繰り返し可能な乱数の入門書


この記事では、使用例としてゲームのレベル/ワールド生成を使うが、この教訓はプロシージャルなテクスチャ、モデル、音楽など、他の多くのものにも応用できる。しかし、暗号のような非常に厳しい要求のアプリケーションには向いていない。
なぜ同じ結果を何度も繰り返したいのか?
- 同じレベル/ワールドを再訪する能力。例えば、特定のシードから特定のレベル/ワールドを作ることができる。同じシードを再度使用すると、同じレベル/ワールドが再び得られる。例えば、マインクラフトではこんなことができる。
- その場で生成される永続的な世界。プレイヤーが移動するたびにその場で生成される世界がある場合、(『Minecraft』や近日発売予定の『No Man's Sky』などのように)プレイヤーが最初に訪れた場所と、その後に訪れた場所が、夢のロジックによって駆動されるように毎回異なるのではなく、同じままであることを望むかもしれない。
- 誰にとっても同じ世界。もしかしたらあなたは、ゲームの世界がプロシージャル生成されていないかのように、プレイするすべての人にとって同じであることを望んでいるかもしれない。例えば『ノーマンズ・スカイ』がそうだ。これは、常に同じシードが使われることを除けば、前述の同じレベル/ワールドを再訪できる能力と本質的に同じである。
シードという言葉については何度か触れた。シードは、数値、テキスト文字列、またはランダムな出力を得るために入力として使用されるその他のデータである。種子の決定的な特徴は、同じ種子は常に同じアウトプットを生み出すが、種子のわずかな変化でもまったく異なるアウトプットを生み出すことができるということだ。
この記事では、乱数を生成する2つの異なる方法-乱数ジェネレータとランダムハッシュ関数-と、どちらか一方を使用する理由について見ていきます。このことについて私が知っていることは、苦労して得たもので、他ではなかなか手に入らないようだ。
乱数を発生させる最も一般的な方法は、乱数発生器(略してRNG)を使うことである。多くのプログラミング言語にはRNGクラスやメソッドがあり、その名前には「ランダム」という言葉が入っている。
乱数発生器は、初期シードに基づいて乱数列を生成する。オブジェクト指向言語では、乱数発生器は通常、シードで初期化されるオブジェクトである。そのオブジェクトのメソッドを繰り返し呼び出すことで、乱数を生成することができる。

C#のコードは次のようになる:
serializers.types`プロップでシリアライザーを指定してください。
この場合、0から可能な最大の整数値(2147483647)の間のランダムな整数値を取得しているが、これを特定の範囲のランダムな整数値や、0から1の間のランダムな浮動小数点数などに変換するのは些細なことだ。多くの場合、これをすぐに実行するメソッドが用意されている。
これはC#のRandomクラスがシード0から生成した最初の65536個の数字の画像です。各乱数は、0(黒)と1(白)の間の明るさを持つピクセルとして表される。

ここで重要なことは、まず1番目と2番目の乱数を取得しなければ、3番目の乱数を取得することはできないということである。これは単なる実施上の見落としではない。RNGはその性質上、前の乱数を計算の一部として用いて各乱数を生成する。したがって、乱数列ということになる。

つまり、RNGはたくさんの乱数を次から次へと必要とする場合には素晴らしいが、特定の乱数(例えば、数列から26番目の乱数)を得ることができる必要がある場合には、運が悪かったということになる。まあ、Next()を26回呼び出して最後の数字を使うこともできるが、これは非常に悪い考えだ。
すべてを一度に生成するのであれば、乱数列から特定の乱数を取り出す必要はないだろう。しかし、その場その場で少しずつ生成するのであれば、そうなる。
例えば、あなたの世界に3つのセクションがあるとする:プレイヤーはセクションAからスタートするので、セクションAは100個の乱数を使って生成される。次に、100種類の数字を使って生成されるセクションBに進む。生成されたセクションAは、メモリを解放するために同時に破棄される。プレーヤーは、100でありながら数字が異なるセクションCに進み、セクションBは破壊される。
しかし、もう一度セクションBに戻ると、同じセクションに見えるように、最初のときと同じ100個の乱数が生成されるはずである。
いや!これはRNGに関する非常に一般的な誤解である。事実、同じ数列の異なる数字は互いに関連してランダムであるが、異なる数列の同じインデックス付き数字は、一見そのように見えても、互いに関連してランダムではないのである。

つまり、100の数列があり、それぞれから最初の数字を取ったとしても、それらの数字は互いにランダムではない。そして、それぞれの列から10番目、100番目、1000番目の数字を取っても、それ以上良くはならない。
この時点で懐疑的な人もいるだろうし、それはそれで構わない。より信頼できるのであれば、Stack OverflowのプロシージャルコンテンツのRNGに関する質問を見ることもできる。しかし、もう少し楽しくてためになることをするために、いくつかの実験をして結果を見てみよう。
参考のために同じ配列から生成された数字を見てみよう。0から65535までの種から生成された65536個の配列のそれぞれの最初の数字を取得して生成された数字と比較してみよう。
パターンは一様に分布しているが、ランダムとは言い難い。実際、比較のために純粋な一次関数の出力を示してみたが、後続のシードからの数値を使っても、一次関数を使うよりもほとんど良くないことが明らかだ。
それでも、ほとんどランダムなのだろうか?それでいいのか?
この時点で、ランダム性を測定するためのより良い方法を導入するのは良いアイデアかもしれない。なぜだ?出力がランダムであれば十分ではないか?
まあ、そうだね。最終的な目標は、物事が十分にランダムに見えるようにすることだ。しかし、乱数出力は使い方によって大きく違って見える。あなたの生成アルゴリズムは、ランダム値をあらゆる方法で変換することができ、単純なシーケンスにリストされた値を検査するだけでは隠されている明確なパターンを明らかにすることができる。
乱数出力を検査する別の方法は、乱数のペアから2次元座標を作成し、その座標を画像にプロットすることである。より多くの座標が同じピクセル上にあるほど、そのピクセルはより明るくなる。
このような座標プロットを、同じ配列の乱数と、異なるシードを持つ個々の配列から作成された乱数の両方について見てみよう。それと、一次関数も入れよう。
おそらく驚くべきことに、異なるシードからの乱数から座標を作成すると、座標は一様に分布するのではなく、すべて細い線にプロットされる。これも一次関数の場合と同じだ。
地形に木を植えるために、乱数から座標を作ったとしよう。これで、すべての木が一直線に植えられ、残りの地形は何もない状態になる!
乱数発生器は、特定の順序で数字にアクセスする必要がない場合にのみ有用であると結論づけることができる。もしそうなら、ランダムハッシュ関数について調べてみるといいだろう。
一般にハッシュ関数とは、任意のサイズのデータを固定サイズのデータにマッピングするために使用できる関数のことで、入力データのわずかな違いが出力データの非常に大きな違いを生む。
手続き的生成の場合、典型的なユースケースは、入力として1つ以上の整数値を与え、出力として乱数を得ることである。例えば、一度にパーツだけが生成されるような大規模なワールドの場合、典型的なニーズは、入力ベクトル(ワールド内の位置など)に関連付けられた乱数を取得することであり、この乱数は同じ入力があれば常に同じでなければならない。乱数発生器(RNG)とは異なり、順番はなく、好きな順番で乱数を得ることができる。

C#のコードは次のようになる:
serializers.types`プロップでシリアライザーを指定してください。
ハッシュ関数は複数の入力を受け取ることもできる。つまり、与えられた2Dまたは3Dの座標に対して乱数を得ることができる:
serializers.types`プロップでシリアライザーを指定してください。
手続き的生成はハッシュ関数の典型的な用途ではないし、すべてのハッシュ関数が手続き的生成に適しているわけでもない。
ハッシュ関数の用途のひとつに、ハッシュ・テーブルや辞書といったデータ構造の実装がある。これらは、ランダム性のためではなく、アルゴリズムを効率的に実行させるためだけのものであるため、多くの場合、高速ではあるが、ランダム性は十分ではない。理論的には、これは同様にランダムであることを意味するが、実際には、これらのランダム性の特性を比較するリソースは見つからなかったし、私がテストしたものはかなり悪いランダム性の特性を持っていることが判明した(詳細は付録Cを参照)。
ハッシュ関数のもう一つの用途は暗号化である。これらは非常にランダムであることが多いが、暗号的に強力なハッシュ関数の要件は、単にランダムに見える値よりもはるかに高いため、速度も遅い。
手続き生成を目的とした我々の目標は、ランダムに見えるが効率的、つまり必要以上に遅くならないランダム・ハッシュ関数である。あなたの選んだプログラミング言語には適切なものが組み込まれていない可能性があり、プロジェクトに組み込むにはそれを見つける必要がある。
私はインターネットの様々なコーナーからの推奨や情報に基づいて、いくつかの異なるハッシュ関数をテストした。ここではその中から3つを選んで比較してみた。
- PcgHash:このハッシュ関数は、Google GroupsフォーラムのProcedural Content Generationに関するディスカッションで、Adam Smithから教えてもらった。アダムは、ちょっとしたスキルがあれば、独自のランダム・ハッシュ関数を作るのはそれほど難しくないことを提案し、その例として彼のPcgHashコード・スニペットを提供した。
- MD5:これは最もよく知られたハッシュ関数のひとつだろう。暗号強度も高く、我々の目的には必要以上に高価だ。その上、MD5がはるかに大きなハッシュ値を返すのに対し、私たちは通常、32ビットのintを返り値として必要とするだけである。それでも、比較のために含める価値はある。
- xxHash:これは高性能な最新の非暗号化ハッシュ関数で、非常に優れたランダム特性と優れた性能を併せ持つ。
ノイズ列画像と座標プロットの生成とは別に、ENT - A Pseudorandom Number Sequence Test Programと呼ばれるランダム性テスト・スイートでもテストした。画像には厳選したENTのスタッツと、私が独自に考案した対角偏差値と呼ばれるスタッツを載せている。後者は、座標プロットからピクセルの対角線の合計を調べ、これらの合計の標準偏差を測定する。
以下は3つのハッシュ関数の結果である:

PcgHashは、連続したランダム値のノイズ画像では非常にランダムに見えるが、座標プロットでは明確なパターンが現れるという点で際立っている。このことから、自分でランダムなハッシュ関数を作るのは難しいので、専門家に任せるべきだろう、という結論に達した。
MD5とxxHashのランダムな特性は非常によく似ており、そのうちxxHashの方が約50倍速い。
xxHashはまた、RNGではないものの、すべてのハッシュ関数に当てはまるわけではないが、シードという概念を持っているという利点もある。シードを指定できることは、プロシージャル生成において明確な利点がある。エンティティやグリッド・セルなどの異なるランダム・プロパティに対して異なるシードを使うことができ、エンティティ・インデックスやセル座標をそのままハッシュ関数の入力として使うことができるからだ。重要なことは、xxHashでは、異なるシード配列からの数値は互いにランダムであるということである(詳細は付録2を参照)。
ハッシュ関数について調べているうちに、汎用のハッシュ・ベンチマークで高性能なハッシュ関数を選ぶのは良いことだが、ハッシュ関数をそのまま使うのではなく、手続き生成のニーズに合わせて最適化することがパフォーマンスにとって極めて重要であることが明らかになった。
つの重要な最適化がある:
- 整数とバイト間の変換を避ける。ほとんどの汎用ハッシュ関数は、入力としてバイト配列を受け取り、ハッシュ値として整数またはいくつかのバイトを返す。しかし、高性能なものの中には、内部で整数を操作するため、入力バイトを整数に変換するものもある。手続き型生成では、整数の入力値に基づいてハッシュを取得するのが一般的なので、バイトへの変換はまったく無意味である。バイトへの依存をなくすリファクタリングによって、出力を100%同じにしたままパフォーマンスを3倍にすることができる。
- 1つまたは少数の入力を取るループのないメソッドを実装する。ほとんどの汎用ハッシュ関数は、配列の形で可変長の入力データを受け取る。これは手続き的生成にも便利だが、最も一般的な使い方は、1、2、3個の入力整数をもとにハッシュを生成することだろう。配列ではなく固定数の整数を受け取る最適化されたメソッドを作成することで、ハッシュ関数内のループが不要になり、パフォーマンスが劇的に向上する(私のテストでは約4倍から5倍)。私は低レベルの最適化の専門家ではないが、この劇的な違いは、forループの暗黙の分岐か、配列を確保する必要性のどちらかが原因かもしれない。
私が現在推奨しているハッシュ関数は、手続き型生成に最適化されたxxHashの実装を使うことだ。その理由については付録Cを参照のこと。
私がC#で実装したxxHashやその他のハッシュ関数は、BitBucketで入手できる。これは、ユニティ・テクノロジーズではなく、私が自由な時間に個人的に管理しているものです。
最適化のほかに、プロシージャル生成の典型的なニーズである、指定範囲の整数値や指定範囲の浮動小数点数として出力を得るためのメソッドも追加した。
注意:この記事を書いている時点では、xxHashとMurmurHash3に整数入力の最適化を1つ追加しただけだ。時間があれば、2つ、3つの整数入力用に最適化されたオーバーロードも追加するつもりだ。
ランダムハッシュ関数と乱数ジェネレーターを組み合わせることもできる。賢明なアプローチは、異なるシードを持つ乱数ジェネレーターを使用することであるが、シードは直接使用されるのではなく、ランダムなハッシュ関数に渡される。
大きな迷路のような世界があるとしよう。世界には大規模なグリッドがあり、各グリッドマスは迷路になっている。プレイヤーが世界を移動すると、プレイヤーを囲むグリッドマスに迷路が生成される。
この場合、各迷路は訪れるたびに常に同じように生成されるようにしたいので、そのために必要な乱数は、以前に生成された乱数から独立して生成できる必要がある。
しかし、迷路は常に1度に1つの迷路全体が生成されるため、1つの迷路に使用される個々の乱数の順序を制御する必要はない。
ここでの理想的なアプローチは、ランダム・ハッシュ関数を使用して、迷路のグリッド・セルの座標に基づいて迷路のシードを作成し、このシードを乱数発生器の乱数列に使用することである。

C#のコードは次のようになる:
serializers.types`プロップでシリアライザーを指定してください。
乱数を問い合わせる順序を制御する必要がある場合は、手続き的生成に最適化された実装で適切なランダム・ハッシュ関数(xxHashなど)を使用する。
乱数の束を取得する必要があり、順序が重要でない場合、最も簡単な方法は、C#のSystem.Randomクラスのような乱数ジェネレータを使用することです。すべての数値が互いにランダムであるためには、(1つのシードで初期化された)単一のシーケンスのみを使用するか、複数のシードを使用する場合は、最初にランダムなハッシュ関数(xxHashなど)に通す必要がある。
この記事で紹介した乱数テスト・フレームワークのソースコードや、さまざまなRNGやハッシュ関数は、BitBucketで入手できる。これは、ユニティ・テクノロジーズではなく、私が自由な時間に個人的に管理しているものです。
この記事は元々runevisionのブログに掲載されたもので、私の自由な時間に行うゲーム開発と研究に特化したものである。
あるものについては、連続的なノイズ値、つまり、互いに近い入力値が互いに近い出力値を生成するようなノイズ値を照会できるようにしたいと思うだろう。典型的な用途は、テラインやテクスチャだ。
これらの要件は、この記事で取り上げたものとはまったく異なる。連続的なノイズについては、パーリン・ノイズ、あるいはシンプレックス・ノイズが良い。
ただし、これらは連続的なノイズにしか適していないことに注意してほしい。他の乱数とは無関係な乱数を取得するためだけに連続ノイズ関数をクエリしても、これらのアルゴリズムが最適化されているものではないので、悪い結果になる。例えば、Simplex Noise関数を整数の位置でクエリすると、3番目の入力ごとに0を返すことがわかった!
さらに、連続ノイズ関数は通常、浮動小数点数を計算に使用するが、これは原点から離れるほど安定性と精度が悪くなる。
私は長年にわたってさまざまな誤解を耳にしてきたが、ここではそのうちのいくつかを取り上げてみようと思う。
いや、それを示すものは何も見ていない。この記事を通してテスト画像を見ると、シード値が低くても高くても結果に違いはない。
いや、もう一度テスト画像を見ると、ランダムな値の並びが、始まり(左上隅から1行ずつ進む)から終わりまで同じパターンをたどっているのがわかる。
下の画像では、65535個の配列の0番目の数字と、同じ配列の100番目の数字をテストした。見てわかるように、ランダム性の(欠如した)質に明らかな有意差はない。

少しはマシになったかもしれないが、十分とは言えない。C#のRandomクラスとは異なり、JavaのRandomクラスは、提供されたシードをそのまま使うのではなく、シードを保存する前にビットを少しシャッフルする。
異なるシークエンスから得られた数値は、ほんの少しランダムに見えるかもしれない。しかし、座標プロットでは、座標に使用した場合、数値は依然として1本の線に折りたたまれることは明らかである。

とはいえ、RNGがシードを使う前に高品質のランダム・ハッシュ関数を適用できない理由はない。実際、そうするのはとてもいいアイデアのように思えるし、思い当たるデメリットもない。ただ、私が知っている一般的なRNGの実装はそうなっていないので、前述のように自分でやる必要がある。
本質的な理由はないが、xxHashやMurmurHash3のようなハッシュ関数は、シード値を入力と同様に扱うので、いわば本質的に高品質のランダム・ハッシュ関数をシードに適用することになる。このように実装されているため、異なるシードを持つランダム・ハッシュ・オブジェクトからN番目の数字を使用しても安全である。

この記事のオリジナル版では、PcgHash、MD5、MurmurHash3を比較し、MurmurHash3の使用を推奨した。
MurmurHash3は優れたランダム性を持ち、スピードもそこそこある。作者は、SMHasherと呼ばれるハッシュ関数をテストするためのフレームワークと並行してこれを実装した。
また、このStack Overflowの質問では、一意性と速度のために良いハッシュ関数について、より多くのハッシュ関数が比較されており、MurmurHashについても同様に好意的に描かれているようだ。
記事を公開した後、Aras PranckevičiusからxxHashを、Nathan Reedから彼がここに書いているWang Hashを調べてみるように勧められた。
xxHashは、SMHasherテストフレームワークにおいて、MurmurHashと同程度の品質スコアを獲得し、パフォーマンスも大幅に向上させたハッシュ関数である。xxHashについての詳細はGoogle Codeのページを参照。
私の最初の実装では、バイト変換を削除した後、SMHasherの結果ほどではないにせよ、MurmurHash3よりわずかに高速だった。
WangHashも実装した。座標プロットで明確なパターンを示したため、品質が不十分であることが判明したが、xxHashより5倍以上速かった。WangDoubleHash "を実装し、その結果を自分自身に送るようにしてみた。
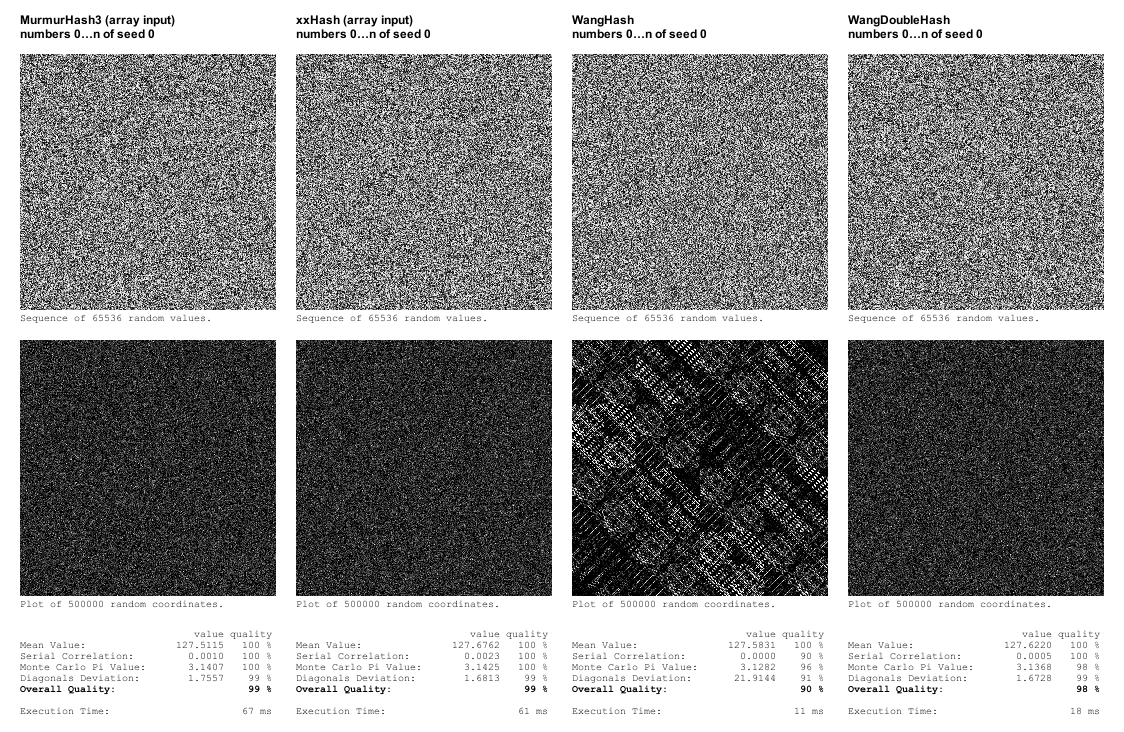
しかし、WangHash(とWangDoubleHash)は入力として単一の整数しか受け取らないので、パフォーマンスにどのような影響を与えるか確認するために、xxHashとMurmurHash3の単一入力バージョンも実装することにしました。その結果、パフォーマンスが劇的に向上した(約4~5倍速くなった)。実際、xxHashはWangDoubleHashよりも速くなった。

品質に関しては、私自身のテストフレームワークではかなり明白な欠陥が見つかったが、SMHasherテストフレームワークほど洗練されていない。一般的には、私のテスト・フレームワークのテストをパスすれば、手続き生成の目的には十分かもしれないが、xxHash(最適化されたバージョン)は、私自身のテストをパスする最速のハッシュ関数なので、それを使うのは当然だ。
世の中には非常に多くの異なるハッシュ関数があり、比較のためにさらに多くのハッシュ関数を含めることは常に可能だろう。しかし、私は主に、ランダム性の質と性能の両方において、広く認められている最も性能の良いものに焦点を当て、それらをプロシージャル生成用にさらに最適化した。
このバージョンのxxHashで得られた結果は最適に近いと思うし、さらに良いものを見つけて使うことで得られるものは小さいだろう。とはいえ、テストフレームワークをより多くの実装で拡張するのは自由だ。