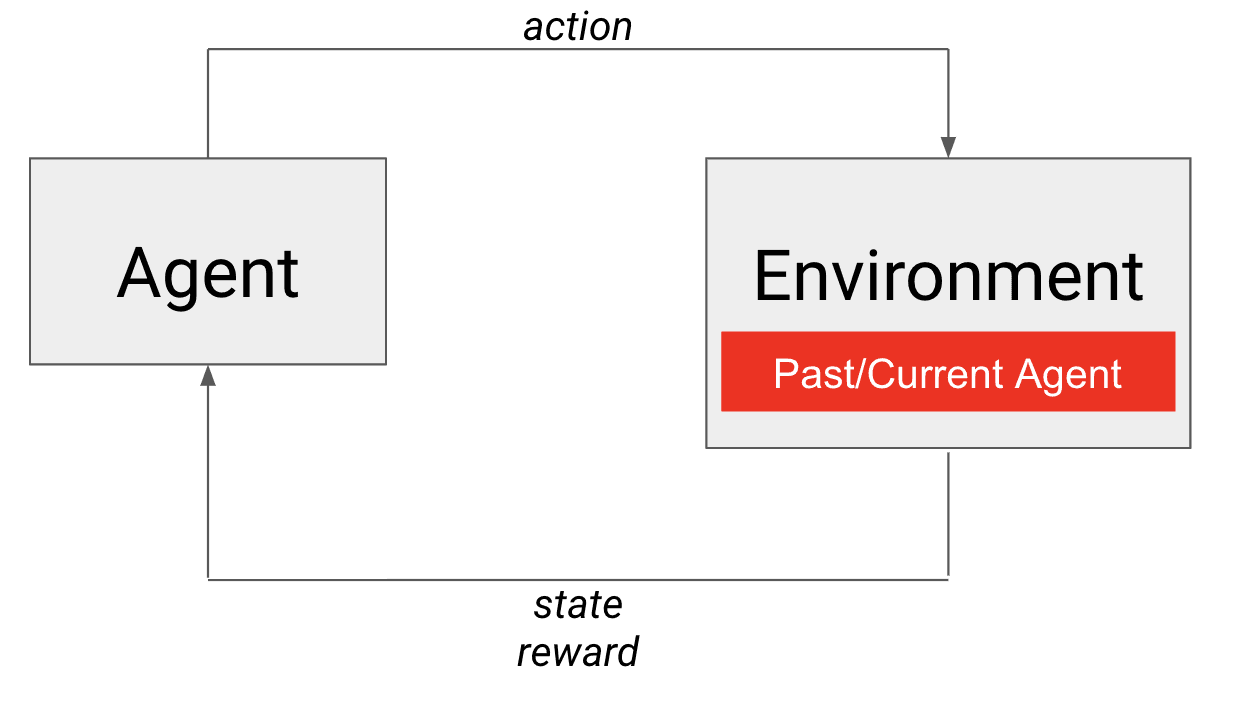
В самоигре прошлый снимок или текущий агент является противником, внедренным в окружающую среду.
Самостоятельная игра на помощь! Сам агент удовлетворяет обоим требованиям, предъявляемым к подходящему противнику. Он, конечно, примерно равен по мастерству (самому себе), а также улучшается со временем. В этом случае в среду встраивается собственная политика агента (см. рисунок). Для тех, кто знаком с учебными программами, можно представить это как естественно развивающуюся (также называемую автокурсом) учебную программу для тренировки нашего агента против противников с возрастающей силой. Таким образом, самостоятельная игра позволяет нам создать среду для обучения конкурентоспособных агентов для состязательных игр!
В следующих двух подразделах мы рассмотрим более технические аспекты обучения конкурентоспособных агентов, а также некоторые детали, связанные с использованием и реализацией самостоятельной игры в ML-Agents Toolkit. Эти два подраздела можно пропустить без ущерба для основной сути этой статьи.
Некоторые практические вопросы возникают в связи с концепцией самостоятельной игры. В частности, чрезмерная подгонка под определенный стиль игры и нестабильность процесса обучения, которая может возникнуть из-за нестационарности переходной функции (т.е. постоянно меняющегося противника). Первая проблема связана с тем, что мы хотим, чтобы наши агенты были универсальными конкурентами и устойчивыми к различным типам противников. В качестве примера можно привести ситуацию, когда в теннисе другой соперник будет возвращать мяч под другим углом и с другой скоростью. С точки зрения обучающегося агента, это означает, что одни и те же решения будут приводить к разным следующим состояниям по мере обучения. Традиционные алгоритмы RL предполагают стационарные функции перехода. К сожалению, предоставляя агенту разнообразный набор противников для решения первой проблемы, мы можем усугубить вторую, если не будем осторожны.
Чтобы решить эту проблему, мы храним буфер прошлых политик агента, из которого выбираем соперников, с которыми обучаемый соревнуется в течение более длительного времени. Благодаря выборке из прошлых политик агента, он увидит разнообразный набор противников. Более того, если позволить агенту тренироваться с фиксированным противником в течение длительного времени, это стабилизирует переходную функцию и создает более устойчивую среду обучения. Кроме того, этими алгоритмическими аспектами можно управлять с помощью гиперпараметров, обсуждаемых в следующем разделе.
При выборе гиперпараметров для самостоятельной игры главным является компромисс между уровнем мастерства и общностью конечной политики, а также стабильностью обучения. Обучение на множестве медленно меняющихся или неизменных противников с низким разнообразием приводит к более стабильному процессу обучения, чем обучение на множестве быстро меняющихся противников с высоким разнообразием. Доступные гиперпараметры управляют тем, как часто текущая политика агента сохраняется для последующего использования в качестве выбранного противника, как часто выбирается новый противник, количеством сохраненных противников и вероятностью игры против текущего агента и противника, выбранного из пула. Рекомендации по использованию гиперпараметров самовоспроизведения можно найти в документации по самовоспроизведению в репозитории ML-Agents на GitHub.
В состязательных играх суммарное вознаграждение среды может не быть значимой метрикой, по которой можно отслеживать прогресс в обучении. Это связано с тем, что кумулятивная награда полностью зависит от мастерства соперника. Агент определенного уровня квалификации получит большее или меньшее вознаграждение по сравнению с худшим или лучшим агентом, соответственно. Мы предлагаем реализацию рейтинговой системы ELO- метода расчета относительного уровня мастерства двух игроков из заданной популяции в игре с нулевой суммой. В ходе тренировки это значение должно постоянно увеличиваться. Вы можете отслеживать это с помощью TensorBoard вместе с другими показателями обучения, например, кумулятивным вознаграждением.
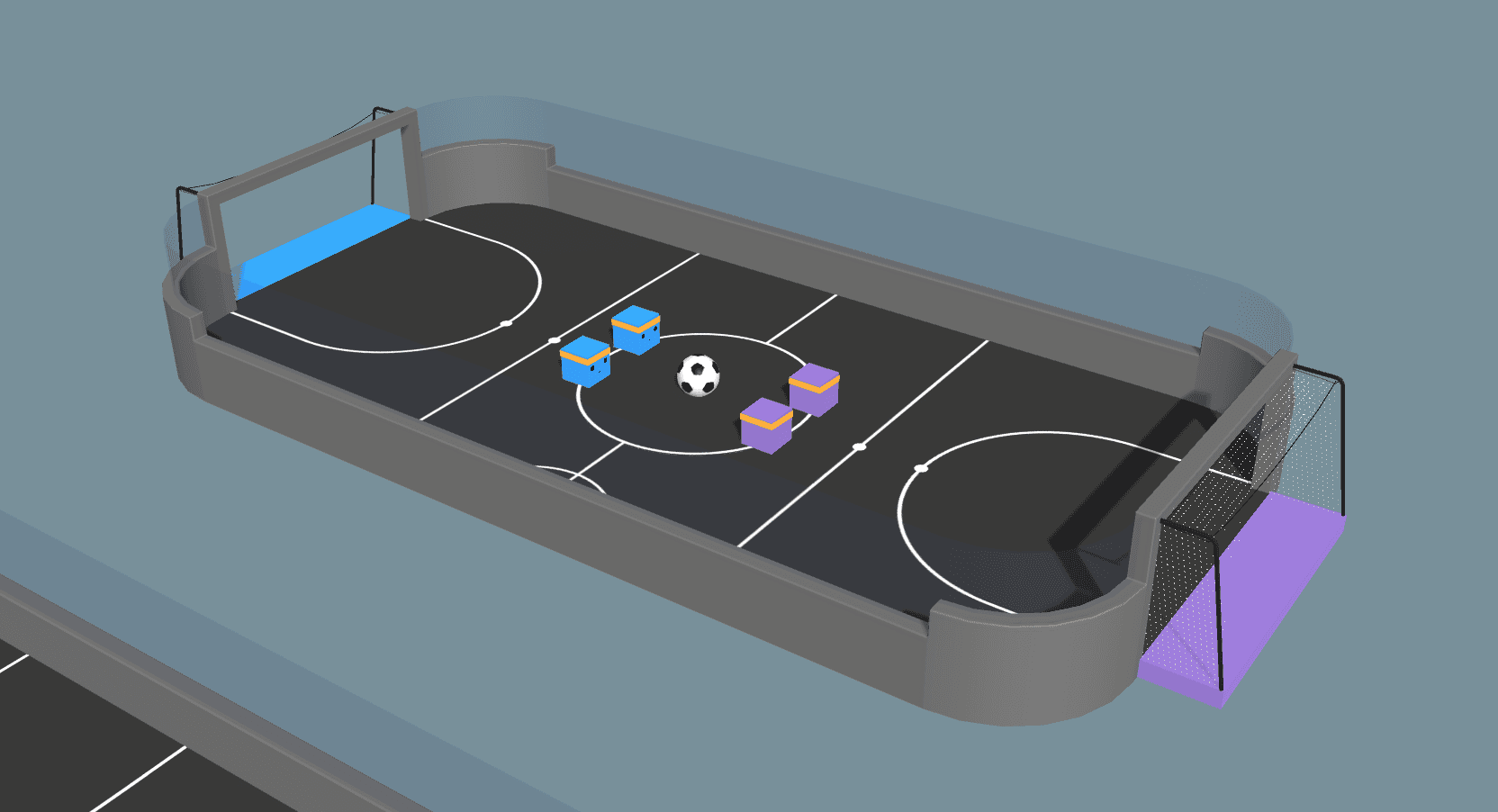
В последних выпусках мы не включали политику агента для нашей среды Soccer, поскольку ее нельзя было надежно обучить. Однако с помощью самовоспроизведения и некоторого рефакторинга мы теперь можем обучать нетривиальное поведение агентов. Самое значительное изменение - это исключение "позиций игроков" из числа агентов. Раньше в игре были явно выраженные вратарь и нападающий, которые мы использовали, чтобы игровой процесс выглядел разумно. На видео, показанном ниже, мы видим, как в новой обстановке возникает ролевое, совместное поведение вратаря и нападающего. Теперь агенты учатся играть эти позиции самостоятельно! Функция вознаграждения для всех четырех агентов определяется как +1,0 за забитый гол и -1,0 за забитый гол с дополнительным штрафом -0,0003 за тайм-ап, чтобы стимулировать агентов забивать.
Мы подчеркиваем, что обучение агентов в среде Soccer привело к кооперативному поведению без явного мультиагентного алгоритма или распределения ролей. Этот результат показывает, что мы можем обучать сложное поведение агентов с помощью простых алгоритмов, если мы тщательно подходим к формулировке нашей задачи. Ключом к достижению этой цели является то, что агенты могут наблюдать за своими товарищами по команде - то есть агенты получают информацию об относительном положении своих товарищей по команде в виде наблюдений. Агрессивно играя в направлении мяча, агент неявно сообщает своему товарищу по команде, что ему следует отступить в защиту. Или же, отступая в защиту, он подает сигнал своему товарищу по команде, что тот может двигаться вперед в нападении. На видео выше показано, как агенты улавливают эти сигналы, а также демонстрируют общую атакующую и оборонительную позицию!
Функция самостоятельной игры позволит вам обучать новых и интересных противников в своей игре. Если вы воспользуетесь функцией самостоятельной игры, пожалуйста, сообщите нам, как все прошло!
Если вы хотите работать на этом захватывающем перекрестке машинного обучения и игр, мы набираем несколько вакансий, обращайтесь!
Если вы используете какие-либо функции, представленные в этом выпуске, мы будем рады услышать от вас. Для получения отзывов о наборе инструментов Unity ML-Agents заполните, пожалуйста, следующую анкету и пишите нам напрямую. Если вы обнаружите какие-либо ошибки, пожалуйста, напишите нам об этом на странице проблем ML-Agents на GitHub. По всем общим вопросам и проблемам обращайтесь к нам на форумах Unity ML-Agents.