可重复随机数入门


在本文中,我们将以游戏中的关卡/世界生成作为用例,但这些经验也适用于其他许多方面,例如程序纹理、模型、音乐等。不过,它们并不适合要求非常严格的应用,如密码学。
为什么要多次重复同样的结果?
- 能够重访同一关卡/世界。例如,某个关卡/世界可以由特定的种子创建。如果再次使用相同的种子,您将再次获得相同的关卡/世界。例如,您可以在 Minecraft 中这样做。
- 即时生成的持久世界。如果你有一个随着玩家在其中移动而即时生成的世界,你可能希望玩家在第一次和以后访问这些地点时,地点都保持不变(比如在 Minecraft 和即将推出的游戏 No Man's Sky 以及其他游戏中),而不是每次都不同,就像由梦境逻辑驱动一样。
- 每个人的世界都一样也许你希望你的游戏世界对每个人来说都是一样的,就像它不是程序生成的一样。例如,《无主之地》就属于这种情况。这与上文提到的重访同一关卡/世界的功能基本相同,只是使用的种子始终相同。
我们已经多次提到种子这个词。种子可以是数字、文本字符串或其他数据,用作输入以获得随机输出。种子的决定性特征是,相同的种子总是会产生相同的产出,但即使种子发生最细微的变化,也会产生完全不同的产出。
本文将介绍两种不同的随机数生成方法--随机数生成器和随机散列函数--以及使用其中一种的原因。我所知道的这些都是来之不易的,在其他地方似乎并不容易找到,所以我觉得应该写下来与大家分享。
产生随机数最常见的方法是使用随机数发生器(简称 RNG)。许多编程语言都包含 RNG 类或方法,而且它们的名称中都有 "随机 "一词,因此这显然是开始使用随机数的首选方法。
随机数发生器根据初始种子产生一串随机数。在面向对象语言中,随机数发生器通常是一个用种子初始化的对象。然后就可以重复调用该对象上的方法来生成随机数。

C# 代码可以这样写
未知块类型 "codeBlock",请在 "serializers.type "道具中为其指定一个序列化器
在这种情况下,我们得到的是介于 0 和最大可能整数值(2147483647)之间的随机整数值,但要将其转换为特定范围内的随机整数或介于 0 和 1 之间的随机浮点数或类似数值也很容易。通常情况下,提供的方法都能做到这一点。
下面的图片是 C# 中的随机类从种子 0 生成的前 65536 个数字。每个随机数代表一个像素,亮度介于 0(黑色)和 1(白色)之间。

重要的是要明白,如果没有获得第一个和第二个随机数,就无法获得第三个随机数。这不仅仅是执行过程中的疏忽。就其本质而言,RNG 在生成每个随机数时,都会将上一个随机数作为计算的一部分。因此,我们谈论的是随机序列。

这就意味着,如果你需要一个接一个的随机数,那么 RNG 是很好的选择,但如果你需要获得一个特定的随机数(比如序列中的第 26 个随机数),那么你就不走运了。你可以调用 Next() 26 次,然后使用最后一个数字,但这是个非常糟糕的主意。
如果一次生成所有内容,可能就不需要序列中的特定随机数,至少我想不出有什么理由。但是,如果你是一点一点地即时生成,那么你就会这样做。
例如,您的世界有三个部分:玩家从 A 区开始,因此 A 区是用 100 个随机数生成的。然后玩家进入 B 部分,该部分由 100 个不同的数字生成。同时销毁生成的 A 部分,以释放内存。玩家进入 C 区,C 区有 100 个不同的数字,B 区被摧毁。
但是,如果玩家现在再次回到 B 部分,为了使该部分看起来相同,它应该生成与第一次相同的 100 个随机数字。
不这是关于 RNG 的一个非常普遍的误解。事实上,虽然同一序列中的不同数字之间的关系是随机的,但不同序列中的相同索引数字之间的关系却不是随机的,即使乍看起来是这样。

因此,如果有 100 个序列,从每个序列中取第一个数字,这些数字之间的关系就不是随机的。如果从每个序列中取第 10 个、第 100 个、第 1000 个数字,效果也不会更好。
在这一点上,有些人会持怀疑态度,这没什么。如果这个问题更可信,您还可以查看Stack Overflow 上关于程序内容 RNG 的问题。不过,为了获得更多有趣的信息,让我们来做一些实验,看看结果如何。
让我们看看从相同序列中生成的数字作为参考,并与从种子 0 到 65535 生成的 65536 个序列中每个序列的第一个数字进行比较。
虽然图案分布比较均匀,但也不完全是随机的。事实上,我已经展示了一个纯线性函数的输出结果以供比较,很明显,使用来自后续种子的数字几乎没有比使用线性函数更好的效果。
不过,这几乎是随机的吗?这还不够好吗?
此时,引入更好的方法来测量随机性可能是个好主意,因为肉眼并不十分可靠。为什么不呢?输出看起来足够随机还不够吗?
是的,归根结底,我们的目标只是让事情看起来足够随机。但随机数的输出结果会因使用方式不同而大相径庭。您的生成算法可能会以各种方式转换随机值,从而揭示出在查看简单序列中列出的值时所隐藏的清晰模式。
检查随机输出的另一种方法是根据随机数对创建二维坐标,并将这些坐标绘制成图像。落在同一像素上的坐标越多,该像素就越亮。
让我们来看看这种坐标图,它既适用于同一序列中的随机数,也适用于用不同种子从单个序列中创建的随机数。对了,还要加上线性函数。
也许令人惊讶的是,当用来自不同种子的随机数创建坐标时,坐标都被绘制成细线,而不是接近均匀分布。这又和线性函数一样。
想象一下,为了在地形上植树,你用随机数创建了坐标。现在,所有的树都会种在一条直线上,剩下的地形都是空的!
我们可以得出结论,随机数发生器只有在不需要按照特定顺序访问数字时才有用。如果是这样,你可能需要研究一下随机散列函数。
一般来说,散列函数是指任何可用于将任意大小的数据映射到固定大小的数据的函数,输入数据的细微差别会导致输出数据的巨大差异。
对于程序生成,典型的用例是提供一个或多个整数作为输入,并得到一个随机数作为输出。例如,对于一次只生成部分内容的大型世界,典型的需求是获取与输入向量(如世界中的位置)相关联的随机数,并且在输入相同的情况下,该随机数应始终保持相同。与随机数生成器(RNG)不同,它没有顺序,您可以按照任何顺序获得随机数。

C# 中的代码可以如下所示--注意,您可以按照任意顺序获取数字:
未知块类型 "codeBlock",请在 "serializers.type "道具中为其指定一个序列化器
哈希函数还可以接受多个输入,这意味着你可以为给定的二维或三维坐标获取一个随机数:
未知块类型 "codeBlock",请在 "serializers.type "道具中为其指定一个序列化器
程序生成并不是散列函数的典型用途,而且并不是所有的散列函数都适合程序生成,因为它们可能没有足够的随机分布,或者过于昂贵。
哈希函数的一个用途是作为哈希表和字典等数据结构的一部分。这些算法通常速度很快,但随机性不够,因为它们的目的不是随机性,而只是让算法高效运行。从理论上讲,这意味着它们也应该是随机的,但在实践中,我还没有找到可以比较这些随机属性的资源,而且我测试过的随机属性都相当糟糕(详见附录 C)。
散列函数的另一个用途是密码学。这些值通常随机性很强,但速度也很慢,因为对加密功能强大的哈希函数的要求远高于对看起来只是随机的值的要求。
我们生成程序的目标是随机哈希函数看起来是随机的,但同时也是高效的,这意味着它不会比需要的速度慢。您所选择的编程语言中很可能没有合适的内置程序,因此您需要在项目中找到一个内置程序。
根据互联网上各个角落的推荐和信息,我测试了几种不同的哈希函数。在此,我选择了其中的三个进行比较。
- PcgHash:我是从亚当-史密斯(Adam Smith)在谷歌群组论坛上关于程序内容生成的讨论中得到这个哈希函数的。Adam 提出,只要掌握一点技巧,创建自己的随机散列函数并不难,并提供了他的 PcgHash 代码片段作为示例。
- MD5:这可能是最著名的散列函数之一。它的加密强度也很高,而且比我们需要的要贵。此外,我们通常只需要一个 32 位的 int 作为返回值,而 MD5 返回的哈希值要大得多,其中大部分都会被我们扔掉。尽管如此,还是值得将其纳入比较范围。
- xxHash:这是一种高性能的现代非加密哈希函数,具有非常好的随机特性和出色的性能。
除了生成噪声序列图像和坐标图外,我还使用名为ENT - 伪随机数序列测试程序的随机性测试套件进行了测试。我在图片中加入了部分 ENT 统计数据以及我自己设计的数据,我称之为 "对角线偏差"。后者查看坐标图中像素对角线的总和,并测量这些总和的标准偏差。
以下是三个哈希函数的结果:

PcgHash 的突出特点是,虽然它在连续随机值的噪声图像中显得非常随机,但坐标图却显示出清晰的模式,这意味着它不能很好地适应简单的变换。由此我得出结论,自己开发随机哈希函数很难,也许应该留给专家去做。
MD5 和 xxHash 的随机属性似乎非常相似,其中 xxHash 的速度要快 50 倍左右。
xxHash 还有一个优点,那就是虽然它不是 RNG,但仍有种子的概念,而不是所有哈希函数都有种子的概念。能够指定种子对于程序生成有明显的优势,因为你可以针对实体、网格单元或类似内容的不同随机属性使用不同的种子,然后直接使用实体索引/单元坐标作为哈希函数的输入。最重要的是,使用 xxHash 时,来自不同种子序列的数字相互之间是随机的(详见附录 2)。
在我对散列函数的研究中,我清楚地认识到,选择一个在通用散列基准测试中表现优异的散列函数固然是件好事,但根据程序生成的需要对其进行优化,而不是原封不动地使用散列函数,这对性能至关重要。
有两个重要的优化措施:
- 避免整数和字节之间的转换。大多数通用哈希函数将字节数组作为输入,并返回一个整数或一些字节作为哈希值。不过,有些性能较高的程序会将输入字节转换为整数,因为它们在内部对整数进行操作。由于程序生成中最常见的是根据整数输入值获取哈希值,因此转换为字节完全没有意义。通过重构对字节的依赖,可以将性能提高三倍,同时使输出结果 100% 相同。
- 实现只接受一个或几个输入的无循环方法。大多数通用哈希函数以数组的形式接收长度可变的输入数据。这对程序生成也很有用,但最常用的可能是根据 1、2 或 3 个输入整数获取哈希值。创建使用固定整数而不是数组的优化方法,可以省去哈希函数中的循环,从而显著提高性能(在我的测试中提高了约 4-5 倍)。我不是低级优化方面的专家,但这种巨大差异可能是由于 for 循环中的隐式分支或需要分配数组造成的。
对于哈希函数,我目前的建议是使用针对程序生成进行了优化的 xxHash 实现。原因详见附录 C。
你可以在 BitBucket 上获得我用 C# 实现的 xxHash 和其他哈希函数。该网站由我在空闲时间私自维护,并非由 Unity Technologies 维护。
除了优化之外,我还添加了额外的方法,以获得指定范围内的整数输出或指定范围内的浮点数输出,这些都是程序生成中的典型需求。
请注意:在撰写本文时,我只在 xxHash 和 MurmurHash3 中添加了单整数输入优化。如果有时间,我还会为两整数和三整数输入添加优化过载。
随机散列函数和随机数生成器也可以结合使用。合理的做法是使用具有不同种子的随机数生成器,但种子要通过随机散列函数,而不是直接使用。
想象一下,你有一个巨大的迷宫世界,可能近乎无限大。这个世界有一个大尺度的网格,每个网格单元都是一个迷宫。玩家在世界中移动时,周围的网格单元会产生迷宫。
在这种情况下,您希望每次进入迷宫时都能以相同的方式生成迷宫,因此所需的随机数必须能够独立于之前生成的数字。
不过,迷宫总是一次生成一个完整的迷宫,因此没有必要控制用于一个迷宫的单个随机数的顺序。
理想的方法是使用随机散列函数,根据迷宫网格单元的坐标为迷宫创建一个种子,然后使用该种子创建一个随机数生成器的随机数序列。

C# 代码可以是这样的
未知块类型 "codeBlock",请在 "serializers.type "道具中为其指定一个序列化器
如果需要控制查询随机数的顺序,可在针对程序生成进行了优化的实现中使用合适的随机散列函数(如 xxHash)。
如果您只需要获取一堆随机数,而顺序并不重要,最简单的方法就是使用随机数生成器,如 C# 中的 System.Random 类。为了使所有数字相互之间都是随机的,要么只使用一个序列(用一个种子初始化),要么如果使用多个种子,则应先通过一个随机哈希函数(如 xxHash)。
本文提到的随机数测试框架以及各种 RNG 和哈希函数的源代码可在 BitBucket 上获取。该网站由我在空闲时间私自维护,并非由 Unity Technologies 维护。
本文最初发表在runevision 博客上,该博客致力于游戏开发和我在闲暇时间所做的研究。
在某些情况下,您希望能够查询连续的噪声值,即输入值相近时,输出值也相近。典型用途是制作地形或纹理。
这些要求与本文讨论的要求完全不同。如果是连续噪声,可以使用 Perlin 噪声,或者更好的 Simplex 噪声。
但要注意的是,这些设备只适用于连续噪音。查询连续噪声函数只是为了获得与其他随机数无关的随机数,结果会很糟糕,因为这不是这些算法的优化目标。例如,我发现在整数位置查询 Simplex Noise 函数时,每三次输入都会返回 0!
此外,连续噪声函数在计算中通常使用浮点数,离原点越远,稳定性和精度越差。
多年来,我听到过各种各样的误解,在此,我想再谈谈其中的一些误解
不,我没有看到任何迹象表明这一点。如果你看一下本文中的测试图片,低种子值和高种子值的结果没有任何区别。
同样,如果您查看测试图像,就会发现随机值序列从开始(左上角,一行接一行)到结束都遵循相同的模式。
在下图中,我测试了 65535 个序列中的第 0 个数字以及这些序列中的第 100 个数字。可以看出,随机性的质量(缺乏随机性)没有明显差异。

也许好了一点点,但还远远不够。与 C# 中的 Random 类不同,Java 中的 Random 类并不直接使用所提供的种子,而是在存储种子之前先将比特位洗牌一下。
不同序列产生的数字看起来可能更随机一些,我们可以从测试统计中看出,序列相关性要好得多。不过,从坐标图中可以明显看出,当用于坐标时,数字仍然会折叠成一条线。

尽管如此,RNG 没有理由不在使用种子前对其应用高质量的随机散列函数。事实上,这样做似乎是个非常好的主意,我想不出有什么坏处。只是据我所知,目前流行的 RNG 实现并不这样做,所以你必须按照之前的描述自己做。
虽然没有内在原因,但 xxHash 和 MurmurHash3 等哈希函数会将种子值与输入值进行类似处理,也就是说,它本质上是对种子应用了高质量的随机哈希函数。因为是这样实现的,所以使用不同种子随机哈希对象中的第 N 个数字是安全的。

在本文的最初版本中,我比较了 PcgHash、MD5 和 MurmurHash3,并推荐使用 MurmurHash3。
MurmurHash3 具有出色的随机性和非常快的速度。作者将其与一个名为SMHasher的哈希函数测试框架并行实施,后者已成为广泛使用的哈希函数测试框架。
在Stack Overflow上的这个问题中也有很好的信息,它对更多的哈希函数进行了比较,似乎对 MurmurHash 同样有利。
文章发表后,Aras Pranckevičius 建议我研究一下 xxHash,Nathan Reed 则建议我研究一下 Wang Hash,他在这里写了一篇关于 Wang Hash 的文章。
xxHash 是一种散列函数,在 SMHasher 测试框架中的质量得分与 MurmurHash 不相上下,而性能却明显优于 MurmurHash。有关xxHash 的更多信息,请访问 Google 代码页面。
在我取消字节转换后的初步实现中,它比 MurmurHash3 稍微快一些,但没有 SMHasher 结果显示的那么快。
我还实现了 WangHash。由于它在坐标图中显示了明显的模式,因此证明质量不够高,但它比 xxHash 快 5 倍多。我试着实现了一个 "WangDoubleHash",它的结果会反馈给自己,在我的测试中,它的质量很好,速度仍然比 xxHash 快三倍多。
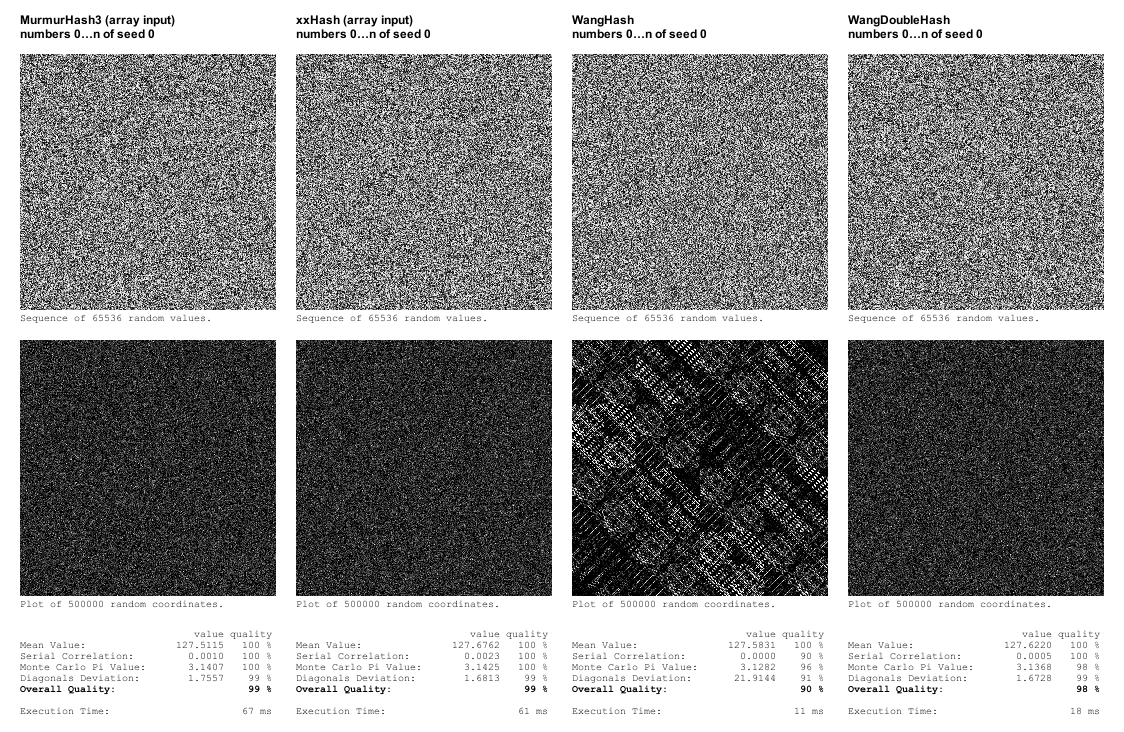
不过,由于 WangHash(和 WangDoubleHash)只将单个整数作为输入,因此我选择同时实现单输入版本的 xxHash 和 MurmurHash3,看看对性能会有什么影响。事实证明,它大大提高了性能(大约快了 4-5 倍)。事实上,xxHash 现在比 WangDoubleHash 更快。

至于质量,我自己的测试框架暴露出了相当明显的缺陷,但远不及SMHasher测试框架复杂,因此可以认为,在SMHasher测试框架中得分较高的哈希函数,其随机性属性的质量要好于在我自己的测试中表现良好的哈希函数。一般来说,通过我的测试框架中的测试可能就足以满足程序生成的目的,但由于 xxHash(优化版本)是通过我自己测试的最快的哈希函数,因此使用它是不费吹灰之力的。
市面上有非常多不同的哈希函数,我们还可以加入更多的哈希函数进行比较。不过,我主要关注的是一些公认的随机性质量和性能最佳的程序,然后针对程序生成对它们进行了进一步优化。
我认为这个版本的 xxHash 所产生的结果已经相当接近最佳状态,如果要找到并使用更好的版本,进一步的收益可能会很小。尽管如此,您也可以扩展测试框架,实现更多的功能。