Entrenar a adversarios inteligentes utilizando el autojuego con los agentes ML


En la última versión del ML-Agents Toolkit (v0.14), hemos añadido una función de juego automático que permite entrenar agentes competitivos en juegos adversarios (como los juegos de suma cero, en los que la ganancia de un agente es exactamente la pérdida del otro). En esta entrada de blog, ofrecemos una visión general de la reproducción automática y demostramos cómo permite una formación estable y eficaz en el entorno de demostración de Fútbol en el ML-Agents Toolkit.
Los entornos de ejemplo Tenis y Fútbol del Unity ML-Agents Toolkit enfrentan a los agentes entre sí como adversarios. Entrenar a los agentes en este tipo de escenario adversario puede ser todo un reto. De hecho, en versiones anteriores del ML-Agents Toolkit, el entrenamiento fiable de agentes en estos entornos requería una importante ingeniería de recompensas. En la versión 0.14, hemos permitido a los usuarios entrenar agentes en juegos mediante aprendizaje por refuerzo (RL) a partir del juego propio, un mecanismo fundamental para varios de los resultados más destacados en RL, como OpenAI Five y AlphaStar de DeepMind. El autojuego utiliza los "yo" actuales y pasados del agente como oponentes. Esto proporciona un adversario que mejora de forma natural contra el que nuestro agente puede mejorar gradualmente utilizando algoritmos tradicionales de RL. El agente totalmente entrenado puede utilizarse como competición para jugadores humanos avanzados.
El autojuego proporciona un entorno de aprendizaje análogo a la forma en que los humanos estructuran la competición. Por ejemplo, un ser humano que esté aprendiendo a jugar al tenis se entrenará contra oponentes de nivel similar, porque un oponente demasiado fuerte o demasiado débil no favorece el aprendizaje del juego. Desde el punto de vista de la mejora de las propias habilidades, sería mucho más valioso para un tenista de nivel principiante competir contra otros principiantes que, por ejemplo, contra un recién nacido o Novak Djokovic. Los primeros no podían devolver el balón, y los segundos no les servían un balón que pudieran devolver. Cuando el principiante ha alcanzado la fuerza suficiente, pasa al siguiente nivel de juego del torneo para competir con oponentes más fuertes.
En esta entrada de blog, ofrecemos una visión técnica de la dinámica del juego automático, así como una descripción general de nuestros entornos de ejemplo de tenis y fútbol, que se han refactorizado para mostrar el juego automático.
La noción de juego autónomo tiene una larga historia en la práctica de la construcción de agentes artificiales para resolver y competir con humanos en juegos. Uno de los primeros usos de este mecanismo fue el sistema de juego de damas de Arthur Samuel, desarrollado en los años 50 y publicado en 1959. Este sistema fue precursor del resultado seminal en RL, el TD-Gammon de Gerald Tesauro publicado en 1995. TD-Gammon utilizó el algoritmo de aprendizaje por diferencia temporal TD(λ) con autojuego para entrenar a un agente de backgammon que casi rivalizaba con los expertos humanos. En algunos casos, se observó que TD-Gammon tenía una comprensión posicional superior a la de los jugadores de talla mundial.
El juego por cuenta propia ha sido decisivo en una serie de resultados contemporáneos emblemáticos en la LR. En concreto, facilitó el aprendizaje de agentes sobrehumanos de ajedrez y Go, agentes de élite de DOTA 2, así como estrategias y contraestrategias complejas en juegos como la lucha libre y el escondite. En los resultados que utilizan el autojuego, los investigadores suelen señalar que los agentes descubren estrategias que sorprenden a los expertos humanos.
El autojuego en los juegos dota a los agentes de cierta creatividad, independiente de la de los programadores. Al agente sólo se le dan las reglas del juego y se le dice cuándo gana o pierde. A partir de estos primeros principios, corresponde al agente descubrir un comportamiento competente. En palabras del creador de TD-Gammon, este marco de aprendizaje es liberador "...en el sentido de que el programa no se ve obstaculizado por sesgos o prejuicios humanos que puedan ser erróneos o poco fiables". Esta libertad ha llevado a los agentes a descubrir estrategias brillantes que han cambiado la forma en que los expertos humanos ven ciertos juegos.
En un problema tradicional de RL, un agente intenta aprender una política de comportamiento que maximice alguna recompensa acumulada. La señal de recompensa codifica la tarea de un agente, como navegar hasta un estado objetivo o recoger objetos. El comportamiento del agente está sujeto a las restricciones del entorno. Por ejemplo, la gravedad, la presencia de obstáculos y la influencia relativa que tienen las propias acciones del agente, como aplicar fuerza para moverse, son restricciones del entorno. Estos limitan los comportamientos viables del agente y son las fuerzas ambientales con las que el agente debe aprender a lidiar para obtener una recompensa alta. Es decir, el agente compite con la dinámica del entorno para poder visitar las secuencias de estados más gratificantes.
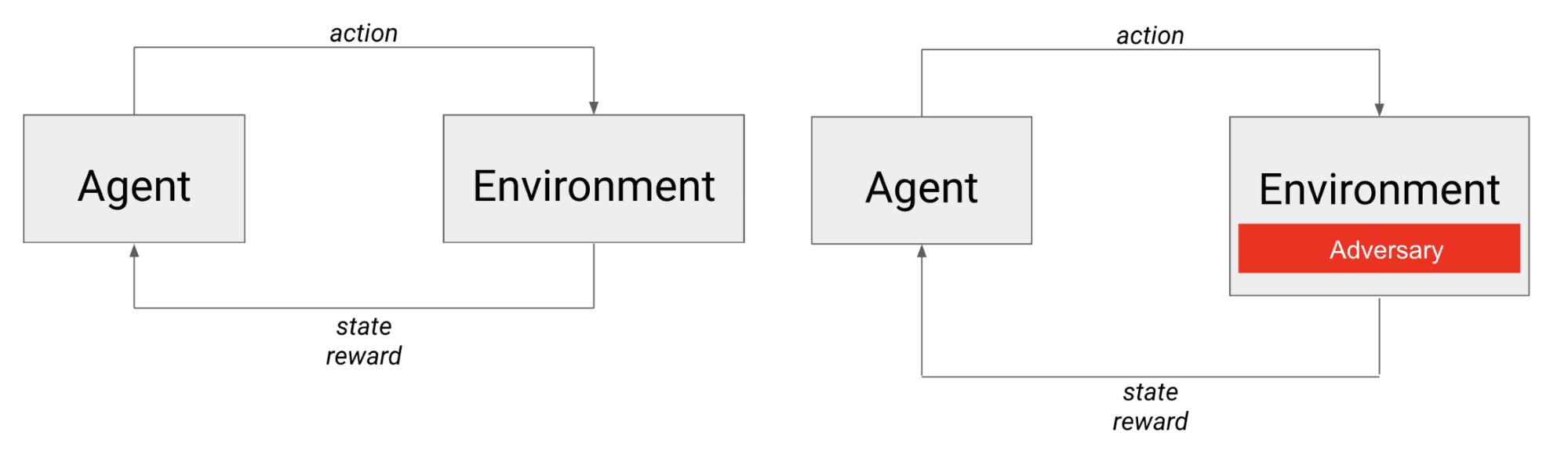
A la izquierda, el escenario típico de RL: un agente actúa en el entorno y recibe el siguiente estado y una recompensa. A la derecha, el escenario de aprendizaje en el que el agente compite con un adversario que, desde la perspectiva del agente, forma parte del entorno.
En el caso de los juegos adversariales, el agente no sólo se enfrenta a la dinámica del entorno, sino también a otro agente (posiblemente inteligente). Se puede pensar que el adversario está incrustado en el entorno, ya que sus acciones influyen directamente en el siguiente estado que observa el agente, así como en la recompensa que recibe.

Veamos la demostración de tenis de ML-Agents. La raqueta azul (izquierda) es el agente de aprendizaje, y la raqueta morada (derecha) es el adversario. Para golpear la pelota por encima de la red, el agente debe tener en cuenta la trayectoria de la pelota entrante y ajustar su ángulo y velocidad en consecuencia para hacer frente a la gravedad (el entorno). Sin embargo, lanzar el balón por encima de la red es sólo la mitad de la batalla cuando hay un adversario. Un adversario fuerte puede devolver un tiro ganador haciendo que el agente pierda. Un adversario débil puede golpear el balón contra la red. Un adversario igual puede devolver el balón, continuando así el juego. En cualquier caso, el siguiente estado y la recompensa vienen determinados tanto por el entorno como por el adversario. Sin embargo, en las tres situaciones, el agente acertó el mismo tiro. Esto hace que el aprendizaje en juegos adversariales y el entrenamiento de comportamientos de agentes competitivos sea un problema difícil.
Las consideraciones en torno a un oponente adecuado no son triviales. Como se ha demostrado en el debate anterior, la fuerza relativa del adversario tiene un impacto significativo en el resultado de un partido individual. Si un oponente es demasiado fuerte, puede ser muy difícil para un agente que empieza de cero mejorar. Por otro lado, si un oponente es demasiado débil, un agente puede aprender a ganar, pero el comportamiento aprendido puede no ser útil contra un oponente diferente o más fuerte. Por lo tanto, necesitamos un oponente que sea aproximadamente igual en habilidad (desafiante pero no demasiado). Además, como nuestro agente mejora con cada nueva partida, necesitamos un aumento equivalente en el adversario.
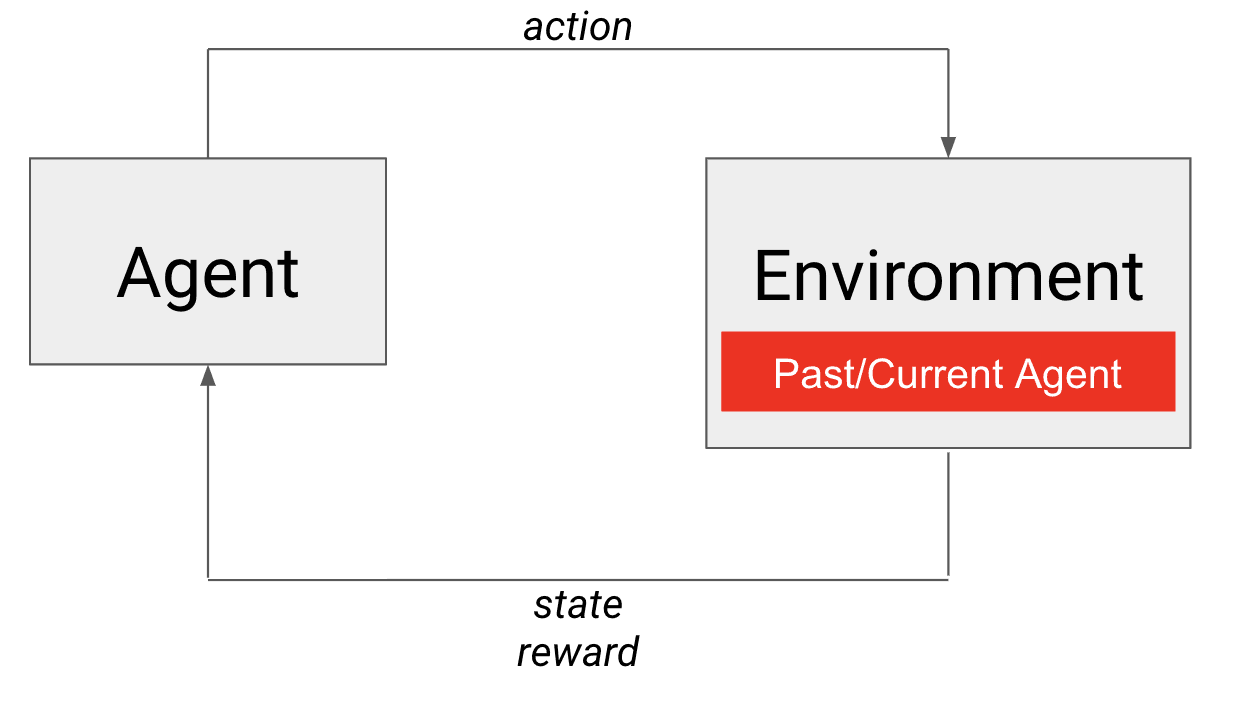
En el autojuego, una instantánea pasada o el agente actual es el adversario incrustado en el entorno.
El autojuego al rescate El propio agente cumple ambos requisitos para ser un adversario adecuado. Desde luego, es más o menos igual de hábil (consigo mismo) y además mejora con el tiempo. En este caso, es la propia política del agente la que se incrusta en el entorno (véase la figura). Para quienes estén familiarizados con el aprendizaje curricular, pueden pensar que se trata de un plan de estudios que evoluciona de forma natural (también denominado autocurrículo) para entrenar a nuestro agente contra adversarios cada vez más fuertes. De este modo, el autojuego nos permite crear un entorno para entrenar a agentes competitivos en juegos adversarios.
En las dos subsecciones siguientes, consideramos aspectos más técnicos del entrenamiento de agentes competitivos, así como algunos detalles que rodean el uso y la implementación del autojuego en el ML-Agents Toolkit. Estas dos subsecciones pueden omitirse sin que ello afecte a la idea principal de esta entrada del blog.
El marco del juego autónomo plantea algunas cuestiones prácticas. En concreto, el sobreajuste para derrotar a un estilo de juego concreto y la inestabilidad en el proceso de entrenamiento que puede surgir de la no estacionariedad de la función de transición (es decir, el adversario en constante cambio). Lo primero es un problema porque queremos que nuestros agentes sean competidores generales y resistentes a distintos tipos de adversarios. Para ilustrar esto último, en el entorno del tenis, otro adversario devolverá la pelota con un ángulo y una velocidad diferentes. Desde la perspectiva del agente de aprendizaje, esto significa que las mismas decisiones conducirán a diferentes estados siguientes a medida que avance el entrenamiento. Los algoritmos tradicionales de RL asumen funciones de transición estacionarias. Desgraciadamente, al proporcionar al agente un conjunto diverso de oponentes para hacer frente a lo primero, podemos exacerbar lo segundo si no tenemos cuidado.
Para solucionarlo, mantenemos una memoria intermedia de las políticas anteriores del agente de la que extraemos oponentes contra los que el aprendiz compite durante más tiempo. Mediante el muestreo de las políticas anteriores del agente, éste verá un conjunto diverso de oponentes. Además, dejar que el agente entrene contra un oponente fijo durante más tiempo estabiliza la función de transición y crea un entorno de aprendizaje más consistente. Además, estos aspectos algorítmicos pueden gestionarse con los hiperparámetros que se analizan en la siguiente sección.
Con la selección de hiperparámetros de juego automático, la principal consideración es el equilibrio entre el nivel de habilidad y la generalidad de la política final, y la estabilidad del aprendizaje. El entrenamiento contra un conjunto de adversarios que cambian lentamente o que no cambian con una diversidad baja da lugar a un proceso de aprendizaje más estable que el entrenamiento contra un conjunto de adversarios que cambian rápidamente con una diversidad alta. Los hiperparámetros disponibles controlan la frecuencia con la que se guarda la política actual de un agente para utilizarla más tarde como adversario muestreado, la frecuencia con la que se muestrea un nuevo adversario, el número de adversarios guardados y la probabilidad de jugar contra el yo actual del agente frente a un adversario muestreado del pool. Para conocer las directrices de uso de los hiperparámetros de reproducción automática disponibles, consulte la documentación de reproducción automática en el repositorio GitHub de ML-Agents.
En los juegos adversariales, la recompensa acumulada del entorno puede no ser una métrica significativa para seguir el progreso del aprendizaje. Esto se debe a que la recompensa acumulada depende totalmente de la habilidad del oponente. Un agente con un determinado nivel de habilidad obtendrá más o menos recompensa frente a un agente peor o mejor, respectivamente. Proporcionamos una implementación del sistema de clasificación ELO, un método para calcular el nivel de habilidad relativo entre dos jugadores de una población determinada en un juego de suma cero. En un entrenamiento determinado, este valor debería aumentar de forma constante. Puedes hacer un seguimiento de esto utilizando TensorBoard junto con otras métricas de entrenamiento, por ejemplo, la recompensa acumulada.
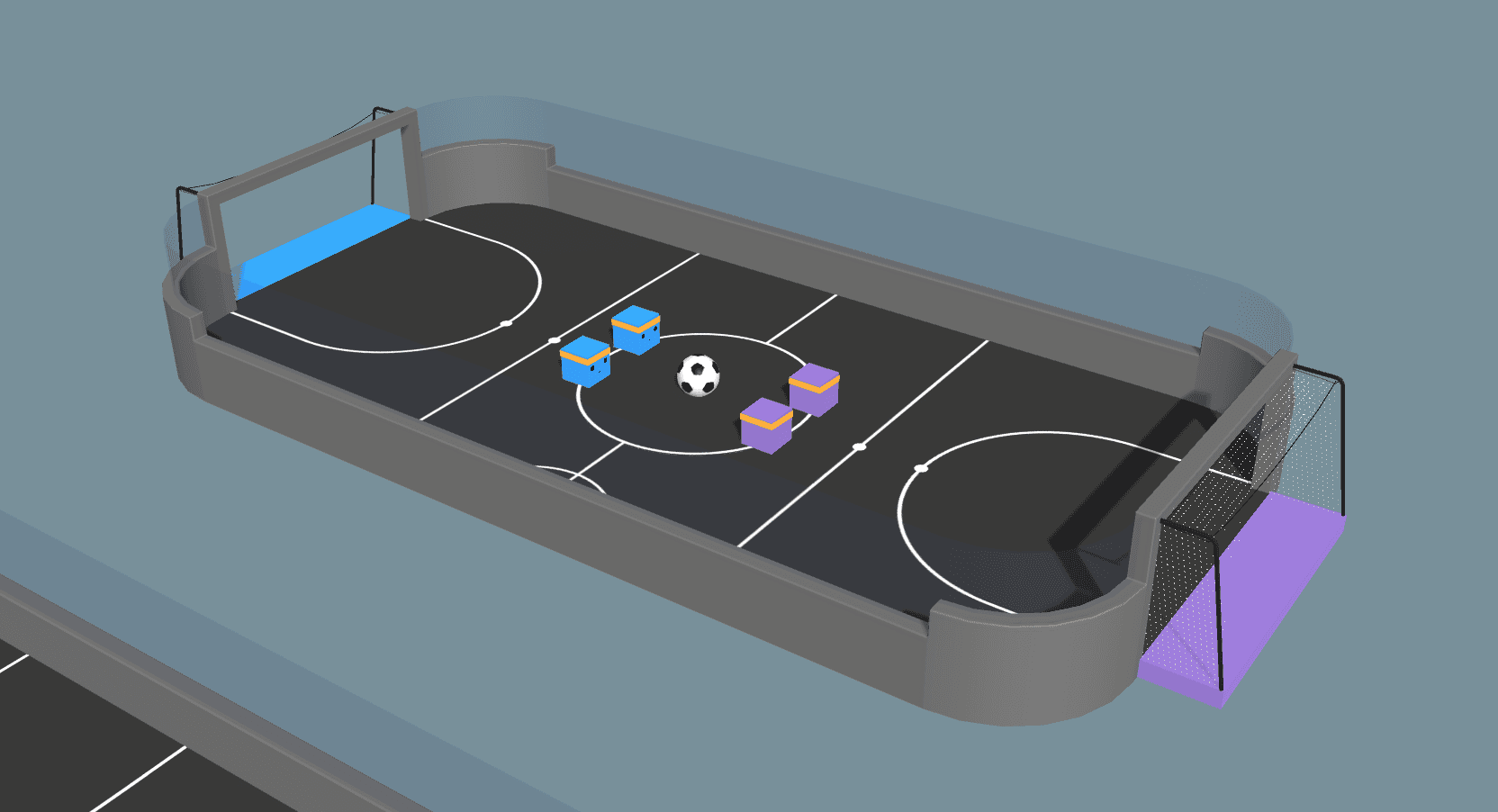
En las últimas versiones, no hemos incluido una política de agentes para nuestro entorno de ejemplo de Fútbol porque no se podía entrenar de forma fiable. Sin embargo, con la auto-reproducción y un poco de refactorización, ahora somos capaces de entrenar comportamientos de agentes no triviales. El cambio más significativo es la supresión de las "posiciones de jugador" de los agentes. Antes había un portero y un delantero explícitos, que utilizábamos para que la jugabilidad pareciera razonable. En el vídeo del nuevo entorno que se muestra a continuación, observamos cómo surgen comportamientos cooperativos similares a los del portero y el delantero. Ahora los agentes aprenden a tocar estas posiciones por sí solos. La función de recompensa para los cuatro agentes se define como +1,0 por marcar un gol y -1,0 por que te marquen, con una penalización adicional por tiempo de -0,0003 para animar a los agentes a marcar.
Destacamos el hecho de que el entrenamiento de los agentes en el entorno del Fútbol condujo a un comportamiento cooperativo sin un algoritmo multiagente explícito ni la asignación de roles. Este resultado demuestra que podemos entrenar comportamientos de agentes complicados con algoritmos sencillos siempre que tengamos cuidado al formular nuestro problema. La clave para conseguirlo es que los agentes puedan observar a sus compañeros de equipo, es decir, que reciban información sobre la posición relativa de sus compañeros en forma de observaciones. Al realizar una jugada agresiva hacia el balón, el agente comunica implícitamente a su compañero que debe retroceder en defensa. Alternativamente, al retroceder en defensa, indica a su compañero de equipo que puede avanzar en ataque. El vídeo de arriba muestra a los agentes captando estas señales y demostrando su posicionamiento ofensivo y defensivo en general.
La función de autojuego te permitirá entrenar nuevos e interesantes comportamientos adversarios en tu juego. Si utilizas la función de reproducción automática, cuéntanos qué tal te ha ido.
Si quieres trabajar en esta apasionante intersección de aprendizaje automático y juegos, estamos contratando para varios puestos, ¡presenta tu candidatura!
Si utiliza alguna de las funciones de esta versión, nos encantaría conocer su opinión. Si desea hacer algún comentario sobre Unity ML-Agents Toolkit, rellene la siguiente encuesta y envíenos un correo electrónico directamente. Si encuentra algún error, póngase en contacto con nosotros en la página de problemas de ML-Agents en GitHub. Para cualquier cuestión o pregunta de carácter general, póngase en contacto con nosotros en los foros de Unity ML-Agents.