利用 ML-Agents 自娱自乐训练智能对手


在最新发布的 ML-Agents 工具包(v0.14)中,我们添加了一项自我游戏功能,可以在对抗游戏(如零和游戏,即一个代理的收益正好是另一个代理的损失)中训练竞争代理。在这篇博文中,我们将概述自我播放功能,并演示如何在 ML-Agents 工具包中的 Soccer 演示环境上进行稳定而有效的培训。
Unity ML-Agents 工具包的网球和足球示例环境将代理作为对手相互对抗。在这种对抗性场景中对特工进行培训是非常具有挑战性的。事实上,在以前发布的ML-Agents 工具包中,在这些环境中可靠地训练代理需要大量的奖励工程。在0.14 版中,我们让用户能够通过自我游戏的强化学习(RL)在游戏中训练代理,这种机制是 RL 领域最引人注目的成果(如OpenAI Five和DeepMind 的 AlphaStar)的基础。自我游戏利用代理人当前和过去的 "自我 "作为对手。这就提供了一个自然改进的对手,我们的代理可以利用传统的 RL 算法逐步改进。训练有素的代理可作为高级人类玩家的竞争对手。
自我游戏提供了一种学习环境,类似于人类组织竞争的方式。例如,人类在学习打网球时,会与技术水平相近的对手进行训练,因为太强或太弱的对手都不利于学习比赛。从提高技能的角度来看,初学者与其他初学者比赛要比与新生儿或诺瓦克-德约科维奇比赛更有价值。前者无法回球,后者也不会为他们提供可以回球的球。当初学者达到足够的实力后,他们就可以进入下一级比赛,与更强的对手一较高下。
在这篇博文中,我们将从技术角度介绍自我游戏的动态,并概述我们为展示自我游戏而重构的网球和足球示例环境。
自我游戏的概念由来已久,在构建人工代理以解决游戏问题并与人类竞争的实践中,自我游戏的概念由来已久。阿瑟-塞缪尔(Arthur Samuel)在 50 年代开发并于1959 年出版的跳棋游戏系统就是这种机制的最早应用之一。这一系统是1995 年杰拉尔德-特索罗(Gerald Tesauro)发表的《TD-伽门》RL开创性成果的前身。 TD-Gammon使用时差学习算法TD(λ)和自我游戏来训练西洋双陆棋代理,该代理几乎可以与人类专家相媲美。据观察,在某些情况下,TD-Gammon 对位置的理解要优于世界级选手。
自我游戏在当代许多里程碑式的无线电通信成果中发挥了重要作用。值得注意的是,它促进了超人国际象棋和围棋代理、精英DOTA 2代理以及摔跤和捉迷藏等游戏中复杂策略和反策略的学习。在使用自我游戏的结果中,研究人员经常指出,代理发现的策略让人类专家大吃一惊。
游戏中的自我游戏赋予了代理一定的创造力,这种创造力独立于程序员的创造力。代理只被告知游戏规则和输赢时间。从这些首要原则出发,代理人就可以发现合格的行为。用 TD-Gammon 的创建者的话来说,这种学习框架是一种解放,"......因为程序不会受到可能是错误或不可靠的人类偏见或成见的阻碍"。这种自由度让特工们发现了绝妙的策略,改变了人类专家对某些游戏的看法。
在传统的 RL 问题中,代理试图学习一种行为策略,使累积奖励最大化。奖励信号编码了代理的任务,例如导航到目标状态或收集物品。代理的行为受到环境的制约。例如,地心引力、障碍物的存在以及代理自身行动的相对影响(如用力移动自己)都是环境制约因素。这些限制了代理的可行行为,也是代理为获得高回报而必须学会应对的环境力量。也就是说,代理要与环境的动态相抗衡,以便访问最有价值的状态序列。
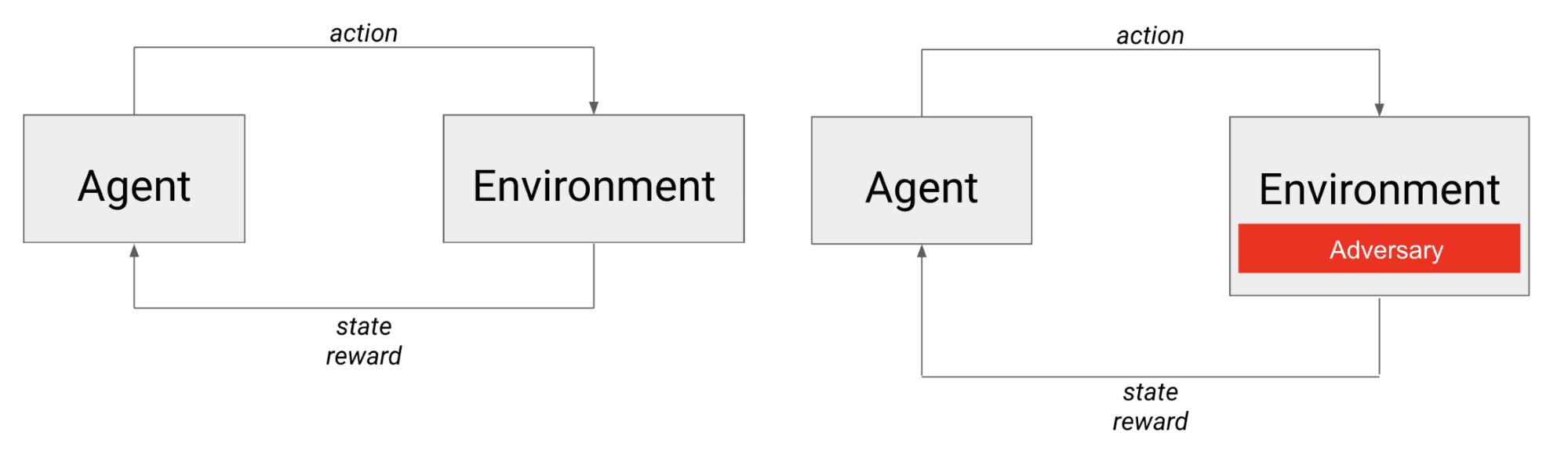
左侧是典型的 RL 场景:代理在环境中行动,并获得下一个状态和奖励;右侧是学习场景:代理与对手竞争,从代理的角度来看,对手实际上是环境的一部分。
在对抗性博弈中,代理不仅要与环境动态竞争,还要与另一个代理(可能是智能代理)竞争。我们可以把对手看作是嵌入在环境中的,因为它的行动会直接影响代理观察到的下一个状态,以及代理获得的奖励。

让我们看看 ML-Agents 网球演示。蓝色球拍(左)是学习代理,紫色球拍(右)是对手。要将球击出网外,代理必须考虑来球的轨迹,并相应地调整角度和速度,以对抗重力(环境)。然而,在有对手的情况下,仅仅把球送过网只是成功的一半。强大的对手可能会回敬一记制胜球,导致特工输掉比赛。弱小的对手可能会将球打入网中。旗鼓相当的对手可以回球,从而继续比赛。在任何情况下,下一个状态和奖励都是由环境和对手共同决定的。然而,在这三种情况下,特工都打中了同一枪。这就使得在对抗性游戏中学习和训练代理的竞争行为成为一个难题。
围绕适当对手的考虑并非微不足道。正如前面的讨论所示,对手的相对实力对单场比赛的结果有重大影响。如果对手过于强大,那么对于从零开始的特工来说,要想取得进步可能就太难了。另一方面,如果对手太弱,代理可能会学会获胜,但学到的行为在面对不同或更强的对手时可能就没用了。因此,我们需要一个技术水平大致相当的对手(具有挑战性,但又不太具有挑战性)。此外,由于我们的代理在每场新游戏中都在不断进步,因此我们需要对手也有相应的进步。
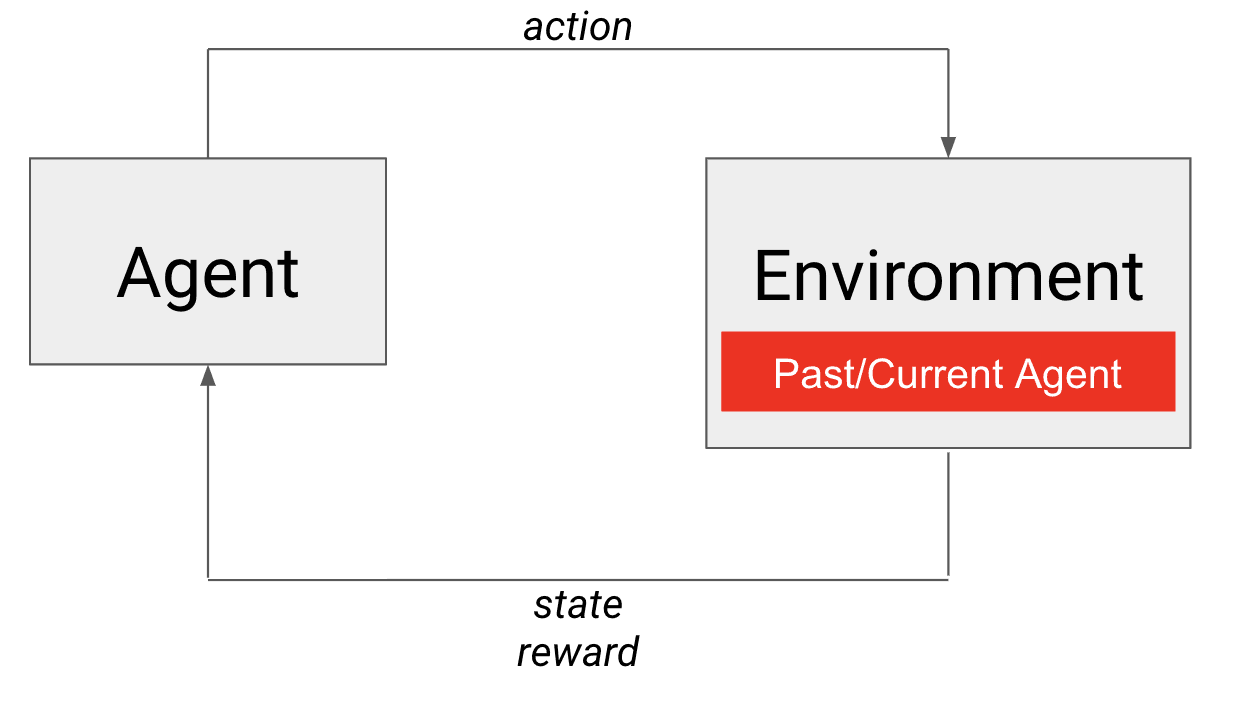
自我游戏框架产生了一些实际问题。具体来说,就是过度拟合以打败某种特定的打法,以及训练过程中的不稳定性,这种不稳定性可能源于过渡函数的非稳态性(即不断变化的对手)。前者是一个问题,因为我们希望我们的特工能成为一般的竞争者,并能应对不同类型的对手。为了说明后者,在网球环境中,不同的对手会以不同的角度和速度回球。从学习代理的角度来看,这意味着随着训练的进行,相同的决定会导致不同的下一个状态。传统的 RL 算法假定过渡函数是静止的。不幸的是,我们为代理人提供了各种各样的对手来解决前者的问题,一不小心就会加剧后者的问题。
为了解决这个问题,我们保留了一个代理过去策略 的缓冲区,从中抽取对手,让学习者与之进行更长时间的竞争。通过从代理过去的政策中取样,代理将看到一系列不同的对手。此外,让代理与固定的对手进行更长时间的训练,可以稳定过渡函数,创造更稳定的学习环境。此外,这些算法方面的问题可以通过下一节讨论的超参数进行管理。
在自我游戏超参数选择中,主要考虑的是最终策略的技能水平和通用性与学习稳定性之间的权衡。针对一组变化缓慢或不变且多样性较低的对手进行训练,比针对一组变化迅速且多样性较高的对手进行训练,学习过程更加稳定。可用的超参数控制着一个代理的当前策略被保存下来以后用作抽样对手的频率、新对手被抽样的频率、保存的对手数量,以及与代理当前的自己和从池中抽样的对手对战的概率。如需了解可用自播放超参数的使用指南,请参阅 ML-Agents GitHub 仓库中的自播放文档。
在对抗性游戏中,累计环境奖励可能并不是跟踪学习进度的有效指标。这是因为累积奖励完全取决于对手的技术。处于特定技能水平的特工与较差或较好的特工相比,将分别获得更多或更少的奖励。我们提供了一个ELO 评级系统的实施方案,这是一种在零和游戏中计算特定人群中两名玩家相对技术水平的方法。在特定的训练运行中,该值应稳步上升。您可以使用TensorBoard 和其他训练指标(如累积奖励)来跟踪这一点。
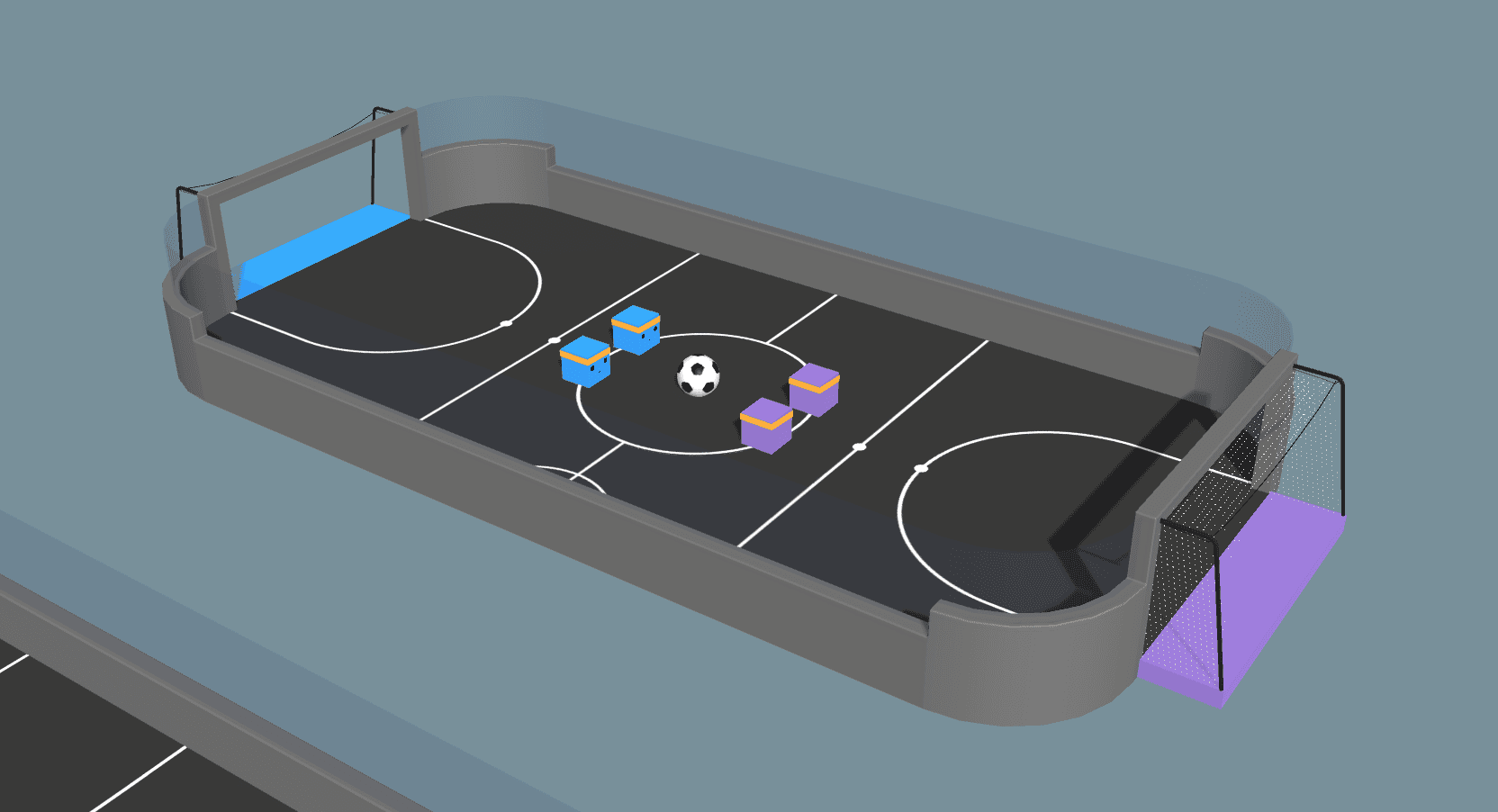
在最近的版本中,我们没有为足球示例环境提供代理策略,因为无法对其进行可靠的培训。不过,通过自我游戏和一些重构,我们现在已经能够训练出非同一般的代理行为。最重要的变化是从代理人中删除了 "球员位置"。在此之前,有明确的守门员和前锋,我们用他们来使游戏看起来合理。在下面这段关于新环境的视频中,我们实际上注意到了类似于守门员和前锋的角色合作行为。现在,特工们要学会自己打这些位置!所有四个代理的奖励函数定义为:进球奖励+1.0,被进球奖励-1.0,每时间步的额外惩罚为-0.0003,以鼓励代理进球。
我们强调的一点是,在足球环境中训练代理,无需明确的多代理算法或分配角色,就能产生合作行为。这一结果表明,只要我们在提出问题时小心谨慎,就能用简单的算法训练复杂的代理行为。要做到这一点,关键在于代理可以 观察他们的队友--也就是说,代理可以 通过观察接收到队友相对位置的信息。通过对球的积极争取,特工暗中向队友传达了自己应该回撤防守的信息。或者,通过后撤防守,它向队友发出信号:它可以向前进攻。上面的视频展示了特工如何捕捉这些线索,以及展示一般的进攻和防守位置!
自我游戏功能可让您在游戏中训练新颖有趣的对抗行为。如果您使用了自我播放功能,请告诉我们使用效果如何!
如果您想在机器学习和游戏这一令人兴奋的交叉领域工作,我们正在招聘多个职位,请申请!
如果您使用了本版本中提供的任何功能,我们很乐意听取您的意见。如对 Unity ML-Agents 工具包有任何反馈意见,请填写以下调查表,并随时直接给我们发送电子邮件。如果遇到任何错误,请在ML-Agents GitHub 问题页面与我们联系。如有任何一般问题和疑问,请在Unity ML-Agents 论坛上联系我们。