Treinamento de adversários inteligentes usando a reprodução automática com agentes de ML


Na versão mais recente do ML-Agents Toolkit (v0.14), adicionamos um recurso de autojogo que oferece a capacidade de treinar agentes competitivos em jogos adversários (como em jogos de soma zero, em que o ganho de um agente é exatamente a perda do outro agente). Nesta postagem do blog, apresentamos uma visão geral da reprodução automática e demonstramos como ela permite um treinamento estável e eficaz no ambiente de demonstração do Soccer no ML-Agents Toolkit.
Os ambientes de exemplo Tennis e Soccer do Unity ML-Agents Toolkit colocam os agentes uns contra os outros como adversários. O treinamento de agentes nesse tipo de cenário adverso pode ser bastante desafiador. De fato, em versões anteriores do ML-Agents Toolkit, o treinamento confiável de agentes nesses ambientes exigia uma engenharia de recompensa significativa. Na versão 0.14, permitimos que os usuários treinem agentes em jogos por meio da aprendizagem por reforço (RL) a partir do jogo próprio, um mecanismo fundamental para vários dos resultados mais importantes em RL, como o OpenAI Five e o AlphaStar da DeepMind. O jogo de si mesmo usa os "eus" atuais e passados do agente como oponentes. Isso proporciona um adversário que melhora naturalmente, contra o qual nosso agente pode melhorar gradualmente usando os algoritmos tradicionais de RL. O agente totalmente treinado pode ser usado como competição para jogadores humanos avançados.
O jogo autônomo proporciona um ambiente de aprendizado análogo ao modo como os seres humanos estruturam a competição. Por exemplo, um ser humano que está aprendendo a jogar tênis treinaria com adversários de nível de habilidade semelhante, pois um adversário muito forte ou muito fraco não é tão propício para aprender o jogo. Do ponto de vista do aprimoramento das habilidades, seria muito mais valioso para um jogador de tênis iniciante competir contra outros iniciantes do que, por exemplo, contra uma criança recém-nascida ou Novak Djokovic. Os primeiros não podiam devolver a bola, e os segundos não lhes serviam uma bola que pudessem devolver. Quando o iniciante tiver alcançado força suficiente, ele passará para o próximo nível de torneio para competir com adversários mais fortes.
Nesta postagem do blog, apresentamos alguns insights técnicos sobre a dinâmica da reprodução automática, além de fornecer uma visão geral dos nossos ambientes de exemplo de tênis e futebol que foram refatorados para mostrar a reprodução automática.
A noção de jogo autônomo tem uma longa história na prática de criar agentes artificiais para resolver e competir com humanos em jogos. Um dos primeiros usos desse mecanismo foi o sistema de jogo de damas de Arthur Samuel, desenvolvido nos anos 50 e publicado em 1959. Esse sistema foi um precursor do resultado seminal em RL, o TD-Gammon de Gerald Tesauro , publicado em 1995. O TD-Gammon usou o algoritmo de aprendizado de diferença temporal TD(λ) com auto-jogo para treinar um agente de gamão que quase rivalizou com especialistas humanos. Em alguns casos, observou-se que o TD-Gammon tinha uma compreensão posicional superior à dos jogadores de classe mundial.
O jogo autônomo tem sido fundamental em vários resultados marcantes contemporâneos em RL. Em especial, facilitou o aprendizado de agentes super-humanos de xadrez e Go, agentes de elite do DOTA 2, bem como estratégias complexas e contraestratégias em jogos como luta livre e esconde-esconde. Nos resultados que utilizam o jogo autônomo, os pesquisadores geralmente apontam que os agentes descobrem estratégias que surpreendem os especialistas humanos.
O jogo autônomo em jogos confere aos agentes uma certa criatividade, independente da dos programadores. O agente recebe apenas as regras do jogo e é informado quando ganha ou perde. A partir desses primeiros princípios, cabe ao agente descobrir o comportamento competente. Nas palavras do criador do TD-Gammon, essa estrutura de aprendizado é libertadora "... no sentido de que o programa não é prejudicado por preconceitos humanos que podem ser errôneos ou não confiáveis". Essa liberdade levou os agentes a descobrir estratégias brilhantes que mudaram a forma como os especialistas humanos veem determinados jogos.
Em um problema tradicional de RL, um agente tenta aprender uma política de comportamento que maximiza alguma recompensa acumulada. O sinal de recompensa codifica a tarefa de um agente, como navegar até um estado de meta ou coletar itens. O comportamento do agente está sujeito às restrições do ambiente. Por exemplo, a gravidade, a presença de obstáculos e a influência relativa que as próprias ações do agente têm, como aplicar força para se mover, são todas restrições ambientais. Elas limitam os comportamentos viáveis do agente e são as forças ambientais com as quais o agente deve aprender a lidar para obter uma alta recompensa. Ou seja, o agente luta com a dinâmica do ambiente para que possa visitar as sequências de estados mais gratificantes.
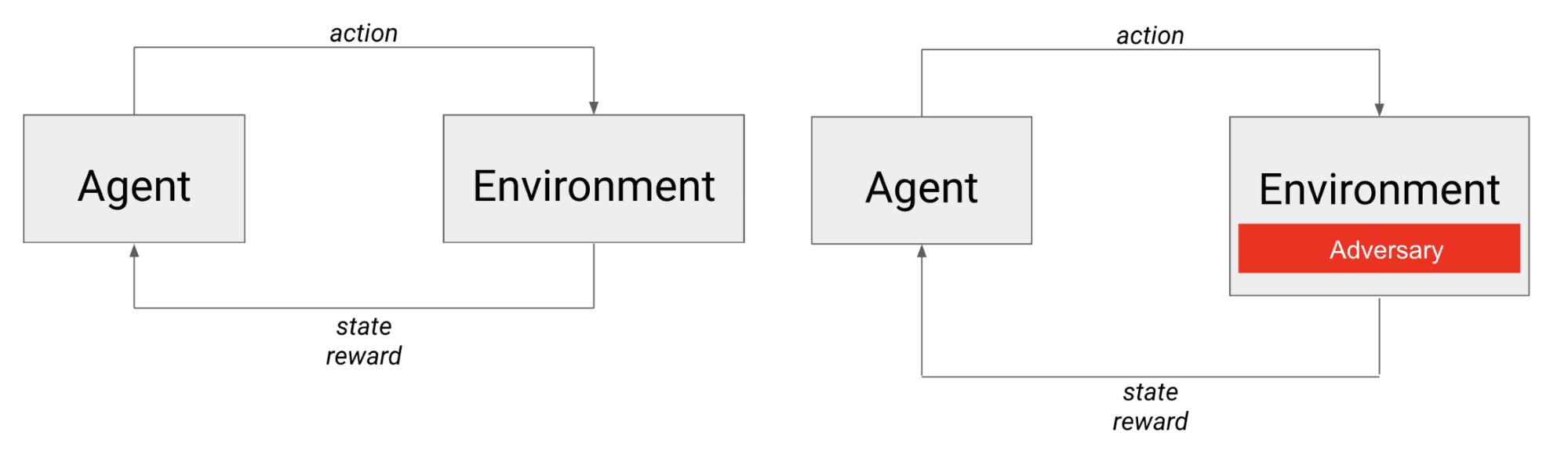
À esquerda está o cenário típico de RL: um agente age no ambiente e recebe o próximo estado e uma recompensa. À direita está o cenário de aprendizado em que o agente compete com um adversário que, da perspectiva do agente, é efetivamente parte do ambiente.
No caso de jogos contraditórios, o agente não só luta contra a dinâmica do ambiente, mas também contra outro agente (possivelmente inteligente). Você pode pensar no adversário como sendo incorporado ao ambiente, pois suas ações influenciam diretamente o próximo estado que o agente observa, bem como a recompensa que ele recebe.

Vamos considerar a demonstração do ML-Agents Tennis. A raquete azul (esquerda) é o agente de aprendizado, e a raquete roxa (direita) é o adversário. Para acertar a bola na rede, o agente deve considerar a trajetória da bola que está entrando e ajustar seu ângulo e velocidade de acordo com a gravidade (o ambiente). No entanto, colocar a bola na rede é apenas metade da batalha quando há um adversário. Um adversário forte pode devolver uma tacada vencedora, fazendo com que o agente perca. Um adversário fraco pode acertar a bola na rede. Um adversário igual pode devolver a bola e, assim, continuar o jogo. Em qualquer caso, o próximo estado e a recompensa são determinados pelo ambiente e pelo adversário. No entanto, em todas as três situações, o agente acertou o mesmo chute. Isso torna o aprendizado em jogos adversários e o treinamento de comportamentos competitivos de agentes um problema difícil.
As considerações sobre um oponente adequado não são triviais. Conforme demonstrado na discussão anterior, a força relativa do oponente tem um impacto significativo no resultado de um jogo individual. Se um oponente for muito forte, pode ser muito difícil para um agente que está começando do zero melhorar. Por outro lado, se um oponente for muito fraco, um agente pode aprender a vencer, mas o comportamento aprendido pode não ser útil contra um oponente diferente ou mais forte. Portanto, precisamos de um oponente que seja mais ou menos igual em termos de habilidade (desafiador, mas não muito desafiador). Além disso, como nosso agente está melhorando a cada novo jogo, precisamos de um aumento equivalente no oponente.
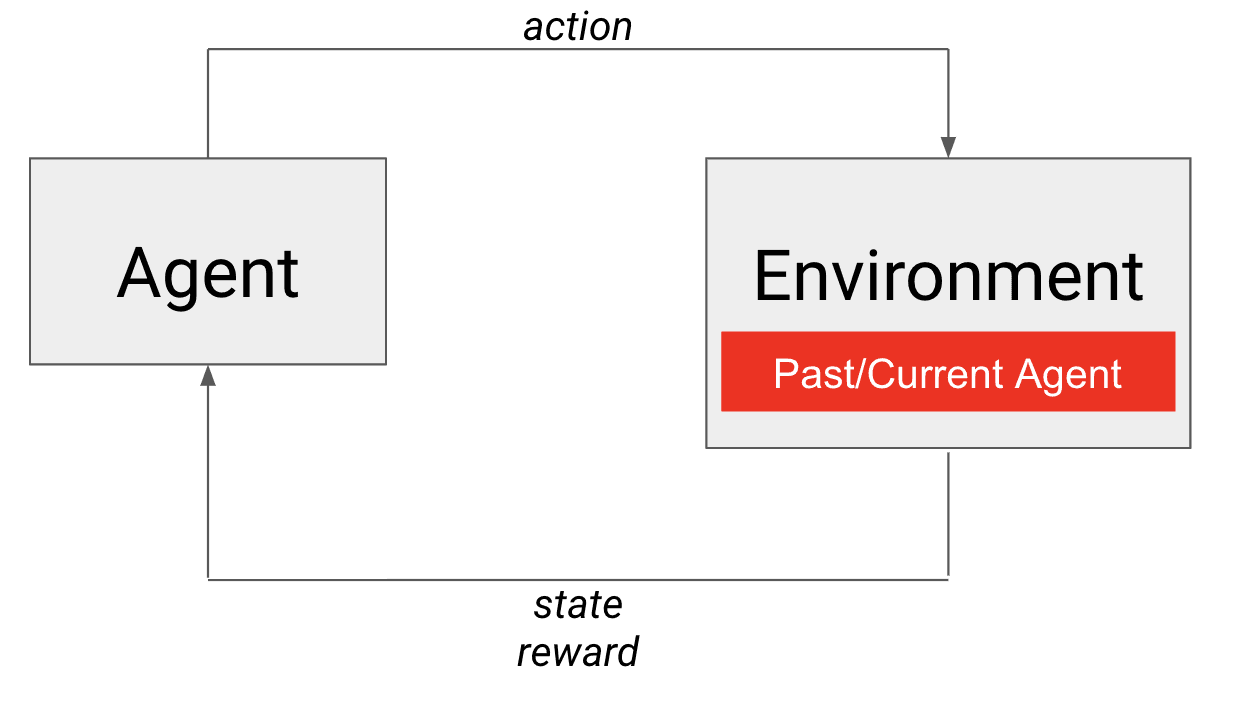
No jogo autônomo, um instantâneo passado ou o agente atual é o adversário incorporado no ambiente.
Auto-jogo para o resgate! O próprio agente atende a ambos os requisitos de um oponente adequado. Certamente, ele é praticamente igual em termos de habilidade (a si mesmo) e também melhora com o tempo. Nesse caso, é a própria política do agente que está incorporada ao ambiente (veja a figura). Para aqueles que estão familiarizados com o aprendizado de currículo, você pode pensar nisso como um currículo em evolução natural (também chamado de currículo automático) para treinar nosso agente contra oponentes de força crescente. Assim, o jogo autônomo nos permite criar um ambiente para treinar agentes competitivos para jogos adversários!
Nas duas subseções a seguir, consideramos aspectos mais técnicos do treinamento de agentes competitivos, bem como alguns detalhes sobre o uso e a implementação do jogo autônomo no ML-Agents Toolkit. Essas duas subseções podem ser ignoradas sem prejuízo do ponto principal desta postagem do blog.
Algumas questões práticas surgem da estrutura de jogo autônomo. Especificamente, o ajuste excessivo para derrotar um estilo de jogo específico e a instabilidade no processo de treinamento que pode surgir da não estacionariedade da função de transição (ou seja, o oponente em constante mudança). O primeiro é um problema porque queremos que nossos agentes sejam competidores gerais e resistentes a diferentes tipos de adversários. Para ilustrar o último, no ambiente de tênis, um adversário diferente devolverá a bola em um ângulo e velocidade diferentes. Do ponto de vista do agente de aprendizado, isso significa que as mesmas decisões levarão a diferentes estados seguintes à medida que o treinamento avança. Os algoritmos tradicionais de RL pressupõem funções de transição estacionárias. Infelizmente, ao fornecer ao agente um conjunto diversificado de oponentes para lidar com o primeiro, podemos exacerbar o segundo se não formos cuidadosos.
Para resolver isso, mantemos um buffer das políticas anteriores do agente, a partir do qual selecionamos oponentes contra os quais o aluno compete por um período mais longo. Ao fazer uma amostragem das políticas anteriores do agente, ele verá um conjunto diversificado de oponentes. Além disso, deixar o agente treinar contra um oponente fixo por um período mais longo estabiliza a função de transição e cria um ambiente de aprendizado mais consistente. Além disso, esses aspectos algorítmicos podem ser gerenciados com os hiperparâmetros discutidos na próxima seção.
Com a seleção de hiperparâmetros de autojogo, a principal consideração é a troca entre o nível de habilidade e a generalidade da política final e a estabilidade do aprendizado. O treinamento contra um conjunto de adversários que mudam lentamente ou que não mudam com baixa diversidade resulta em um processo de aprendizado mais estável do que o treinamento contra um conjunto de adversários que mudam rapidamente com alta diversidade. Os hiperparâmetros disponíveis controlam a frequência com que a política atual de um agente é salva para ser usada posteriormente como um adversário amostrado, a frequência com que um novo adversário é amostrado, o número de oponentes salvos e a probabilidade de jogar contra o agente atual versus um oponente amostrado do pool. Para obter diretrizes de uso dos hiperparâmetros de reprodução automática disponíveis, consulte a documentação de reprodução automática no repositório ML-Agents GitHub.
Em jogos adversários, a recompensa cumulativa do ambiente pode não ser uma métrica significativa para acompanhar o progresso do aprendizado. Isso ocorre porque a recompensa cumulativa depende totalmente da habilidade do oponente. Um agente em um determinado nível de habilidade receberá mais ou menos recompensa contra um agente pior ou melhor, respectivamente. Fornecemos uma implementação do sistema de classificação ELO, um método para calcular o nível de habilidade relativo entre dois jogadores de uma determinada população em um jogo de soma zero. Em uma determinada execução de treinamento, esse valor deve aumentar de forma constante. Você pode acompanhar isso usando o TensorBoard junto com outras métricas de treinamento, por exemplo, a recompensa cumulativa.
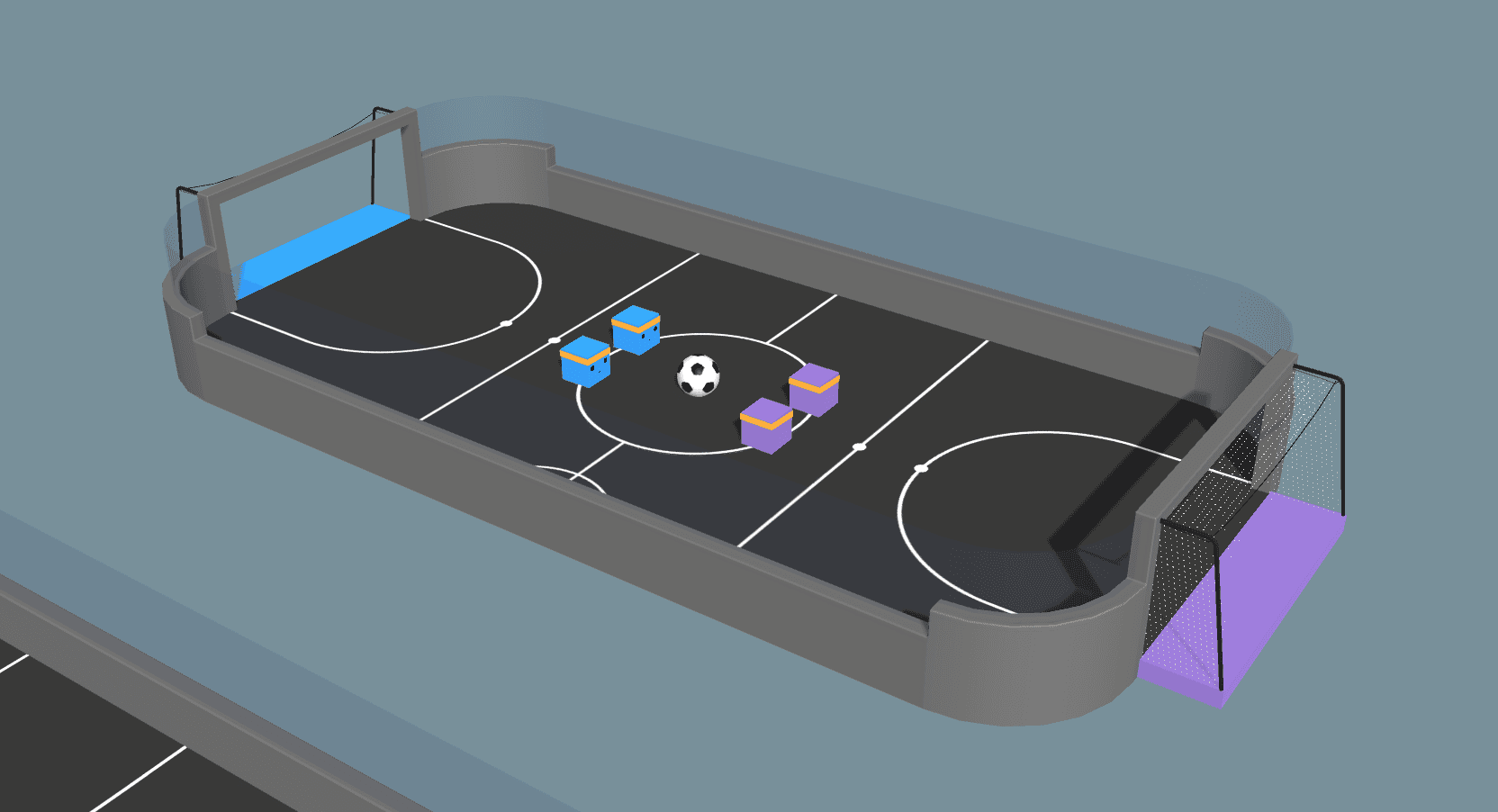
Em versões recentes, não incluímos uma política de agente para o nosso ambiente de exemplo de futebol porque não foi possível treiná-lo de forma confiável. No entanto, com a reprodução automática e algumas refatorações, agora podemos treinar comportamentos de agente não triviais. A mudança mais significativa é a remoção de "posições de jogador" dos agentes. Anteriormente, havia um goleiro e um atacante explícitos, que usávamos para fazer com que a jogabilidade parecesse razoável. No vídeo abaixo, sobre o novo ambiente, observamos o surgimento de um comportamento cooperativo semelhante a uma função, seguindo as mesmas linhas do goleiro e do atacante. Agora os agentes aprendem a jogar nessas posições por conta própria! A função de recompensa para todos os quatro agentes é definida como +1,0 por marcar um gol e -1,0 por levar um gol, com uma penalidade adicional por etapa de tempo de -0,0003 para incentivar os agentes a marcar.
Enfatizamos o fato de que o treinamento de agentes no ambiente de futebol levou a um comportamento cooperativo sem um algoritmo multiagente explícito ou a atribuição de funções. Esse resultado mostra que podemos treinar comportamentos complicados de agentes com algoritmos simples, desde que tomemos cuidado ao formular nosso problema. O segredo para conseguir isso é que os agentes podem observar seus colegas de equipe, ou seja, os agentes recebem informações sobre a posição relativa de seus colegas de equipe como observações. Ao fazer uma jogada agressiva em direção à bola, o agente comunica implicitamente ao seu colega de equipe que ele deve recuar na defesa. Como alternativa, ao recuar na defesa, ele sinaliza para seu colega de equipe que pode avançar no ataque. O vídeo acima mostra os agentes captando essas dicas e demonstrando o posicionamento ofensivo e defensivo geral!
O recurso de autojogo permitirá que você treine comportamentos adversários novos e interessantes em seu jogo. Se você usar o recurso de reprodução automática, conte-nos como foi!
Se você quiser trabalhar nessa empolgante interseção de aprendizado de máquina e jogos, estamos contratando para vários cargos.
Se você usa algum dos recursos oferecidos nesta versão, gostaríamos de saber sua opinião. Para obter feedback sobre o Unity ML-Agents Toolkit, preencha a pesquisa a seguir e fique à vontade para nos enviar um e-mail diretamente. Se encontrar algum erro, entre em contato conosco na página de problemas do ML-Agents no GitHub. Para quaisquer problemas e perguntas gerais, entre em contato conosco nos fóruns do Unity ML-Agents.