Entraînement d'adversaires intelligents à l'aide de l'auto-jeu et d'agents ML


Dans la dernière version du ML-Agents Toolkit (v0.14), nous avons ajouté une fonction d'auto-apprentissage qui permet de former des agents compétitifs dans des jeux contradictoires (comme dans les jeux à somme nulle, où le gain d'un agent est exactement la perte de l'autre). Dans ce billet de blog, nous présentons une vue d'ensemble de l'auto-jeu et démontrons comment il permet une formation stable et efficace sur l'environnement de démonstration Soccer dans le ML-Agents Toolkit.
Les environnements d'exemple Tennis et Soccer de la boîte à outils Unity ML-Agents opposent des agents les uns aux autres en tant qu'adversaires. La formation d'agents dans ce type de scénario contradictoire peut s'avérer très difficile. En fait, dans les versions précédentes de la boîte à outils ML-Agents, la formation fiable d'agents dans ces environnements nécessitait une ingénierie de récompense importante. Dans la version 0.14, nous avons permis aux utilisateurs de former des agents dans des jeux via l'apprentissage par renforcement (RL) à partir de l'auto-jeu, un mécanisme fondamental pour un certain nombre des résultats les plus médiatisés en RL tels que OpenAI Five et DeepMind's AlphaStar. Le jeu du moi utilise les "moi" actuels et passés de l'agent comme adversaires. Il s'agit d'un adversaire qui s'améliore naturellement et contre lequel notre agent peut s'améliorer progressivement à l'aide d'algorithmes RL traditionnels. L'agent entièrement formé peut être utilisé comme compétition pour les joueurs humains avancés.
L'auto-jeu fournit un environnement d'apprentissage analogue à la façon dont les humains structurent la compétition. Par exemple, un humain qui apprend à jouer au tennis s'entraînera avec des adversaires de niveau similaire, car un adversaire trop fort ou trop faible n'est pas aussi propice à l'apprentissage du jeu. Du point de vue de l'amélioration des compétences, il serait beaucoup plus utile pour un joueur de tennis débutant de se mesurer à d'autres débutants qu'à un nouveau-né ou à Novak Djokovic, par exemple. Les premiers ne pouvaient pas renvoyer le ballon et les seconds ne voulaient pas leur servir un ballon qu'ils pouvaient renvoyer. Lorsque le débutant a atteint une force suffisante, il passe au niveau suivant du tournoi pour affronter des adversaires plus forts.
Dans ce billet de blog, nous donnons un aperçu technique de la dynamique de l'auto-jeu ainsi qu'une vue d'ensemble de nos environnements d'exemple pour le tennis et le football qui ont été remaniés pour présenter l'auto-jeu.
La notion d'auto-jeu a une longue histoire dans la pratique de la construction d'agents artificiels destinés à résoudre des problèmes et à rivaliser avec des humains dans des jeux. L'une des premières utilisations de ce mécanisme a été le système de jeu de dames d'Arthur Samuel, développé dans les années 50 et publié en 1959. Ce système a été le précurseur du résultat fondateur de RL, le TD-Gammon de Gerald Tesauro publié en 1995. TD-Gammon a utilisé l'algorithme d'apprentissage par différence temporelle TD(λ) avec l'auto-apprentissage pour former un agent de backgammon qui a presque rivalisé avec les experts humains. Dans certains cas, il a été observé que TD-Gammon avait une compréhension de la position supérieure à celle des joueurs de classe mondiale.
L'auto-jeu a joué un rôle déterminant dans un certain nombre de résultats historiques contemporains dans le domaine de la recherche scientifique. Il a notamment facilité l'apprentissage d'agents surhumains aux échecs et au jeu de go, d'agents d'élite de DOTA 2, ainsi que de stratégies et de contre-stratégies complexes dans des jeux tels que la lutte et le jeu de cache-cache. Dans les résultats utilisant l'auto-jeu, les chercheurs soulignent souvent que les agents découvrent des stratégies qui surprennent les experts humains.
L'auto-jeu dans les jeux confère aux agents une certaine créativité, indépendante de celle des programmeurs. L'agent ne reçoit que les règles du jeu et est informé des victoires et des défaites. A partir de ces premiers principes, c'est à l'agent de découvrir les comportements compétents. Selon le créateur de TD-Gammon, ce cadre d'apprentissage est libérateur "...dans le sens où le programme n'est pas entravé par des biais ou des préjugés humains qui peuvent être erronés ou peu fiables". Cette liberté a permis aux agents de découvrir des stratégies brillantes qui ont changé la façon dont les experts humains considèrent certains jeux.
Dans un problème traditionnel de NR, un agent tente d'apprendre une politique de comportement qui maximise une certaine récompense accumulée. Le signal de récompense codifie la tâche d'un agent, comme la navigation vers un état cible ou la collecte d'objets. Le comportement de l'agent est soumis aux contraintes de l'environnement. Par exemple, la gravité, la présence d'obstacles et l'influence relative des actions propres de l'agent, comme l'application d'une force pour se déplacer, sont autant de contraintes environnementales. Ceux-ci limitent les comportements viables de l'agent et constituent les forces environnementales avec lesquelles l'agent doit apprendre à composer pour obtenir une récompense élevée. En d'autres termes, l'agent s'oppose à la dynamique de l'environnement afin de pouvoir visiter les séquences d'états les plus gratifiantes.
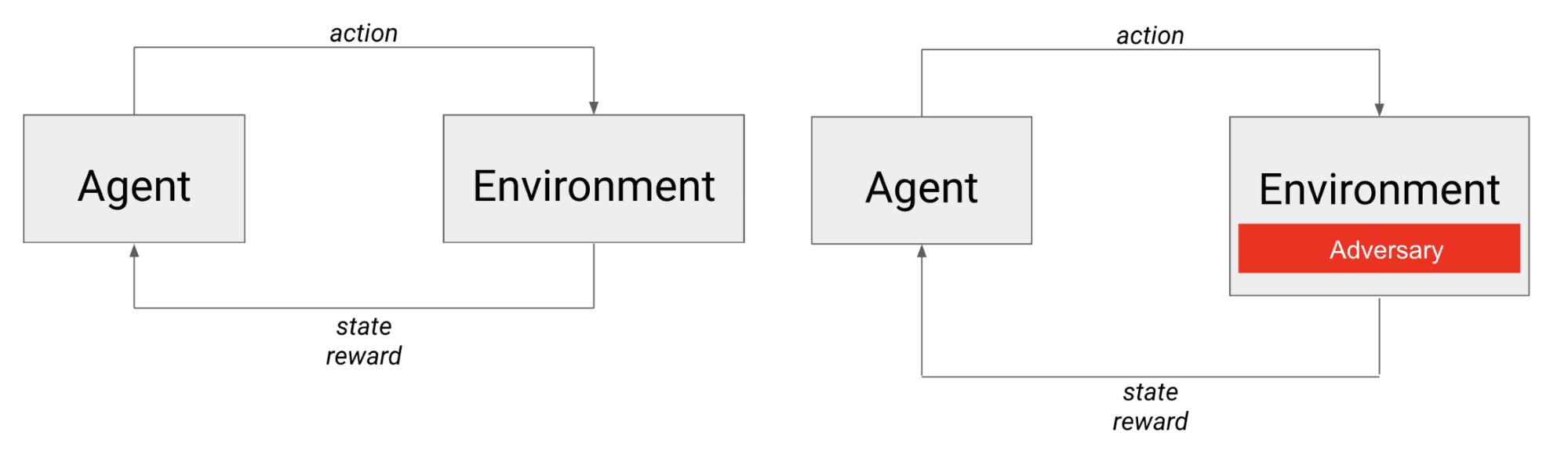
À gauche, le scénario typique de la logique des relations humaines : un agent agit dans l'environnement et reçoit l'état suivant et une récompense. À droite, le scénario d'apprentissage dans lequel l'agent est en concurrence avec un adversaire qui, du point de vue de l'agent, fait effectivement partie de l'environnement.
Dans le cas des jeux contradictoires, l'agent est confronté non seulement à la dynamique de l'environnement, mais aussi à un autre agent (éventuellement intelligent). On peut considérer que l'adversaire est intégré à l'environnement puisque ses actions influencent directement le prochain état observé par l'agent ainsi que la récompense qu'il reçoit.

Prenons la démonstration de ML-Agents Tennis. La raquette bleue (à gauche) est l'agent d'apprentissage et la raquette violette (à droite) est l'adversaire. Pour frapper la balle au-dessus du filet, l'agent doit tenir compte de la trajectoire de la balle entrante et ajuster son angle et sa vitesse en conséquence pour faire face à la gravité (l'environnement). Cependant, le fait de faire passer le ballon par-dessus le filet ne représente que la moitié de la bataille lorsqu'il y a un adversaire. Un adversaire puissant peut renvoyer un coup gagnant et faire perdre l'agent. Un adversaire faible peut frapper la balle dans le filet. Un adversaire égal peut renvoyer la balle et poursuivre ainsi le jeu. Dans tous les cas, l'état suivant et la récompense sont déterminés à la fois par l'environnement et par l'adversaire. Cependant, dans les trois cas, l'agent a tiré le même coup. L'apprentissage dans les jeux contradictoires et l'apprentissage des comportements compétitifs des agents sont donc des problèmes difficiles à résoudre.
Les considérations relatives à un adversaire approprié ne sont pas triviales. Comme le montre la discussion précédente, la force relative de l'adversaire a un impact significatif sur le résultat d'un match individuel. Si un adversaire est trop fort, il peut être trop difficile pour un agent partant de zéro de s'améliorer. D'autre part, si un adversaire est trop faible, un agent peut apprendre à gagner, mais le comportement appris peut ne pas être utile contre un adversaire différent ou plus fort. Par conséquent, nous avons besoin d'un adversaire dont le niveau de compétence est à peu près équivalent (difficile mais pas trop). En outre, comme notre agent s'améliore à chaque nouveau jeu, nous avons besoin d'une augmentation équivalente de l'adversaire.
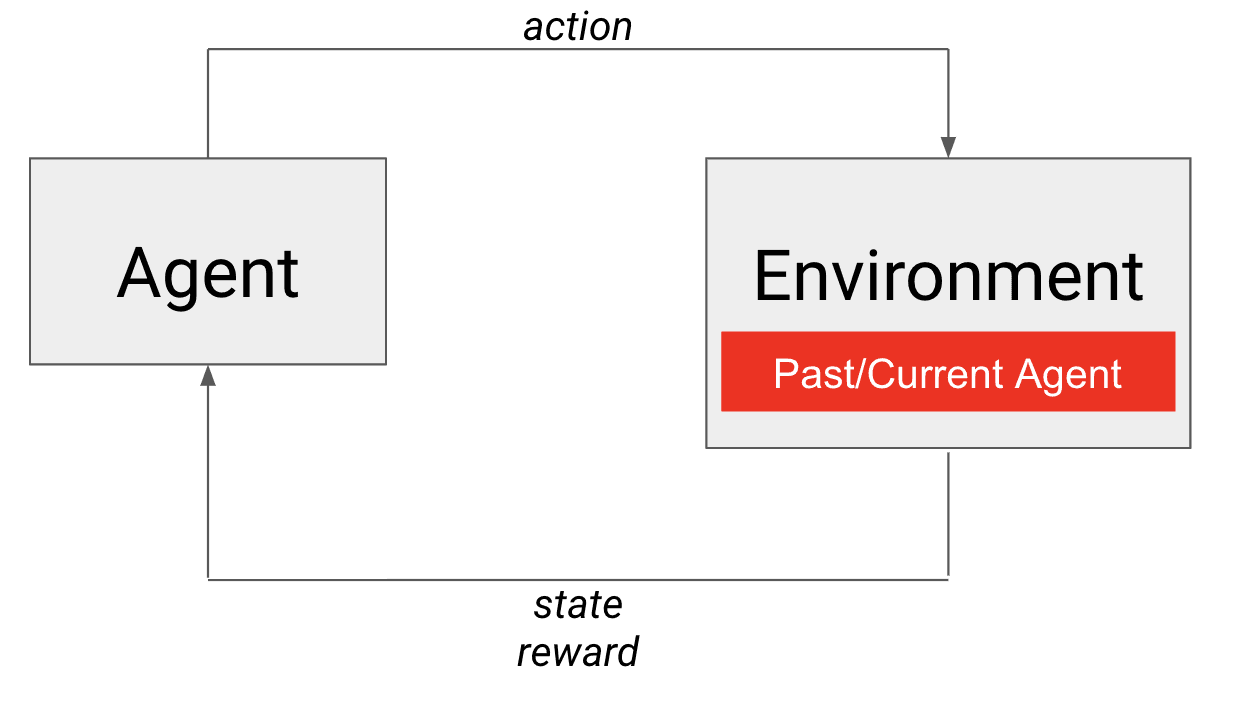
Dans l'auto-jeu, un instantané passé ou l'agent actuel est l'adversaire intégré dans l'environnement.
L'auto-jeu à la rescousse ! L'agent lui-même remplit les deux conditions pour être un bon adversaire. Il est certainement plus ou moins égal en compétences (à lui-même) et s'améliore également au fil du temps. Dans ce cas, c'est la politique de l'agent qui est intégrée dans l'environnement (voir figure). Pour ceux qui sont familiers avec l'apprentissage par programme, il s'agit d'un programme qui évolue naturellement (on parle aussi d'auto-curriculum) pour former notre agent contre des adversaires de plus en plus forts. Ainsi, l'auto-jeu nous permet d'amorcer un environnement pour former des agents compétitifs à des jeux contradictoires !
Dans les deux sous-sections suivantes, nous examinons des aspects plus techniques de la formation d'agents compétitifs, ainsi que certains détails concernant l'utilisation et la mise en œuvre de l'auto-jeu dans le ML-Agents Toolkit. Ces deux sous-sections peuvent être omises sans perdre de vue l'essentiel de ce billet de blog.
Le cadre de l'autodiscipline soulève certaines questions pratiques. Plus précisément, l'ajustement excessif pour vaincre un style de jeu particulier et l'instabilité du processus d'apprentissage qui peut résulter de la non-stationnarité de la fonction de transition (c'est-à-dire de l'évolution constante de l'adversaire). Le premier est un problème car nous voulons que nos agents soient des compétiteurs généraux et qu'ils soient capables de faire face à différents types d'adversaires. Pour illustrer ce dernier point, dans l'environnement du tennis, un adversaire différent renverra la balle à un angle et à une vitesse différents. Du point de vue de l'agent d'apprentissage, cela signifie que les mêmes décisions conduiront à des états suivants différents au fur et à mesure de la formation. Les algorithmes RL traditionnels supposent des fonctions de transition stationnaires. Malheureusement, en fournissant à l'agent un ensemble diversifié d'adversaires pour répondre au premier problème, nous risquons d'exacerber le second si nous n'y prenons pas garde.
Pour y remédier, nous conservons une mémoire tampon des politiques antérieures de l'agent, à partir de laquelle nous sélectionnons des adversaires contre lesquels l'apprenant est en concurrence pendant une période plus longue. En échantillonnant les politiques passées de l'agent, ce dernier verra un ensemble varié d'adversaires. En outre, le fait de laisser l'agent s'entraîner contre un adversaire fixe pendant une durée plus longue stabilise la fonction de transition et crée un environnement d'apprentissage plus cohérent. En outre, ces aspects algorithmiques peuvent être gérés à l'aide des hyperparamètres décrits dans la section suivante.
Dans le cas de la sélection d'hyperparamètres pour l'auto-apprentissage, la principale considération est le compromis entre le niveau de compétence et la généralité de la politique finale, et la stabilité de l'apprentissage. L'entraînement contre un ensemble d'adversaires qui changent lentement ou qui ne changent pas, avec une faible diversité, aboutit à un processus d'apprentissage plus stable que l'entraînement contre un ensemble d'adversaires qui changent rapidement et qui sont très diversifiés. Les hyperparamètres disponibles contrôlent la fréquence à laquelle la politique actuelle d'un agent est sauvegardée pour être utilisée ultérieurement comme adversaire échantillonné, la fréquence à laquelle un nouvel adversaire est échantillonné, le nombre d'adversaires sauvegardés et la probabilité de jouer contre le soi actuel de l'agent par rapport à un adversaire échantillonné dans le pool. Pour les directives d'utilisation des hyperparamètres de jeu automatique disponibles, veuillez consulter la documentation sur le jeu automatique dans le dépôt GitHub de ML-Agents.
Dans les jeux contradictoires, la récompense cumulative de l'environnement peut ne pas être une mesure significative pour suivre les progrès de l'apprentissage. En effet, la récompense cumulative dépend entièrement de l'habileté de l'adversaire. Un agent ayant un niveau de compétence particulier sera plus ou moins récompensé par rapport à un agent moins bon ou meilleur, respectivement. Nous proposons une implémentation du système d'évaluation ELO, une méthode de calcul du niveau de compétence relatif entre deux joueurs d'une population donnée dans un jeu à somme nulle. Au cours d'un entraînement donné, cette valeur doit augmenter régulièrement. Vous pouvez suivre cette évolution à l'aide de TensorBoard , ainsi que d'autres mesures d'entraînement, par exemple la récompense cumulée.
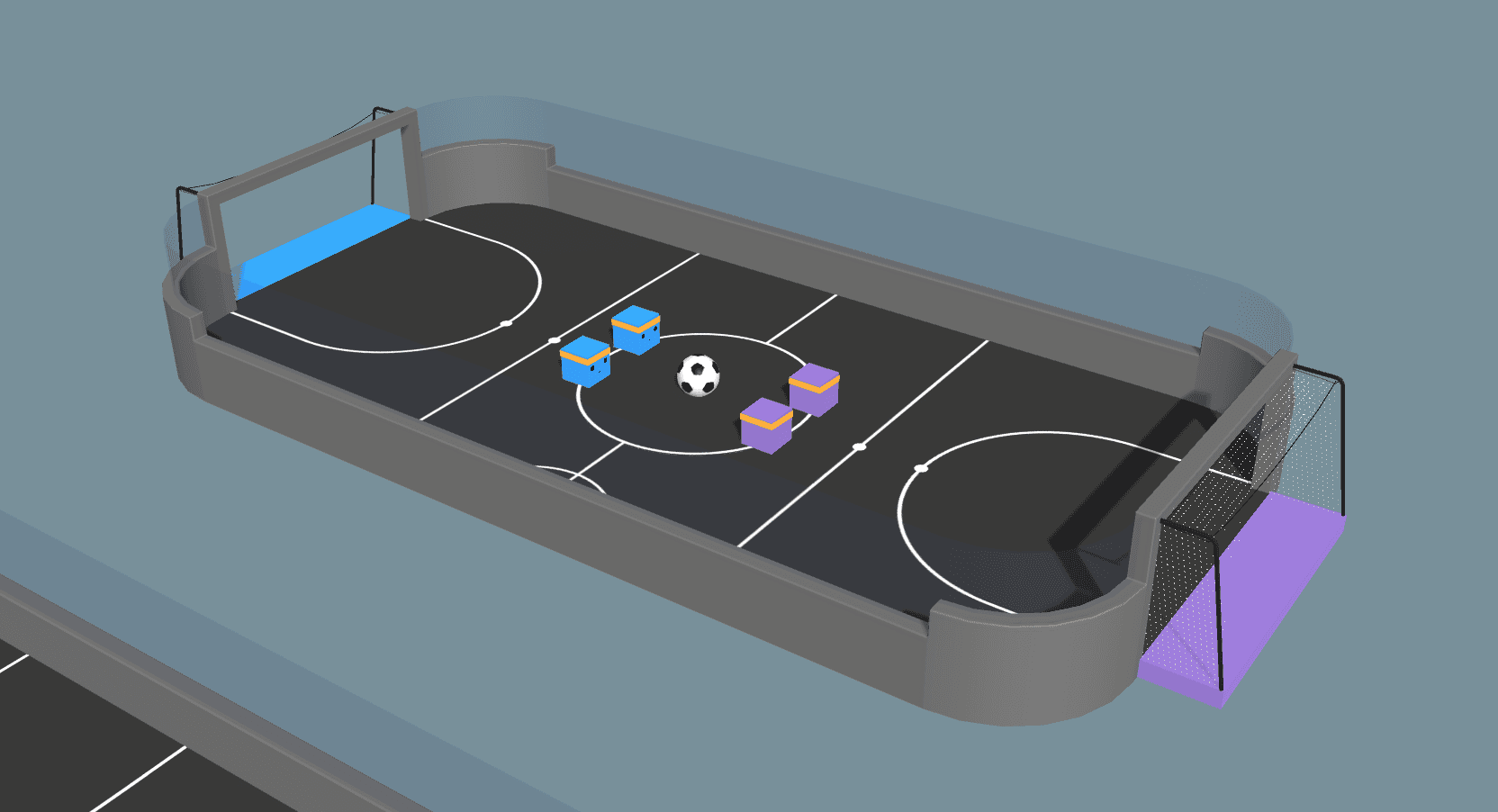
Dans les versions récentes, nous n'avons pas inclus de politique d'agent pour l'environnement de l'exemple de Soccer parce qu'il n'était pas possible de l'entraîner de manière fiable. Cependant, grâce à l'auto-jeu et à un certain remaniement, nous sommes maintenant en mesure de former des comportements d'agents non triviaux. Le changement le plus important est la suppression des "positions des joueurs" des agents. Auparavant, il y avait un gardien de but et un attaquant explicites, que nous utilisions pour que le jeu ait l'air raisonnable. Dans la vidéo ci-dessous du nouvel environnement, nous remarquons l'émergence d'un comportement coopératif de type rôle, selon les mêmes principes que ceux du gardien de but et de l'attaquant . Les agents apprennent maintenant à jouer ces positions par eux-mêmes ! La fonction de récompense pour les quatre agents est définie comme suit : +1,0 pour marquer un but et -1,0 pour se faire marquer, avec une pénalité supplémentaire de -0,0003 par pas de temps pour encourager les agents à marquer.
Nous insistons sur le fait que la formation des agents dans l'environnement du Soccer a conduit à un comportement coopératif sans algorithme multi-agents explicite ni attribution de rôles. Ce résultat montre qu'il est possible de former des comportements d'agents complexes à l'aide d'algorithmes simples, à condition de prendre soin de la formulation de notre problème. Pour ce faire, les agents peuvent observer leurs coéquipiers, c'est-à-dire qu'ils reçoivent des informations sur la position relative de leurs coéquipiers sous forme d'observations. En jouant agressivement le ballon, l'agent communique implicitement à son coéquipier qu'il doit se replier en défense. Par ailleurs, en se repliant sur la défense, il signale à son coéquipier qu'il peut passer à l'attaque. La vidéo ci-dessus montre les agents en train de repérer ces signaux et de démontrer le positionnement offensif et défensif général !
La fonction d'auto-jeu vous permettra d'entraîner de nouveaux comportements adverses intéressants dans votre jeu. Si vous utilisez la fonction d'auto-jeu, n'hésitez pas à nous en faire part !
Si vous souhaitez travailler à cette intersection passionnante de l'apprentissage automatique et des jeux, nous recrutons pour plusieurs postes, n'hésitez pas à postuler!
Si vous utilisez l'une ou l'autre des fonctionnalités proposées dans cette version, nous serions ravis de connaître votre avis. Pour tout commentaire concernant la boîte à outils Unity ML-Agents, veuillez remplir le questionnaire suivant et n'hésitez pas à nous envoyer un courriel directement. Si vous rencontrez des bugs, merci de nous contacter sur la page ML-Agents GitHub issues. Pour toute question d'ordre général, n'hésitez pas à nous contacter sur les forums Unity ML-Agents.