Training von intelligenten Gegnern durch Selbstspiel mit ML-Agenten


In der neuesten Version des ML-Agents Toolkit (v0.14) haben wir eine Selbstspielfunktion hinzugefügt, die es ermöglicht, konkurrierende Agenten in kontradiktorischen Spielen zu trainieren (wie in Nullsummenspielen, bei denen der Gewinn des einen Agenten genau dem Verlust des anderen Agenten entspricht). In diesem Blogbeitrag geben wir einen Überblick über Self-Play und demonstrieren, wie es ein stabiles und effektives Training in der Soccer-Demo-Umgebung des ML-Agents Toolkit ermöglicht.
In den Beispielumgebungen Tennis und Fußball des Unity ML-Agents Toolkit treten Agenten als Gegner gegeneinander an. Die Ausbildung von Agenten in dieser Art von gegnerischem Szenario kann eine große Herausforderung darstellen. In früheren Versionen des ML-Agents Toolkit erforderte das zuverlässige Training von Agenten in diesen Umgebungen ein erhebliches Reward Engineering. In der Version 0.14 haben wir es den Nutzern ermöglicht, Agenten in Spielen mittels Reinforcement Learning (RL) aus dem Selbstspiel zu trainieren, ein Mechanismus, der für eine Reihe der bekanntesten RL-Ergebnisse wie OpenAI Five und DeepMinds AlphaStar grundlegend ist. Beim Selbstspiel werden das aktuelle und das frühere "Ich" des Akteurs als Gegner eingesetzt. So entsteht ein sich natürlich verbessernder Gegner, gegen den sich unser Agent mit herkömmlichen RL-Algorithmen schrittweise verbessern kann. Der vollständig ausgebildete Agent kann als Konkurrenz für fortgeschrittene menschliche Spieler eingesetzt werden.
Das Selbstspiel bietet ein Lernumfeld, das der menschlichen Wettbewerbsstruktur entspricht. Ein Mensch, der das Tennisspielen erlernt, würde beispielsweise gegen Gegner mit ähnlichem Leistungsniveau trainieren, da ein zu starker oder zu schwacher Gegner dem Erlernen des Spiels nicht förderlich ist. Unter dem Gesichtspunkt der Verbesserung der eigenen Fähigkeiten wäre es für einen Tennisspieler auf Anfängerniveau viel wertvoller, sich mit anderen Anfängern zu messen als beispielsweise mit einem Neugeborenen oder Novak Djokovic. Die einen konnten den Ball nicht zurückspielen, und die anderen wollten ihnen keinen Ball zuspielen, den sie zurückspielen konnten. Wenn der Anfänger eine ausreichende Stärke erreicht hat, wechselt er in die nächste Stufe des Turniers, um sich mit stärkeren Gegnern zu messen.
In diesem Blog-Beitrag geben wir einen technischen Einblick in die Dynamik des Selbstspiels und geben einen Überblick über unsere Tennis- und Fußball-Beispielumgebungen, die überarbeitet wurden, um das Selbstspiel zu präsentieren.
Der Begriff des Selbstspiels hat eine lange Tradition in der Praxis der Entwicklung künstlicher Agenten, die Spiele lösen und mit Menschen konkurrieren. Eine der frühesten Anwendungen dieses Mechanismus war Arthur Samuels Schachspielsystem, das in den 50er Jahren entwickelt und 1959 veröffentlicht wurde. Dieses System war ein Vorläufer des bahnbrechenden Ergebnisses in RL, Gerald Tesauros TD-Gammon aus dem Jahr 1995. TD-Gammon nutzte den Algorithmus TD(λ) für zeitliches Differenzlernen mit Selbstspiel, um einen Backgammon-Agenten zu trainieren, der es fast mit menschlichen Experten aufnehmen konnte. In einigen Fällen wurde beobachtet, dass TD-Gammon ein besseres Positionsverständnis als Weltklassespieler hatte.
Das Selbstspiel hat zu einer Reihe von wegweisenden Ergebnissen in der RL beigetragen. Sie ermöglichte insbesondere das Erlernen von übermenschlichen Schach- und Go-Agenten, von Elite-Agenten in DOTA 2 sowie von komplexen Strategien und Gegenstrategien in Spielen wie Ringen und Verstecken. Bei Ergebnissen, die auf Selbstspiel beruhen, weisen die Forscher häufig darauf hin, dass die Agenten Strategien entdecken, die menschliche Experten überraschen.
Das Selbstspiel in Spielen verleiht den Agenten eine gewisse Kreativität, die unabhängig von der des Programmierers ist. Dem Agenten werden nur die Spielregeln mitgeteilt und er erfährt, wann er gewinnt oder verliert. Ausgehend von diesen ersten Prinzipien ist es Aufgabe des Agenten, kompetentes Verhalten zu entdecken. In den Worten des Schöpfers von TD-Gammon ist dieser Rahmen für das Lernen befreiend "...in dem Sinne, dass das Programm nicht durch menschliche Voreingenommenheit oder Vorurteile behindert wird, die fehlerhaft oder unzuverlässig sein können." Diese Freiheit hat Agenten dazu gebracht, brillante Strategien zu entwickeln, die die Sichtweise menschlicher Experten auf bestimmte Spiele verändert haben.
Bei einem traditionellen RL-Problem versucht ein Agent, eine Verhaltenspolitik zu erlernen, die eine bestimmte kumulierte Belohnung maximiert. Das Belohnungssignal kodiert die Aufgabe des Agenten, z. B. das Navigieren zu einem Zielzustand oder das Sammeln von Gegenständen. Das Verhalten des Agenten unterliegt den Zwängen der Umwelt. So sind zum Beispiel die Schwerkraft, das Vorhandensein von Hindernissen und der relative Einfluss, den die eigenen Aktionen des Agenten haben, wie die Anwendung von Kraft, um sich selbst zu bewegen, alles Umweltbedingungen. Diese schränken die möglichen Verhaltensweisen des Agenten ein und sind die Umweltkräfte, mit denen der Agent lernen muss umzugehen, um eine hohe Belohnung zu erhalten. Das heißt, der Agent setzt sich mit der Dynamik der Umwelt auseinander, um die lohnendsten Zustandsfolgen zu besuchen.
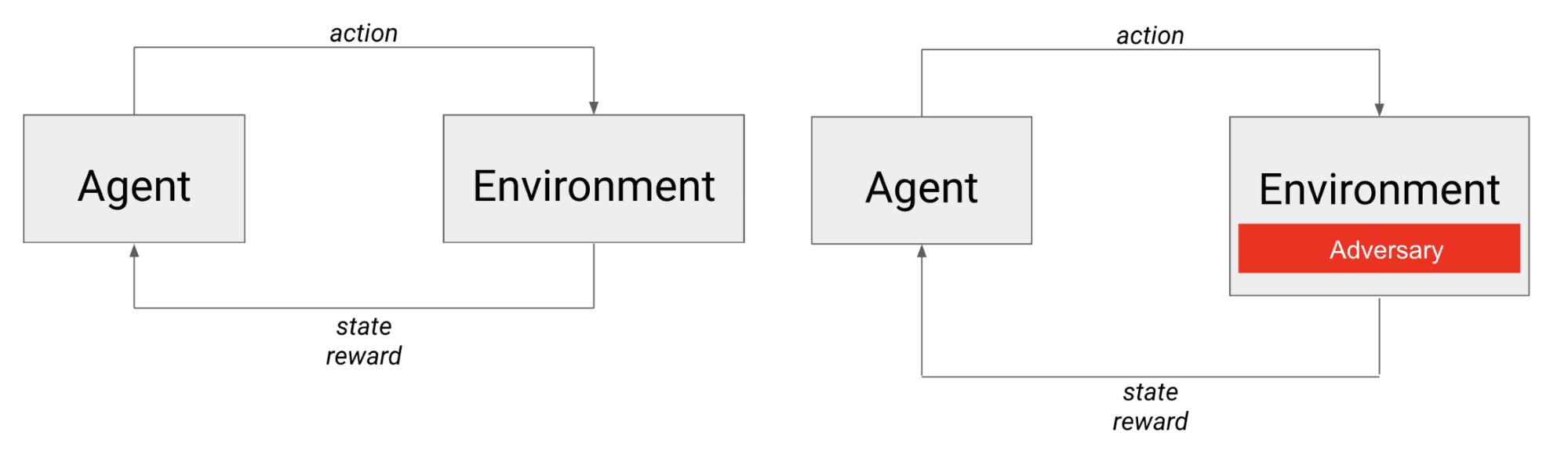
Links ist das typische RL-Szenario: Ein Agent handelt in der Umwelt und erhält den nächsten Zustand und eine Belohnung. Rechts ist das Lernszenario, in dem der Agent mit einem Gegner konkurriert, der aus der Sicht des Agenten effektiv Teil der Umwelt ist.
Bei gegnerischen Spielen konkurriert der Agent nicht nur mit der Dynamik der Umwelt, sondern auch mit einem anderen (möglicherweise intelligenten) Agenten. Man kann sich den Gegner als in die Umgebung eingebettet vorstellen, da seine Aktionen den nächsten Zustand, den der Agent beobachtet, sowie die Belohnung, die er erhält, direkt beeinflussen.

Schauen wir uns die ML-Agents Tennis-Demo an. Der blaue Schläger (links) ist der lernende Agent und der lila Schläger (rechts) ist der Gegner. Um den Ball über das Netz zu schlagen, muss der Agent die Flugbahn des ankommenden Balls berücksichtigen und seinen Winkel und seine Geschwindigkeit entsprechend anpassen, um der Schwerkraft (der Umgebung) zu trotzen. Den Ball über das Netz zu bringen, ist jedoch nur die halbe Miete, wenn es einen Gegenspieler gibt. Ein starker Gegner kann einen Gewinnschuss zurückgeben, wodurch der Agent verliert. Ein schwacher Gegenspieler kann den Ball ins Netz schlagen. Ein gleichwertiger Gegner kann den Ball zurückspielen und das Spiel fortsetzen. In jedem Fall werden der nächste Zustand und die nächste Belohnung sowohl von der Umgebung als auch vom Gegner bestimmt. In allen drei Situationen traf der Agent jedoch denselben Schuss. Dies macht das Lernen in kontradiktorischen Spielen und das Trainieren von wettbewerbsfähigem Agentenverhalten zu einem schwierigen Problem.
Die Überlegungen rund um einen geeigneten Gegner sind nicht trivial. Wie die vorangegangene Diskussion gezeigt hat, hat die relative Stärke des Gegners einen erheblichen Einfluss auf den Ausgang eines einzelnen Spiels. Wenn ein Gegner zu stark ist, kann es für einen Agenten, der bei Null anfängt, zu schwierig sein, sich zu verbessern. Ist der Gegner hingegen zu schwach, kann ein Agent zwar lernen zu gewinnen, aber das erlernte Verhalten ist möglicherweise gegen einen anderen oder stärkeren Gegner nicht von Nutzen. Deshalb brauchen wir einen Gegner, der in etwa gleich gut ist (anspruchsvoll, aber nicht zu anspruchsvoll). Da unser Agent mit jedem neuen Spiel besser wird, brauchen wir auch eine entsprechende Steigerung des Gegners.
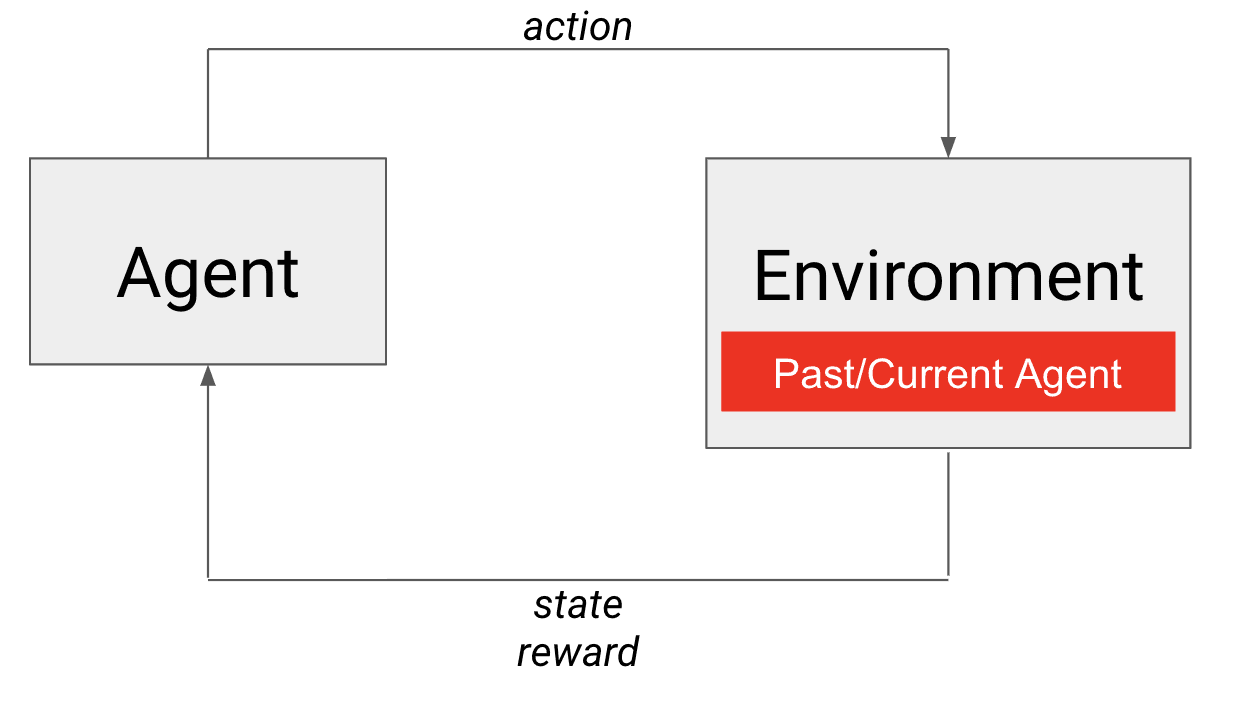
Beim Selbstspiel ist ein vergangener Schnappschuss oder der aktuelle Agent der in die Umgebung eingebettete Gegenspieler.
Selbstspiel zur Rettung! Der Agent selbst erfüllt beide Anforderungen an einen geeigneten Gegner. Es ist sicherlich ungefähr gleichwertig (mit sich selbst) und verbessert sich auch mit der Zeit. In diesem Fall ist es die eigene Politik des Agenten, die in die Umgebung eingebettet ist (siehe Abbildung). Für diejenigen, die mit Lehrplänen vertraut sind, kann man sich dies als einen sich natürlich entwickelnden (auch als Autocurriculum bezeichneten) Lehrplan für das Training unseres Agenten gegen immer stärkere Gegner vorstellen. Das Selbstspiel ermöglicht es uns also, eine Umgebung zu schaffen, in der wir wettbewerbsfähige Agenten für kontradiktorische Spiele trainieren können!
In den folgenden zwei Unterabschnitten betrachten wir mehr technische Aspekte des Trainings wettbewerbsfähiger Agenten sowie einige Details zur Verwendung und Implementierung des Selbstspiels im ML-Agents Toolkit. Diese beiden Unterabschnitte können übersprungen werden, ohne dass das Hauptthema dieses Blogbeitrags verloren geht.
Einige praktische Fragen ergeben sich aus dem Rahmen des Selbstspiels. Insbesondere die Überanpassung an einen bestimmten Spielstil und die Instabilität des Trainingsprozesses, die durch die Nicht-Stationarität der Übergangsfunktion (d. h. den sich ständig verändernden Gegner) entstehen kann. Ersteres ist ein Problem, weil wir wollen, dass unsere Agenten allgemeine Konkurrenten sind und gegen verschiedene Arten von Gegnern bestehen können. Zur Veranschaulichung: Beim Tennis wird ein anderer Gegner den Ball in einem anderen Winkel und mit anderer Geschwindigkeit zurückspielen. Aus der Sicht des lernenden Agenten bedeutet dies, dass dieselben Entscheidungen im Laufe des Trainings zu unterschiedlichen nächsten Zuständen führen werden. Traditionelle RL-Algorithmen gehen von stationären Übergangsfunktionen aus. Indem wir dem Agenten eine Vielzahl von Gegnern zur Verfügung stellen, um die erstgenannten Probleme zu lösen, können wir die letzteren leider noch verschärfen, wenn wir nicht vorsichtig sind.
Um dieses Problem zu lösen, halten wir einen Puffer mit den vergangenen Strategien des Agenten vor, aus dem wir eine Auswahl von Gegnern treffen, gegen die der Lernende über einen längeren Zeitraum antritt. Durch Stichproben aus den bisherigen Strategien des Agenten wird dieser eine Vielzahl von Gegnern sehen. Wenn man den Agenten über einen längeren Zeitraum gegen einen festen Gegner trainieren lässt, stabilisiert sich die Übergangsfunktion und es entsteht eine konsistentere Lernumgebung. Zusätzlich können diese algorithmischen Aspekte mit den im nächsten Abschnitt erörterten Hyperparametern gesteuert werden.
Bei der Auswahl von Hyperparametern für das Selbstspiel geht es in erster Linie um einen Kompromiss zwischen dem Fähigkeitsniveau und der Allgemeinheit der endgültigen Strategie und der Stabilität des Lernens. Das Training gegen eine Gruppe von sich langsam verändernden oder unveränderlichen Gegnern mit geringer Diversität führt zu einem stabileren Lernprozess als das Training gegen eine Gruppe von sich schnell verändernden Gegnern mit hoher Diversität. Die verfügbaren Hyperparameter steuern, wie oft die aktuelle Strategie eines Agenten gespeichert wird, um später als gesampelter Gegner verwendet zu werden, wie oft ein neuer Gegner gesampelt wird, die Anzahl der gespeicherten Gegner und die Wahrscheinlichkeit, gegen das aktuelle Selbst des Agenten und einen aus dem Pool gesampelten Gegner zu spielen. Richtlinien zur Verwendung der verfügbaren Selfplay-Hyperparameter finden Sie in der Selfplay-Dokumentation im ML-Agents GitHub-Repository.
In kontradiktorischen Spielen ist die kumulative Belohnung der Umgebung möglicherweise kein sinnvoller Maßstab, um den Lernfortschritt zu verfolgen. Der Grund dafür ist, dass die kumulative Belohnung vollständig von den Fähigkeiten des Gegners abhängt. Ein Agent mit einem bestimmten Qualifikationsniveau erhält mehr oder weniger Belohnung als ein schlechterer bzw. besserer Agent. Wir bieten eine Implementierung des ELO-Bewertungssystems, einer Methode zur Berechnung des relativen Fähigkeitsniveaus zwischen zwei Spielern aus einer bestimmten Population in einem Nullsummenspiel. In einem bestimmten Trainingslauf sollte dieser Wert stetig ansteigen. Sie können dies mit TensorBoard zusammen mit anderen Trainingsmetriken, z.B. der kumulativen Belohnung, verfolgen.
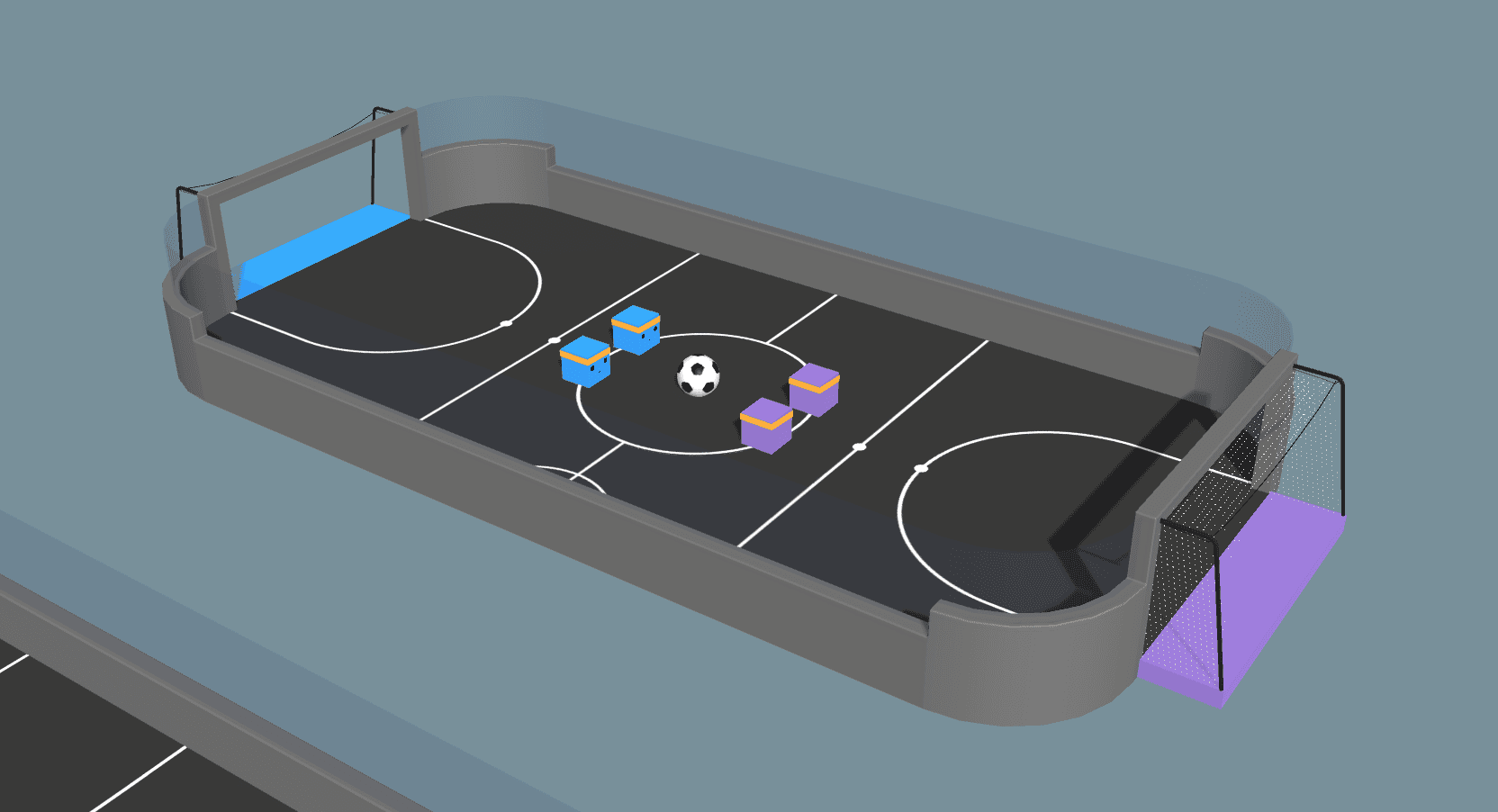
In den letzten Versionen haben wir keine Agentenrichtlinie für unsere Fußball-Beispielumgebung aufgenommen, da sie nicht zuverlässig trainiert werden konnte. Mit Self-Play und einigen Überarbeitungen sind wir nun jedoch in der Lage, nicht-triviale Verhaltensweisen von Agenten zu trainieren. Die wichtigste Änderung ist die Streichung der "Spielerpositionen" aus den Agenten. Zuvor gab es einen expliziten Torwart und einen Stürmer, die wir benutzt haben, um das Gameplay vernünftig aussehen zu lassen. In dem unten stehenden Video aus der neuen Umgebung können wir tatsächlich beobachten, dass ein rollenähnliches, kooperatives Verhalten nach dem Vorbild von Torwart und Stürmer auftritt. Jetzt lernen die Agenten, diese Positionen selbständig zu spielen! Die Belohnungsfunktion für alle vier Agenten ist definiert als +1,0 für das Erzielen eines Tores und -1,0 für das Erzielen eines Tores mit einer zusätzlichen Strafe von -0,0003 pro Zeitschritt, um die Agenten zu ermutigen, ein Tor zu erzielen.
Wir betonen, dass das Training der Agenten in der Soccer-Umgebung zu kooperativem Verhalten führte, ohne dass ein expliziter Multi-Agenten-Algorithmus oder die Zuweisung von Rollen erforderlich war. Dieses Ergebnis zeigt, dass wir kompliziertes Agentenverhalten mit einfachen Algorithmen trainieren können, solange wir bei der Formulierung unseres Problems sorgfältig vorgehen. Der Schlüssel dazu ist, dass Agenten ihre Teamkollegen beobachten können, d.h. sie erhalten Informationen über die relative Position ihrer Teamkollegen als Beobachtungen. Indem er aggressiv auf den Ball zugeht, teilt er seinem Teamkollegen implizit mit, dass er sich in der Verteidigung zurückfallen lassen soll. Indem er sich in der Verteidigung zurückfallen lässt, signalisiert er seinem Teamkollegen, dass er in der Offensive vorrücken kann. Das obige Video zeigt, wie die Agenten diese Hinweise aufgreifen und die allgemeine offensive und defensive Positionierung demonstrieren!
Die Selbstspielfunktion ermöglicht es Ihnen, neue und interessante gegnerische Verhaltensweisen in Ihrem Spiel zu trainieren. Wenn Sie die Selbstspielfunktion nutzen, lassen Sie uns bitte wissen, wie es funktioniert!
Wenn Sie an dieser aufregenden Schnittstelle zwischen maschinellem Lernen und Spielen arbeiten möchten, stellen wir mehrere Stellen ein, bitte bewerben Sie sich!
Wenn Sie eine der Funktionen in dieser Version nutzen, würden wir uns freuen, von Ihnen zu hören. Wenn Sie uns Ihr Feedback zum Unity ML-Agents Toolkit geben möchten, füllen Sie bitte die folgende Umfrage aus und schicken Sie uns direkt eine E-Mail. Wenn Sie auf Fehler stoßen, wenden Sie sich bitte an uns auf der GitHub-Themenseite von ML-Agents. Bei allgemeinen Problemen und Fragen wenden Sie sich bitte an uns in den Unity ML-Agents Foren.