Учебник по повторяющимся случайным числам


В этой статье мы будем использовать генерацию уровней/миров в играх в качестве примера, но уроки применимы ко многим другим вещам, таким как процедурные текстуры, модели, музыка и т.д. Однако они не предназначены для приложений с очень строгими требованиями, таких как криптография.
Зачем вам повторять один и тот же результат несколько раз?
- Возможность повторного посещения одного и того же уровня/мира. Например, определенный уровень/мир может быть создан из определенного семени. При повторном использовании одного и того же семени вы снова получите тот же уровень/мир. Например, это можно сделать в Minecraft.
- Постоянный мир, который создается на лету. Если у вас есть мир, который генерируется на лету, когда игрок перемещается по нему, вы можете захотеть, чтобы локации оставались одинаковыми в первый и последующие разы, когда игрок посещает их (как в Minecraft, грядущей игре No Man's Sky и других), а не были разными каждый раз, как будто управляемые логикой сна.
- Один и тот же мир для всех. Может быть, вы хотите, чтобы ваш игровой мир был одинаковым для всех, кто в него играет, точно так же, как если бы он не был процедурно сгенерирован. Так, например, происходит в No Man's Sky. По сути, это то же самое, что и упомянутая выше возможность повторного посещения одного и того же уровня/мира, за исключением того, что всегда используется одно и то же семя.
Мы уже несколько раз упоминали слово " семя". В качестве затравки может выступать число, текстовая строка или другие данные, которые используются в качестве входных для получения случайного результата. Определяющей чертой семени является то, что одно и то же семя всегда дает один и тот же результат, но даже малейшее изменение в семени может дать совершенно другой результат.
В этой статье мы рассмотрим два различных способа получения случайных чисел - генераторы случайных чисел и случайные хэш-функции - и причины, по которым стоит использовать тот или иной способ. То, что я знаю об этом, получено тяжким трудом и, похоже, не всегда доступно в других местах, поэтому я решил записать это и поделиться.
Самый распространенный способ получения случайных чисел - это использование генератора случайных чисел (или сокращенно ГСЧ). Во многих языках программирования есть классы или методы RNG, и в их названии присутствует слово "random", так что это очевидный подход для начала работы со случайными числами.
Генератор случайных чисел создает последовательность случайных чисел на основе начальной затравки. В объектно-ориентированных языках генератор случайных чисел обычно представляет собой объект, который инициализируется с помощью семпла. Затем можно многократно вызывать метод этого объекта для получения случайных чисел.

Код на языке C# может выглядеть следующим образом:
Неизвестный тип блока "codeBlock", укажите для него сериализатор в свойстве `serializers.types`.
В данном случае мы получаем случайные целые значения от 0 до максимально возможного целого значения (2147483647), но это тривиально преобразовать в случайное целое число в определенном диапазоне, или случайное число с плавающей точкой от 0 до 1, или что-то подобное. Часто предлагаются методы, которые делают это из коробки.
Вот изображение с первыми 65536 числами, сгенерированными классом Random в C# из семени 0. Каждое случайное число представлено в виде пикселя с яркостью от 0 (черный) до 1 (белый).

Важно понимать, что вы не сможете получить третье случайное число, не получив сначала первое и второе. Это не просто упущение в реализации. По своей природе ГПСЧ генерирует каждое случайное число, используя в расчетах предыдущее случайное число. Следовательно, мы говорим о случайной последовательности.

Это означает, что ГПСЧ отлично подходят, если вам нужна куча случайных чисел, следующих одно за другим, но если вам нужно получить конкретное случайное число (скажем, 26-е случайное число из последовательности), то вам не повезло. Можно вызвать Next() 26 раз и использовать последнее число, но это очень плохая идея.
Если вы генерируете все сразу, вам, вероятно, не нужны конкретные случайные числа из последовательности, или, по крайней мере, я не могу придумать причину. Однако если вы генерируете все по кусочкам на лету, то так оно и есть.
Например, в вашем мире есть три раздела: Игрок начинает в секции A, поэтому секция A генерируется с помощью 100 случайных чисел. Затем игрок переходит к разделу B, который генерируется с помощью 100 различных чисел. Сгенерированная секция A уничтожается в то же время, чтобы освободить память. Игрок переходит к разделу C, который состоит из 100 различных чисел, а раздел B уничтожается.
Однако если игрок снова вернется к разделу B, он должен будет сгенерировать те же 100 случайных чисел, что и в первый раз, чтобы раздел выглядел одинаково.
Нет! Это очень распространенное заблуждение относительно RNG. Дело в том, что если разные числа в одной последовательности случайны по отношению друг к другу, то одинаковые индексированные числа из разных последовательностей не случайны по отношению друг к другу, даже если на первый взгляд так и кажется.

Так что если у вас есть 100 последовательностей и вы берете первое число из каждой, эти числа не будут случайными по отношению друг к другу. И не будет лучше, если вы возьмете 10-е, 100-е, 1000-е число из каждой последовательности.
В этот момент некоторые люди будут настроены скептически, и это нормально. Вы также можете взглянуть на этот вопрос Stack Overflow о RNG для процедурного контента, если он заслуживает большего доверия. Но чтобы было немного веселее и познавательнее, давайте проведем несколько экспериментов и посмотрим на результаты.
Давайте посмотрим на числа, сгенерированные из той же последовательности, и сравним их с числами, созданными путем получения первого числа в каждой из 65536 последовательностей, созданных из семян от 0 до 65535.
Хотя узор распределен довольно равномерно, он не совсем случаен. На самом деле я показал для сравнения результат чисто линейной функции, и стало очевидно, что использование чисел из последующих семян едва ли лучше, чем просто линейная функция.
Тем не менее, это почти случайность? Достаточно ли это хорошо?
На этом этапе может быть хорошей идеей ввести более совершенные способы измерения случайности, поскольку невооруженный глаз не очень надежен. Почему бы и нет? Разве не достаточно того, что вывод выглядит достаточно случайным?
Ну да, в конце концов, наша цель - чтобы все выглядело достаточно случайным. Но вывод случайных чисел может выглядеть совершенно по-разному в зависимости от того, как он используется. Ваши алгоритмы генерации могут преобразовывать случайные значения всевозможными способами, которые позволят выявить четкие закономерности, скрытые при простом просмотре значений, перечисленных в простой последовательности.
Альтернативным способом проверки случайного вывода является создание двумерных координат из пар случайных чисел и нанесение этих координат на изображение. Чем больше координат попадает на один и тот же пиксель, тем ярче он становится.
Рассмотрим такой график координат как для случайных чисел в одной последовательности, так и для случайных чисел, созданных из отдельных последовательностей с разными семенами. О, и давайте добавим сюда линейную функцию.
Возможно, удивительно, что при создании координат из случайных чисел, полученных из разных семян, все координаты выстраиваются в тонкие линии, а не распределяются сколько-нибудь равномерно. Это опять же как для линейной функции.
Представьте, что вы создали координаты из случайных чисел, чтобы посадить деревья на местности. Теперь все ваши деревья будут высажены по прямой линии, а оставшаяся местность будет пустой!
Мы можем сделать вывод, что генераторы случайных чисел полезны только в том случае, если вам не нужно получать числа в определенном порядке. Если да, то вам стоит обратить внимание на случайные хэш-функции.
В общем случае хэш-функция - это любая функция, которая может быть использована для сопоставления данных произвольного размера с данными фиксированного размера, причем небольшие различия во входных данных приводят к очень большим различиям в выходных данных.
Для процедурной генерации типичными случаями использования являются предоставление одного или нескольких целых чисел в качестве входных данных и получение случайного числа в качестве выходного. Например, для больших миров, где за раз генерируются только части, типичной потребностью является получение случайного числа, связанного с вектором входных данных (например, местоположение в мире), и это случайное число должно быть всегда одинаковым при одинаковых входных данных. В отличие от генераторов случайных чисел (ГСЧ), здесь нет последовательности - вы можете получать случайные числа в любом порядке.

Код на C# может выглядеть следующим образом - обратите внимание, что вы можете получить числа в любом порядке:
Неизвестный тип блока "codeBlock", укажите для него сериализатор в свойстве `serializers.types`.
Хеш-функция также может принимать несколько входов, что означает, что вы можете получить случайное число для заданной 2D или 3D координаты:
Неизвестный тип блока "codeBlock", укажите для него сериализатор в свойстве `serializers.types`.
Процедурная генерация не является типичным применением хэш-функций, и не все хэш-функции хорошо подходят для процедурной генерации, поскольку они могут либо не иметь достаточно случайного распределения, либо быть неоправданно дорогими.
Одно из применений хэш-функций - это реализация структур данных, таких как хэш-таблицы и словари. Они часто бывают быстрыми, но не достаточно случайными, поскольку предназначены не для случайности, а только для того, чтобы алгоритмы работали эффективно. Теоретически это означает, что они также должны быть случайными, но на практике я не нашел ресурсов, которые сравнивали бы их свойства случайности, а те, которые я тестировал, оказались довольно плохими (подробности см. в приложении C).
Еще одно применение хэш-функции - криптография. Они часто бывают очень случайными, но также медленными, поскольку требования к криптографически сильным хэш-функциям гораздо выше, чем к значениям, которые просто выглядят случайными.
Наша цель для целей процедурной генерации - случайная хэш-функция, которая выглядит случайной, но при этом эффективна, то есть работает не медленнее, чем нужно. Скорее всего, в выбранном вами языке программирования нет подходящего варианта, и вам придется искать его, чтобы включить в свой проект.
Я протестировал несколько различных хэш-функций, основываясь на рекомендациях и информации из разных уголков Интернета. Я выбрал три из них для сравнения.
- PcgHash: Эту хэш-функцию я получил от Адама Смита в дискуссии на форуме Google Groups, посвященной процедурной генерации контента. Адам заявил, что при наличии небольшого навыка несложно создать собственную случайную хэш-функцию, и предложил в качестве примера свой фрагмент кода PcgHash.
- MD5: Это, возможно, одна из самых известных хэш-функций. Кроме того, он имеет криптографическую прочность и стоит дороже, чем нужно для наших целей. Кроме того, нам обычно нужен только 32-битный int в качестве возвращаемого значения, в то время как MD5 возвращает гораздо большее хэш-значение, большую часть которого мы просто выбросим. Тем не менее его стоит включить для сравнения.
- xxHash: Это высокопроизводительная современная некриптографическая хэш-функция, обладающая как очень хорошими случайными свойствами, так и высокой производительностью.
Помимо создания изображений шумовых последовательностей и графиков координат, я также провел тестирование с помощью пакета тестирования случайности под названием ENT - A Pseudorandom Number Sequence Test Program. Я включил в изображения избранные статистики ENT, а также статистику, которую я придумал сам и назвал "Диагональное отклонение". В последнем случае рассматриваются суммы диагональных линий пикселей с координатного графика и измеряется стандартное отклонение этих сумм.
Вот результаты работы трех хэш-функций:

PcgHash отличается тем, что, хотя на шумовых изображениях последовательных случайных значений он выглядит очень случайным, на графике координат видны четкие закономерности, что означает, что он плохо поддается простым преобразованиям. Из этого я делаю вывод, что создать свою собственную случайную хэш-функцию очень сложно и, вероятно, ее следует доверить специалистам.
MD5 и xxHash, похоже, имеют очень сопоставимые случайные свойства, и из них xxHash примерно в 50 раз быстрее.
Преимущество xxHash также в том, что, хотя это и не ГПЗУ, в ней все же есть понятие семени, что характерно не для всех хэш-функций. Возможность указать семя имеет очевидные преимущества для процедурной генерации, поскольку вы можете использовать разные семена для различных случайных свойств сущностей, ячеек сетки или чего-то подобного, а затем просто использовать индекс сущности / координату ячейки в качестве входных данных для хэш-функции как есть. Очень важно, что в xxHash числа из разных последовательностей случайны по отношению друг к другу (подробнее см. в Приложении 2).
В ходе моих исследований хэш-функций стало ясно, что, хотя хорошо выбрать хэш-функцию, которая показывает высокие результаты в хэш-бенчмарках общего назначения, для производительности очень важно оптимизировать ее под нужды процедурной генерации, а не просто использовать хэш-функцию как есть.
Есть две важные оптимизации:
- Избегайте преобразований между целыми числами и байтами. Большинство хэш-функций общего назначения принимают на вход массив байтов и возвращают целое число или несколько байтов в качестве хэш-значения. Однако некоторые высокопроизводительные программы преобразуют входные байты в целые числа, поскольку внутри они оперируют целыми числами. Поскольку чаще всего процедурная генерация получает хэш на основе целочисленных входных значений, преобразование в байты совершенно бессмысленно. Рефакторинг зависимости от байтов может увеличить производительность в три раза, при этом вывод будет на 100% идентичным.
- Реализуйте незацикленные методы, которые принимают только один или несколько входных данных. Большинство хэш-функций общего назначения принимают на вход данные переменной длины в виде массива. Это полезно и для процедурной генерации, но наиболее часто используется, вероятно, для получения хэша на основе всего 1, 2 или 3 входных целых чисел. Создание оптимизированных методов, которые принимают фиксированное число целых чисел, а не массив, может устранить необходимость в цикле в хэш-функции, и это может значительно повысить производительность (примерно в 4x-5x в моих тестах). Я не специалист по низкоуровневой оптимизации, но резкая разница может быть вызвана либо неявным ветвлением в цикле for, либо необходимостью выделения массива.
Моя текущая рекомендация для хэш-функции - использовать реализацию xxHash, оптимизированную для процедурной генерации. Подробнее о причинах см. в Приложении C.
Мои реализации xxHash и других хэш-функций на C# вы можете получить на BitBucket. Я занимаюсь этим в свободное от работы время, а не Unity Technologies.
Помимо оптимизаций я также добавил дополнительные методы для получения на выходе целого числа в указанном диапазоне или числа с плавающей точкой в указанном диапазоне, что является типичной необходимостью при процедурной генерации.
Примечание: На момент написания статьи я добавил оптимизацию ввода одного целого числа только в xxHash и MurmurHash3. Я добавлю оптимизированные перегрузки для двух и трех целочисленных входов, когда у меня появится время.
Случайные хэш-функции и генераторы случайных чисел также могут быть объединены. Разумным подходом является использование генераторов случайных чисел с различными семенами, но при этом семена не используются напрямую, а проходят через случайную хэш-функцию.
Представьте, что у вас есть большой мир-лабиринт, возможно, почти бесконечный. Мир имеет крупномасштабную сетку, каждая ячейка которой представляет собой лабиринт. По мере того как игрок перемещается по миру, в ячейках сетки, окружающей игрока, возникают лабиринты.
В этом случае вы хотите, чтобы каждый лабиринт всегда генерировался одинаково при каждом посещении, поэтому необходимые для этого случайные числа должны быть способны генерироваться независимо от ранее сгенерированных чисел.
Однако лабиринты всегда генерируются по одному, поэтому нет необходимости контролировать порядок отдельных случайных чисел, используемых для одного лабиринта.
Идеальный подход здесь - использовать случайную хэш-функцию для создания затравки для лабиринта на основе координат ячейки сетки лабиринта, а затем использовать эту затравку для генератора случайных чисел, создающего последовательность случайных чисел.

Код на C# может выглядеть следующим образом:
Неизвестный тип блока "codeBlock", укажите для него сериализатор в свойстве `serializers.types`.
Если вам нужен контроль над порядком запроса случайных чисел, используйте подходящую случайную хэш-функцию (например, xxHash) в реализации, оптимизированной для процедурной генерации.
Если вам просто нужно получить кучу случайных чисел, и порядок не имеет значения, самый простой способ - использовать генератор случайных чисел, например класс System.Random в C#. Для того чтобы все числа были случайными по отношению друг к другу, следует использовать только одну последовательность (инициализированную одним семенем), либо, если используется несколько семян, их следует сначала пропустить через случайную хэш-функцию (например, xxHash).
Исходный код фреймворка для тестирования случайных чисел, о котором идет речь в этой статье, а также различных ГПСЧ и хэш-функций, доступен на BitBucket. Я занимаюсь этим в свободное от работы время, а не Unity Technologies.
Эта статья первоначально появилась в блоге runevision, посвященном разработке игр и исследованиям, которыми я занимаюсь в свободное время.
Для некоторых вещей вы захотите иметь возможность запрашивать значения шума, которые являются непрерывными, то есть входные значения, находящиеся рядом друг с другом, дают выходные значения, которые также находятся рядом друг с другом. Обычно используется для создания рельефов или текстур.
Эти требования полностью отличаются от тех, о которых идет речь в данной статье. Для непрерывного шума обратите внимание на Perlin Noise - или лучше на Simplex Noise.
Однако имейте в виду, что они подходят только для непрерывного шума. Запрос функций непрерывного шума только для того, чтобы получить случайные числа, не связанные с другими случайными числами, даст плохие результаты, поскольку это не то, для чего оптимизированы эти алгоритмы. Например, я обнаружил, что запрос функции Simplex Noise на целочисленные позиции возвращает 0 на каждый третий вход!
Кроме того, функции непрерывного шума обычно используют в своих вычислениях числа с плавающей точкой, которые имеют худшую стабильность и точность, чем дальше от начала координат.
На протяжении многих лет мне приходилось слышать различные заблуждения, и здесь я постараюсь рассмотреть несколько из них.
Нет, я не видел ничего, что указывало бы на это. Если вы посмотрите на тестовые изображения в этой статье, то не увидите разницы между результатами при низких и высоких значениях посевного материала.
Нет. Опять же, если вы посмотрите на тестовые изображения, то увидите, что последовательности случайных значений следуют одному и тому же шаблону от начала (верхний левый угол и далее одна строка за другой) до конца.
На изображении ниже я проверил 0-е число в 65535 последовательностях, а также 100-е число в тех же последовательностях. Как видно, существенной разницы в качестве (отсутствии) случайности нет.

Может быть, немного лучше, но не настолько. В отличие от класса Random в C#, класс Random в Java не использует предоставленное семя как таковое, а немного перемешивает биты перед сохранением семени.
Числа, полученные из разных последовательностей, могут выглядеть немного более случайными, и мы видим из статистики тестов, что Serial Correlation намного лучше. Однако на графике координат видно, что при использовании координат числа все равно сводятся к одной линии.

Тем не менее, нет причин, по которым ГПЗУ не мог бы применить высококачественную случайную хэш-функцию к семени перед его использованием. На самом деле это кажется очень хорошей идеей, не имеющей никаких отрицательных сторон, о которых я могу подумать. Просто популярные реализации RNG, о которых я знаю, этого не делают, поэтому вам придется сделать это самостоятельно, как было описано ранее.
Внутренней причины для этого нет, но такие хэш-функции, как xxHash и MurmurHash3, обращаются с начальным значением так же, как и с входными данными, то есть, по сути, применяют к нему высококачественную случайную хэш-функцию. Поскольку это реализовано таким образом, можно безопасно использовать N-е число из разных посеянных случайных хэш-объектов.

В первоначальной версии этой статьи я сравнивал PcgHash, MD5 и MurmurHash3 и рекомендовал использовать MurmurHash3.
MurmurHash3 обладает отличными свойствами случайности и очень приличной скоростью. Автор реализовал его параллельно с фреймворком для тестирования хэш-функций под названием SMHasher, который стал широко использоваться для этих целей.
Также есть хорошая информация в этом вопросе Stack Overflow о хороших хэш-функциях для уникальности и скорости, где сравнивается множество других хэш-функций и, кажется, рисуется не менее благоприятная картина MurmurHash.
После публикации статьи я получил рекомендации от Араса Пранцкявичуса посмотреть на xxHash, а от Натана Рида - на Wang Hash, о котором он писал здесь.
xxHash - это хэш-функция, которая, по-видимому, выигрывает у MurmurHash на ее собственной территории, получая такие же высокие оценки качества в рамках тестирования SMHasher и имея при этом значительно лучшую производительность. Подробнее о xxHash можно прочитать на странице Google Code.
В моей первоначальной реализации, после того как я убрал преобразования байтов, он оказался немного быстрее MurmurHash3, хотя и не настолько, как показано в результатах SMHasher.
Я также реализовал WangHash. Качество оказалось недостаточным, так как на графике координат видны четкие закономерности, но он оказался более чем в пять раз быстрее xxHash. Я попробовал реализовать "WangDoubleHash", в котором его результат передается самому себе, и он показал прекрасное качество в моих тестах, но при этом оказался более чем в три раза быстрее, чем xxHash.
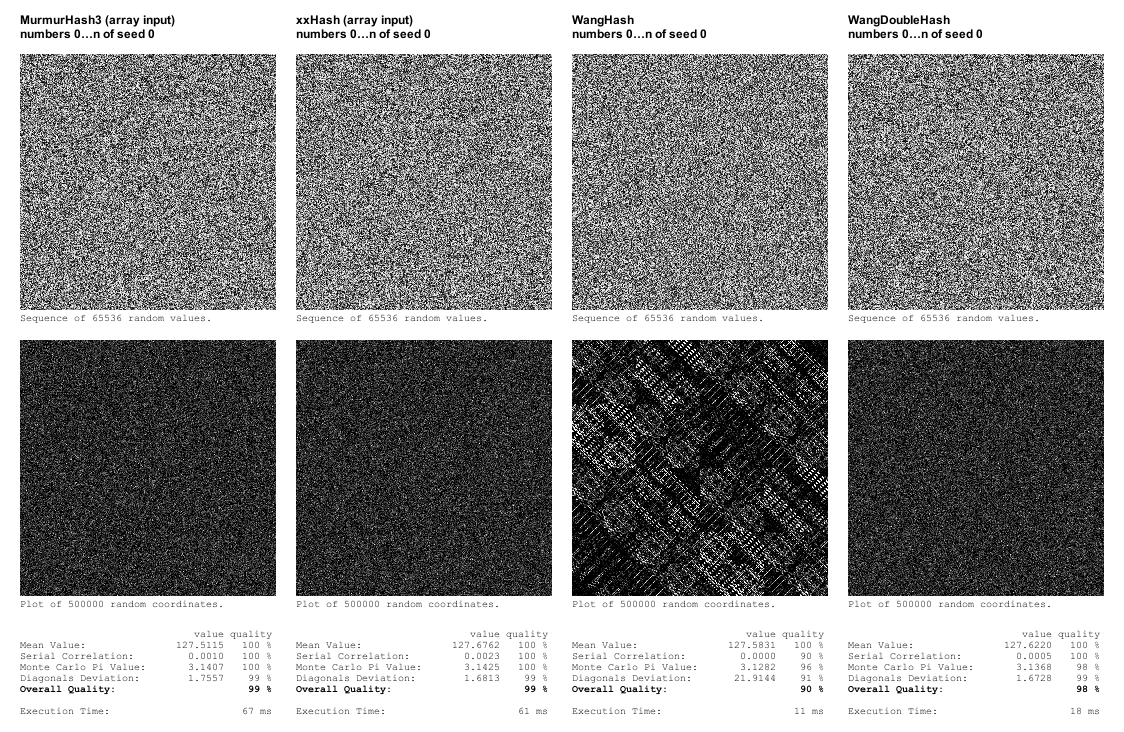
Однако, поскольку WangHash (и WangDoubleHash) принимают на вход только одно целое число, я решил также реализовать версии xxHash и MurmurHash3 с одним входом, чтобы посмотреть, как это повлияет на производительность. И оказалось, что это значительно повышает производительность (примерно в 4-5 раз). Настолько, что xxHash стал быстрее, чем WangDoubleHash.

Что касается качества, то мой собственный тестовый фреймворк выявляет достаточно очевидные недостатки, но он не настолько сложен, как тестовый фреймворк SMHasher, поэтому можно предположить, что хэш-функция, получившая там высокий балл, является более надежным знаком качества для свойств случайности, чем просто хорошо выглядящая в моих собственных тестах. В целом, я бы сказал, что прохождение тестов в моем тестовом фреймворке может быть достаточным для целей процедурной генерации, но поскольку xxHash (в ее оптимизированной версии) является самой быстрой хэш-функцией, проходящей мои собственные тесты в любом случае, не будет лишним просто использовать ее.
Существует огромное количество различных хэш-функций, и всегда можно было бы включить еще больше для сравнения. Однако я остановился на некоторых из общепризнанных лучших по качеству случайности и производительности, а затем оптимизировал их для процедурной генерации.
Я думаю, что результаты, полученные с помощью этой версии xxHash, довольно близки к оптимальным, и дальнейший выигрыш от поиска и использования чего-то еще лучшего, скорее всего, будет небольшим. Тем не менее, не стесняйтесь расширять тестовый фреймворк за счет других реализаций.