ML 에이전트로 셀프 플레이를 사용하여 지능형 적 훈련하기


최신 버전의 ML-Agents 툴킷(v0.14)에서는 적대적 게임(한 에이전트의 이득이 다른 에이전트의 손실과 정확히 일치하는 제로섬 게임)에서 경쟁 에이전트를 훈련할 수 있는 셀프 플레이 기능을 추가했습니다. 이 블로그 게시물에서는 셀프 플레이에 대한 개요를 제공하고 ML-Agents 툴킷의 축구 데모 환경에서 안정적이고 효과적인 훈련을 가능하게 하는 방법을 시연합니다.
Unity ML-Agents 툴킷의 테니스와 축구 예제 환경에서는 에이전트들이 서로 적으로 맞붙게 됩니다. 이러한 유형의 적대적 시나리오에서 상담원을 교육하는 것은 상당히 어려울 수 있습니다. 실제로 이전 버전의 ML-Agents 툴킷에서는 이러한 환경에서 에이전트를 안정적으로 훈련하려면 상당한 보상 엔지니어링이 필요했습니다. 0.14 버전에서는 사용자가 셀프 플레이를 통한 강화 학습(RL)을 통해 게임에서 에이전트를 훈련할 수 있게 되었으며, 이는 OpenAI Five와 DeepMind의 AlphaStar 등 RL에서 가장 주목받는 여러 결과의 기본 메커니즘입니다. 셀프 플레이는 상담원의 현재와 과거의 '자아'를 상대방으로 사용합니다. 이는 에이전트가 기존의 RL 알고리즘을 사용하여 점진적으로 개선할 수 있는 자연적으로 개선되는 적을 제공합니다. 완전히 훈련된 에이전트는 고급 인간 플레이어를 위한 경쟁자로 사용할 수 있습니다.
셀프 플레이는 인간이 경쟁을 구성하는 방식과 유사한 학습 환경을 제공합니다. 예를 들어, 테니스를 배우는 사람은 너무 강하거나 약한 상대는 게임을 배우는 데 도움이 되지 않기 때문에 비슷한 실력의 상대와 함께 훈련합니다. 실력 향상이라는 관점에서 보면 초급 수준의 테니스 선수가 갓 태어난 아이나 노박 조코비치와 경쟁하는 것보다 다른 초보자와 경쟁하는 것이 훨씬 더 가치가 있을 것입니다. 전자는 공을 반환할 수 없었고, 후자는 반환할 수 있는 공을 제공하지 않았습니다. 초보자가 충분한 실력을 갖추면 다음 단계의 토너먼트 플레이로 넘어가 더 강한 상대와 경쟁하게 됩니다.
이 블로그 게시물에서는 셀프 플레이의 역학 관계에 대한 기술적 인사이트와 셀프 플레이를 보여주기 위해 리팩토링된 테니스 및 축구 예제 환경에 대한 개요를 제공합니다.
셀프 플레이의 개념은 게임에서 인간과 문제를 풀고 경쟁하는 인공 에이전트를 만드는 데 오랜 역사를 가지고 있습니다. 이 메커니즘의 초기 사용 사례 중 하나는 50년대에 개발되어 1959년에 발표된 Arthur Samuel의 체커 플레이 시스템입니다. 이 시스템은 1995년에 출간된 제럴드 테사우로의 TD-Gammon인 RL의 중요한 결과물의 선구자였습니다. TD-Gammon은 시간차 학습 알고리즘 TD(λ)와 셀프 플레이를 사용하여 인간 전문가와 거의 비슷한 수준의 주사위 놀이 에이전트를 학습시켰습니다. 어떤 경우에는 TD-Gammon이 세계 정상급 선수들보다 포지션 이해도가 뛰어난 것으로 관찰되기도 했습니다.
셀프 플레이는 RL의 여러 획기적인 결과물에서 중요한 역할을 했습니다. 특히 초인적인 체스 및 바둑 실력자, 엘리트 DOTA 2 요원, 레슬링과 숨바꼭질 같은 게임에서 복잡한 전략과 카운터 전략을 학습하는 데 도움이 되었습니다. 셀프 플레이를 사용한 결과에서 연구자들은 종종 에이전트가 인간 전문가를 놀라게 하는 전략을 발견한다고 지적합니다.
게임에서 셀프 플레이는 프로그래머의 창의성과는 별개로 에이전트에게 특정 창의성을 불어넣습니다. 에이전트에게는 게임의 규칙만 주어지고 승패가 결정되면 알려줍니다. 이러한 첫 번째 원칙에서 유능한 행동을 발견하는 것은 상담원의 몫입니다. TD-Gammon을 만든 사람의 말에 따르면, 이 학습 프레임워크는 "...프로그램이 오류나 신뢰할 수 없는 인간의 편견이나 편견에 의해 방해받지 않는다는 점에서 자유롭습니다 ." 이러한 자유로움 덕분에 에이전트들은 인간 전문가들이 특정 게임을 바라보는 시각을 바꾼 뛰어난 전략을 발견할 수 있었습니다.
기존의 RL 문제에서 에이전트는 누적된 보상을 극대화하는 행동 정책을 학습하려고 합니다. 보상 신호는 목표 상태로 이동하거나 아이템을 수집하는 등의 상담원의 작업을 인코딩합니다. 상담원의 행동은 환경의 제약 조건에 따라 달라질 수 있습니다. 예를 들어 중력, 장애물의 존재, 에이전트가 스스로 움직이기 위해 힘을 가하는 등 에이전트 자신의 행동이 미치는 상대적인 영향은 모두 환경적 제약 조건입니다. 이는 에이전트의 실행 가능한 행동을 제한하며, 높은 보상을 얻기 위해 에이전트가 대처하는 방법을 배워야 하는 환경적 힘입니다. 즉, 에이전트는 환경의 역학 관계와 경쟁하여 가장 보람 있는 상태 시퀀스를 방문할 수 있도록 합니다.
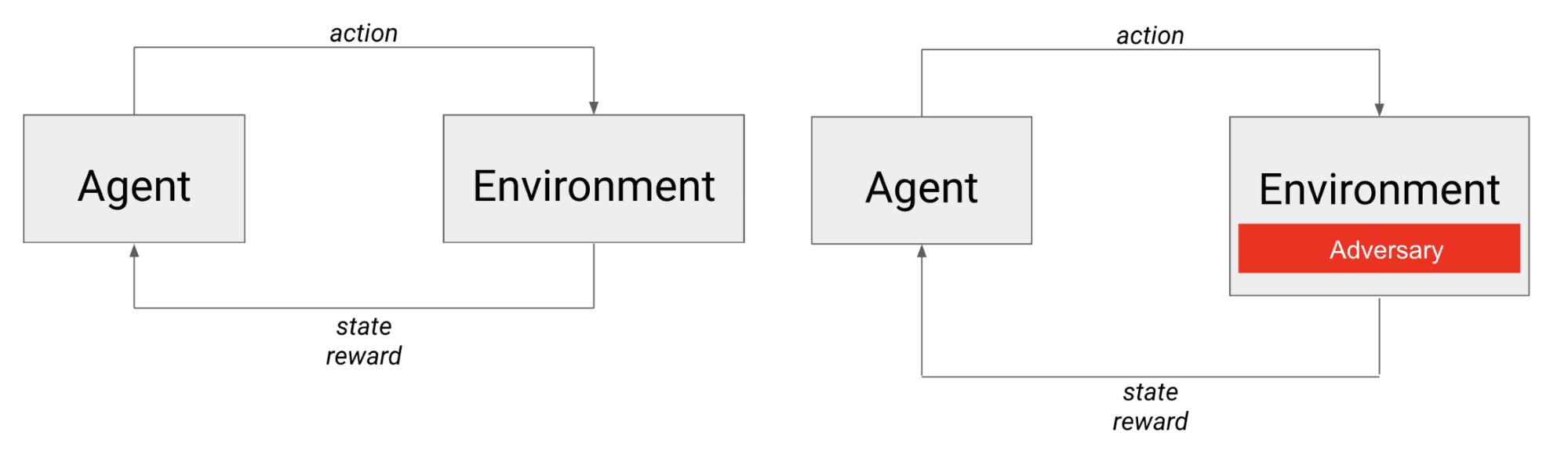
왼쪽은 에이전트가 환경에서 행동하고 다음 상태와 보상을 받는 일반적인 RL 시나리오입니다. 오른쪽은 에이전트의 관점에서 볼 때 사실상 환경의 일부인 적과 경쟁하는 학습 시나리오입니다.
적대적 게임의 경우 에이전트는 환경 역학뿐만 아니라 다른 (아마도 지능적인) 에이전트와도 경쟁합니다. 적의 행동은 에이전트가 관찰하는 다음 상태와 받는 보상에 직접적인 영향을 미치므로 적을 환경에 내장된 것으로 생각할 수 있습니다.

ML-Agents 테니스 데모를 살펴보겠습니다. 파란색 라켓(왼쪽)은 학습 에이전트이고 보라색 라켓(오른쪽)은 적입니다. 네트를 넘어 공을 치려면 에이전트는 들어오는 공의 궤적을 고려하고 그에 따라 각도와 속도를 조정하여 중력(환경)과 싸워야 합니다. 하지만 상대가 있는 상황에서 공을 네트 위로 넘기는 것만으로는 전투의 절반에 불과합니다. 강력한 상대가 위닝샷을 날려 에이전트가 패배할 수도 있습니다. 약한 상대가 공을 네트에 맞힐 수 있습니다. 동등한 상대가 공을 반환하여 게임을 계속할 수 있습니다. 어떤 경우든 다음 상태와 보상은 환경과 적에 의해 결정됩니다. 그러나 세 가지 상황 모두에서 상담원은 같은 샷을 쳤습니다. 따라서 적대적 게임에서 학습하고 경쟁 에이전트의 행동을 훈련하는 것은 어려운 문제입니다.
적절한 상대에 대한 고려 사항은 사소한 것이 아닙니다. 앞서 설명한 것처럼 상대방의 상대적 강점은 개별 게임의 결과에 큰 영향을 미칩니다. 상대가 너무 강하면 처음부터 시작하는 에이전트가 실력을 향상시키기가 너무 어려울 수 있습니다. 반면에 상대가 너무 약하면 에이전트는 승리하는 방법을 배울 수 있지만, 학습한 행동이 다른 상대나 더 강한 상대에게는 유용하지 않을 수 있습니다. 따라서 실력이 거의 비슷한(도전적이지만 너무 어렵지 않은) 상대가 필요합니다. 또한 새로운 게임이 나올 때마다 에이전트가 향상되기 때문에 그에 상응하는 상대가 필요합니다.
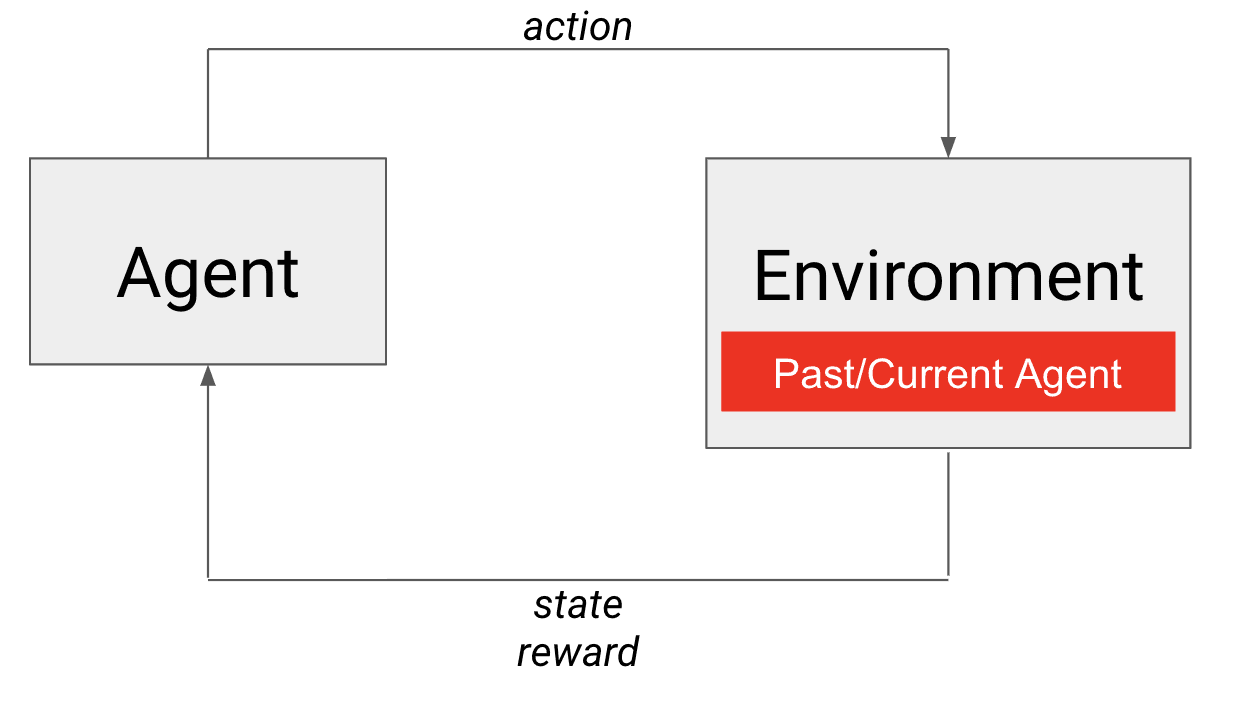
셀프 플레이에서는 과거 스냅샷 또는 현재 에이전트가 환경에 내장된 적입니다.
셀프 플레이가 구세주! 에이전트 자체는 적합한 상대에 대한 두 가지 요구 사항을 모두 충족합니다. 확실히 (그 자체로는) 기술이 거의 비슷하며 시간이 지남에 따라 향상됩니다. 이 경우 환경에 임베드되는 것은 상담원의 자체 정책입니다(그림 참조). 커리큘럼 학습에 익숙한 분이라면, 점점 강해지는 상대에 맞서 에이전트를 훈련시키기 위해 자연스럽게 진화하는( 자동 커리큘럼이라고도 하는) 커리큘럼이라고 생각하시면 됩니다. 따라서 셀프 플레이를 통해 적대적 게임을 위한 경쟁력 있는 에이전트를 훈련할 수 있는 환경을 부트스트랩할 수 있습니다!
다음 두 하위 섹션에서는 경쟁 에이전트 훈련의 기술적 측면과 ML-Agents 툴킷에서 셀프 플레이의 사용 및 구현과 관련된 몇 가지 세부 사항을 살펴봅니다. 이 두 하위 섹션은 이 블로그 게시물의 요점을 놓치지 않고 건너뛸 수 있습니다.
셀프 플레이 프레임워크에서 몇 가지 실질적인 문제가 발생합니다. 특히, 특정 플레이 스타일을 이기기 위한 과잉 피팅과 전환 함수의 비고정성(즉, 계속 바뀌는 상대)으로 인해 발생할 수 있는 훈련 과정의 불안정성입니다. 전자는 에이전트가 일반적인 경쟁자이자 다양한 유형의 상대에게 강해지기를 원하기 때문에 문제가 됩니다. 후자를 설명하기 위해 테니스 환경에서는 상대방이 다른 각도와 속도로 공을 리턴한다고 가정해 보겠습니다. 학습 에이전트의 관점에서 보면, 이는 학습이 진행됨에 따라 동일한 결정이 다른 다음 상태로 이어진다는 것을 의미합니다. 기존의 RL 알고리즘은 고정된 전환 함수를 가정합니다. 안타깝게도 에이전트에게 전자의 문제를 해결하기 위해 다양한 상대를 제공함으로써 조심하지 않으면 후자의 문제를 악화시킬 수 있습니다.
이를 해결하기 위해 에이전트의 과거 정책 버퍼를 유지하여 학습자가 경쟁하는 상대를 더 오래 샘플링합니다. 상담원의 과거 정책에서 샘플링하여 상담원은 다양한 상대방을 만나게 됩니다. 또한 에이전트가 고정된 상대를 상대로 더 오랜 시간 동안 훈련하게 하면 전환 기능이 안정화되고 보다 일관된 학습 환경을 조성할 수 있습니다. 또한 이러한 알고리즘 측면은 다음 섹션에서 설명하는 하이퍼파라미터를 사용하여 관리할 수 있습니다.
셀프 플레이 하이퍼파라미터 선택 시 주요 고려 사항은 최종 정책의 기술 수준과 일반성, 학습의 안정성 간의 절충점입니다. 다양성이 낮은 느리게 변화하거나 변하지 않는 적을 상대로 훈련하는 것이 다양성이 높은 빠르게 변화하는 적을 상대로 훈련하는 것보다 더 안정적인 학습 과정을 제공합니다. 사용 가능한 하이퍼파라미터는 에이전트의 현재 정책을 나중에 샘플링된 적으로 사용하기 위해 저장하는 빈도, 새로운 적을 샘플링하는 빈도, 저장된 적의 수, 에이전트의 현재 자신과 풀에서 샘플링된 적을 상대로 플레이할 확률을 제어합니다. 사용 가능한 셀프 플레이 하이퍼파라미터의 사용 가이드라인은 ML-Agents GitHub 리포지토리에 있는 셀프 플레이 문서를 참조하세요.
적대적 게임에서 누적 환경 보상은 학습 진행 상황을 추적하는 데 의미 있는 지표가 되지 못할 수 있습니다. 누적 보상은 전적으로 상대방의 실력에 따라 달라지기 때문입니다. 특정 스킬 레벨의 상담원은 스킬 레벨이 낮거나 높은 상담원에 대해 각각 더 많은 보상을 받거나 더 적은 보상을 받습니다. 제로섬 게임에서 주어진 집단에 속한 두 플레이어 간의 상대적 실력 수준을 계산하는 방법인 ELO 등급 시스템 구현을 제공합니다. 주어진 훈련 실행에서 이 값은 꾸준히 증가해야 합니다. 누적 보상과 같은 다른 교육 지표와 함께 TensorBoard를 사용하여 이를 추적할 수 있습니다.
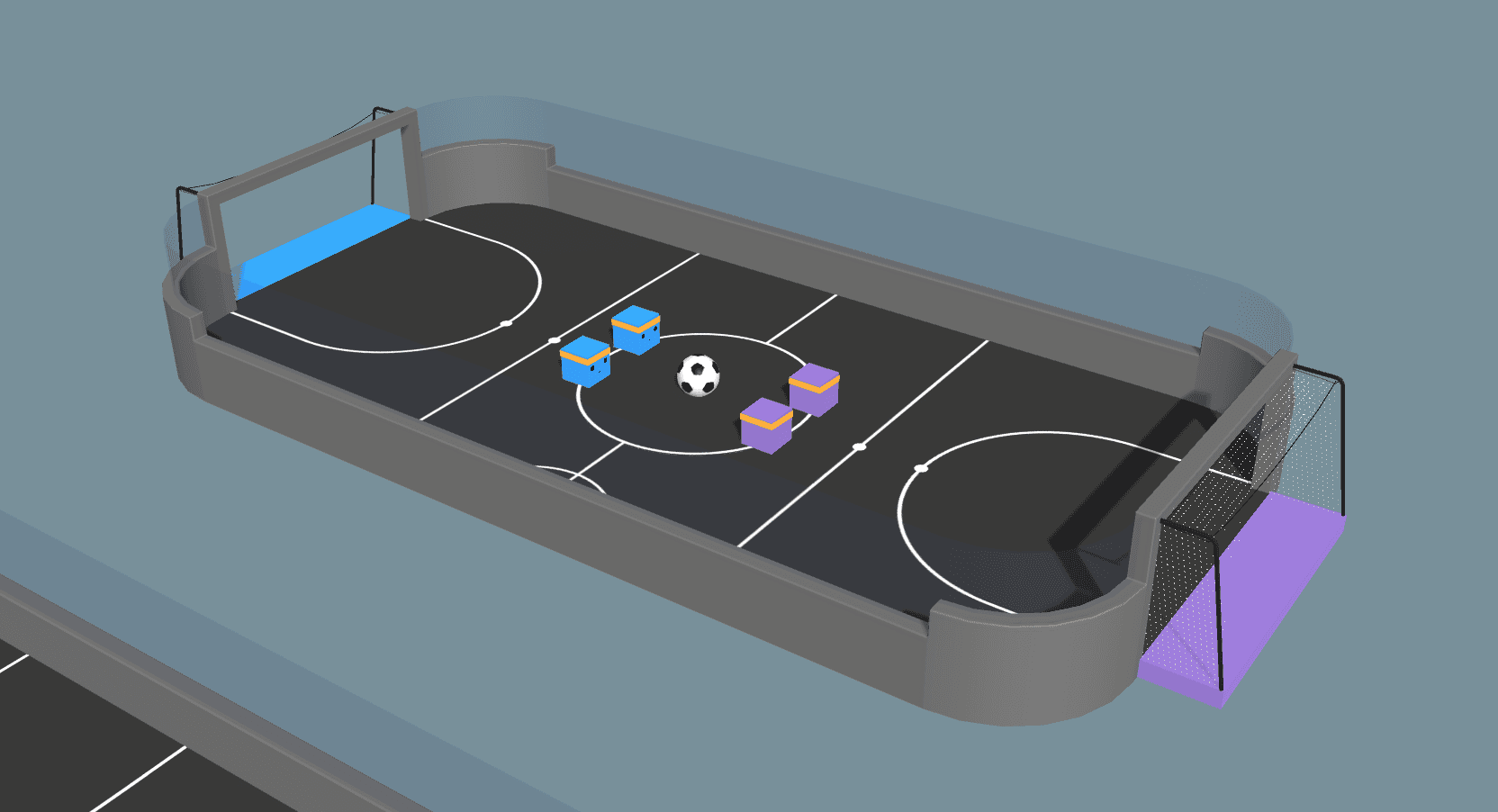
최근 릴리스에서는 축구 예제 환경에 대한 에이전트 정책을 포함하지 않았는데, 이는 안정적으로 훈련할 수 없었기 때문입니다. 하지만 셀프 플레이와 약간의 리팩터링을 통해 사소하지 않은 에이전트 동작을 훈련할 수 있게 되었습니다. 가장 큰 변화는 에이전트에서 '플레이어 포지션'을 제거한 것입니다. 이전에는 게임플레이를 합리적으로 보이게 하기 위해 명시적인 골키퍼와 스트라이커가 있었습니다. 새로운 환경에 대한 아래 동영상을 보면 실제로 골키퍼와 공격수처럼 역할에 따라 협력하는 행동이 나타나는 것을 확인할 수 있습니다. 이제 상담원들이 스스로 이러한 포지션을 연기하는 법을 배웁니다! 4명의 상담원 모두에 대한 보상 함수는 골을 넣으면 +1.0, 득점하면 -1.0으로 정의되며, 상담원의 득점을 장려하기 위해 시간당 -0.0003의 추가 페널티가 적용됩니다.
축구 환경에서 에이전트를 훈련시키면 명시적인 멀티 에이전트 알고리즘이나 역할 할당 없이도 협력적인 행동을 유도할 수 있다는 점을 강조합니다. 이 결과는 문제를 공식화할 때 주의만 기울인다면 간단한 알고리즘으로 복잡한 에이전트 행동을 훈련할 수 있음을 보여줍니다. 이를 달성하기 위한 핵심은 상담원이 팀원을 관찰할 수 있다는 것, 즉 상담원이 팀원의 상대적 위치에 대한 정보를 관찰 정보로 받는다는 것입니다. 에이전트는 공을 향해 공격적인 플레이를 함으로써 팀 동료에게 수비를 뒤로 물러나야 한다는 것을 암묵적으로 전달합니다. 또는 수비에서 뒤로 물러나면 팀 동료에게 공격에서 앞으로 나아갈 수 있다는 신호를 보냅니다. 위의 비디오는 에이전트가 이러한 신호를 포착하고 일반적인 공격 및 수비 포지셔닝을 시연하는 모습을 보여줍니다!
셀프 플레이 기능을 사용하면 게임에서 새롭고 흥미로운 적의 행동을 훈련할 수 있습니다. 셀프 플레이 기능을 사용하신다면 어떻게 사용하시는지 알려주세요!
머신러닝과 게임의 흥미로운 교차점에서 일하고 싶다면 유니티에서 여러 직책을 채용 중이니 많은 지원 바랍니다!
이번 릴리스가 제공하는 기능을 사용해 보고 많은 의견을 주시기 바랍니다. Unity ML-Agents 툴킷에 대한 의견이 있으시면 다음 설문조사를 작성하여 유니티에 직접 이메일을 보내주세요. 버그가 발생하면 ML-Agents GitHub 이슈 페이지에서 문의해 주세요. 일반적인 문제나 질문이 있는 경우 Unity ML-Agents 포럼에서 문의해 주세요.