Un abécédaire des nombres aléatoires répétables


Dans cet article, nous utiliserons la génération de niveaux et de mondes dans les jeux comme exemple de cas d'utilisation, mais les leçons sont applicables à beaucoup d'autres choses, comme les textures procédurales, les modèles, la musique, etc. Ils ne sont toutefois pas conçus pour des applications aux exigences très strictes, telles que la cryptographie.
Pourquoi voudriez-vous répéter le même résultat plus d'une fois ?
- Possibilité de revisiter le même niveau/monde. Par exemple, un certain niveau/monde peut être créé à partir d'une graine spécifique. Si la même graine est utilisée à nouveau, vous obtiendrez à nouveau le même niveau/monde. Vous pouvez par exemple le faire dans Minecraft.
- Monde persistant généré à la volée. Si vous avez un monde généré à la volée au fur et à mesure que le joueur s'y déplace, vous voudrez peut-être que les lieux restent les mêmes la première fois que le joueur les visite et les fois suivantes (comme dans Minecraft, le prochain jeu No Man's Sky et d'autres), plutôt que d'être différents à chaque fois, comme s'il s'agissait d'une logique onirique.
- Le même monde pour tous. Peut-être voulez-vous que votre univers de jeu soit le même pour tous ceux qui y jouent, exactement comme s'il n'était pas généré de manière procédurale. C'est par exemple le cas dans No Man's Sky. Il s'agit essentiellement de la même chose que la possibilité de revisiter le même niveau/monde mentionnée ci-dessus, sauf que la même graine est toujours utilisée.
Nous avons mentionné le mot " semence" à plusieurs reprises. Une graine peut être un nombre, une chaîne de texte ou toute autre donnée utilisée en entrée pour obtenir une sortie aléatoire. Le trait caractéristique d'une graine est que la même graine produira toujours le même résultat, mais que la moindre modification de la graine peut produire un résultat complètement différent.
Dans cet article, nous examinerons deux méthodes différentes de production de nombres aléatoires - les générateurs de nombres aléatoires et les fonctions de hachage aléatoire - et les raisons d'utiliser l'une ou l'autre. Les connaissances que j'ai acquises à ce sujet sont durement acquises et ne semblent pas être facilement disponibles ailleurs, c'est pourquoi j'ai pensé qu'il serait bon de les mettre par écrit et de les partager.
La façon la plus courante de produire des nombres aléatoires est d'utiliser un générateur de nombres aléatoires (ou RNG). De nombreux langages de programmation intègrent des classes ou des méthodes de RNG, et le mot "aléatoire" figure dans leur nom.
Un générateur de nombres aléatoires produit une séquence de nombres aléatoires sur la base d'une graine initiale. Dans les langages orientés objet, un générateur de nombres aléatoires est généralement un objet initialisé avec une graine. Une méthode de cet objet peut alors être appelée à plusieurs reprises pour produire des nombres aléatoires.

Le code en C# pourrait ressembler à ceci :
Type de bloc inconnu "codeBlock", veuillez spécifier un sérialiseur pour ce type dans la propriété `serializers.types`.
Dans ce cas, nous obtenons des valeurs entières aléatoires comprises entre 0 et la valeur entière maximale possible (2147483647), mais il est trivial de convertir cela en un nombre entier aléatoire dans une plage spécifique, ou en un nombre à virgule flottante aléatoire compris entre 0 et 1 ou similaire. Il existe souvent des méthodes qui permettent d'effectuer cette opération dès le départ.
Voici une image avec les 65536 premiers nombres générés par la classe Random en C# à partir de la graine 0. Chaque nombre aléatoire est représenté par un pixel dont la luminosité est comprise entre 0 (noir) et 1 (blanc).

Il est important de comprendre ici que vous ne pouvez pas obtenir le troisième numéro aléatoire sans avoir d'abord obtenu le premier et le deuxième. Il ne s'agit pas seulement d'un oubli dans la mise en œuvre. De par sa nature même, un RNG génère chaque nombre aléatoire en utilisant le nombre aléatoire précédent comme élément de calcul. On parle donc d'une séquence aléatoire.

Cela signifie que les RNG sont parfaits si vous avez besoin d'un tas de nombres aléatoires l'un après l'autre, mais si vous avez besoin d'obtenir un nombre aléatoire spécifique (par exemple, le 26e nombre aléatoire de la séquence), alors vous n'avez pas de chance. Vous pourriez appeler Next() 26 fois et utiliser le dernier chiffre, mais c'est une très mauvaise idée.
Si vous générez tout en une seule fois, vous n'avez probablement pas besoin de nombres aléatoires spécifiques à partir d'une séquence, ou du moins je ne vois pas de raison. Cependant, si vous générez les choses petit à petit à la volée, c'est le cas.
Par exemple, supposons que votre monde comporte trois sections : A, B et C. Le joueur commence dans la section A, qui est donc générée à l'aide de 100 nombres aléatoires. Le joueur passe ensuite à la section B qui est générée à partir de 100 numéros différents. La section A générée est détruite en même temps pour libérer de la mémoire. Le joueur passe à la section C qui compte 100 numéros différents et la section B est détruite.
Cependant, si le joueur revient à la section B, celle-ci doit être générée avec les mêmes 100 numéros aléatoires que la première fois afin que la section ait la même apparence.
Non ! Il s'agit d'une idée fausse très répandue au sujet des RNG. En effet, si les différents nombres d'une même séquence sont aléatoires les uns par rapport aux autres, les mêmes nombres indexés de différentes séquences ne sont pas aléatoires les uns par rapport aux autres, même si cela semble être le cas à première vue.

Ainsi, si vous avez 100 séquences et que vous prenez le premier chiffre de chacune d'entre elles, ces chiffres ne seront pas aléatoires les uns par rapport aux autres. Et ce ne sera pas mieux si vous prenez le 10e, le 100e, le 1000e nombre de chaque séquence.
À ce stade, certains seront sceptiques, et c'est très bien ainsi. Vous pouvez également consulter cette question de Stack Overflow sur le RNG pour le contenu procédural, si vous êtes plus sûr de vous. Mais pour un peu plus d'amusement et d'information, faisons quelques expériences et regardons les résultats.
Examinons les nombres générés à partir de la même séquence à titre de référence et comparons-les aux nombres créés en obtenant le premier chiffre de chacune des 65536 séquences créées à partir des graines 0 à 65535.
Bien que la répartition soit plutôt uniforme, elle n'est pas tout à fait aléatoire. En fait, j'ai montré le résultat d'une fonction purement linéaire à des fins de comparaison, et il est évident que l'utilisation de nombres provenant de graines ultérieures est à peine meilleure que l'utilisation d'une fonction linéaire.
Mais est-ce que c'est presque un hasard ? Est-ce suffisant?
À ce stade, il peut être judicieux d'introduire de meilleurs moyens de mesurer le caractère aléatoire, car l'œil nu n'est pas très fiable. Pourquoi pas ? Ne suffit-il pas que le résultat soit suffisamment aléatoire ?
Oui, en fin de compte, notre objectif est simplement de faire en sorte que les choses aient l'air suffisamment aléatoires. Mais la sortie des nombres aléatoires peut être très différente selon la manière dont elle est utilisée. Vos algorithmes de génération peuvent transformer les valeurs aléatoires de toutes sortes de manières qui révèleront des modèles clairs qui sont cachés lorsqu'on inspecte simplement les valeurs énumérées dans une séquence simple.
Une autre façon d'inspecter les résultats aléatoires consiste à créer des coordonnées 2D à partir de paires de nombres aléatoires et à tracer ces coordonnées sur une image. Plus il y a de coordonnées sur le même pixel, plus ce pixel devient lumineux.
Examinons un tel diagramme de coordonnées pour des nombres aléatoires de la même séquence et pour des nombres aléatoires créés à partir de séquences individuelles avec des graines différentes. Oh, et ajoutons aussi la fonction linéaire.
Il est peut-être surprenant de constater que lorsque l'on crée des coordonnées à partir de nombres aléatoires provenant de différentes graines, les coordonnées sont toutes tracées sous forme de lignes fines au lieu d'être distribuées de façon presque uniforme. Il en va de même pour une fonction linéaire.
Imaginez que vous créiez des coordonnées à partir de nombres aléatoires afin de planter des arbres sur un terrain. Désormais, tous les arbres seront plantés en ligne droite et le reste du terrain sera vide !
Nous pouvons en conclure que les générateurs de nombres aléatoires ne sont utiles que si vous n'avez pas besoin d'accéder aux nombres dans un ordre spécifique. Si c'est le cas, vous pouvez vous intéresser aux fonctions de hachage aléatoire.
En général, une fonction de hachage est une fonction qui peut être utilisée pour faire correspondre des données de taille arbitraire à des données de taille fixe, de légères différences dans les données d'entrée produisant de très grandes différences dans les données de sortie.
Pour la génération procédurale, les cas d'utilisation typiques consistent à fournir un ou plusieurs nombres entiers en entrée et à obtenir un nombre aléatoire en sortie. Par exemple, pour les grands mondes où seules des parties sont générées à la fois, un besoin typique est d'obtenir un nombre aléatoire associé à un vecteur d'entrée (tel qu'un emplacement dans le monde), et ce nombre aléatoire doit toujours être le même pour la même entrée. Contrairement aux générateurs de nombres aléatoires (RNG), il n'y a pas de séquence - vous pouvez obtenir les nombres aléatoires dans l'ordre que vous souhaitez.

Le code en C# pourrait ressembler à ceci - notez que vous pouvez obtenir les nombres dans l'ordre que vous souhaitez :
Type de bloc inconnu "codeBlock", veuillez spécifier un sérialiseur pour ce type dans la propriété `serializers.types`.
La fonction de hachage peut également prendre plusieurs entrées, ce qui signifie que vous pouvez obtenir un nombre aléatoire pour une coordonnée 2D ou 3D donnée :
Type de bloc inconnu "codeBlock", veuillez spécifier un sérialiseur pour ce type dans la propriété `serializers.types`.
La génération de procédures n'est pas l'utilisation typique des fonctions de hachage, et toutes les fonctions de hachage ne sont pas bien adaptées à la génération de procédures, car elles peuvent soit ne pas avoir une distribution suffisamment aléatoire, soit être inutilement coûteuses.
Les fonctions de hachage sont notamment utilisées dans le cadre de la mise en œuvre de structures de données telles que les tables de hachage et les dictionnaires. Ils sont souvent rapides mais pas suffisamment aléatoires, car ils ne sont pas destinés à l'aléatoire mais simplement à rendre les algorithmes efficaces. En théorie, cela signifie qu'ils devraient également être aléatoires, mais en pratique, je n'ai pas trouvé de ressources qui comparent les propriétés aléatoires de ces derniers, et ceux que j'ai testés se sont avérés avoir des propriétés aléatoires assez mauvaises (voir l'annexe C pour plus de détails).
La fonction de hachage est également utilisée pour la cryptographie. Ces fonctions sont souvent très aléatoires, mais elles sont également lentes, car les exigences en matière de fonctions de hachage cryptographiquement fortes sont beaucoup plus élevées que pour des valeurs qui semblent simplement aléatoires.
Pour la génération de procédures, notre objectif est d'obtenir une fonction de hachage aléatoire qui semble aléatoire mais qui est également efficace, c'est-à-dire qui n'est pas plus lente qu'elle ne doit l'être. Il y a de fortes chances qu'il n'y en ait pas d'intégré dans le langage de programmation de votre choix et que vous deviez en trouver un pour l'inclure dans votre projet.
J'ai testé plusieurs fonctions de hachage différentes sur la base de recommandations et d'informations provenant de divers coins d'Internet. J'en ai sélectionné trois à titre de comparaison.
- PcgHash: Cette fonction de hachage m'a été suggérée par Adam Smith lors d'une discussion sur le forum Google Groups sur la génération de contenu procédural. Adam a proposé qu'avec un peu d'habileté, il n'est pas trop difficile de créer sa propre fonction de hachage aléatoire et a offert son extrait de code PcgHash en guise d'exemple.
- MD5: Il s'agit sans doute de l'une des fonctions de hachage les plus connues. Il a également une force cryptographique et est plus coûteux qu'il ne devrait l'être pour nos besoins. De plus, nous n'avons généralement besoin que d'un int de 32 bits comme valeur de retour, alors que MD5 renvoie une valeur de hachage beaucoup plus importante, dont la plus grande partie serait simplement jetée. Néanmoins, il vaut la peine de l'inclure à des fins de comparaison.
- xxHash: Il s'agit d'une fonction de hachage moderne non cryptographique très performante qui présente à la fois de très bonnes propriétés aléatoires et d'excellentes performances.
Outre la génération d'images de séquences de bruit et de diagrammes de coordonnées, j'ai également effectué des tests avec une suite de tests aléatoires appelée ENT - A Pseudorandom Number Sequence Test Program (Programme de test de séquences de nombres pseudo-aléatoires). J'ai inclus certaines statistiques ENT dans les images ainsi qu'une statistique que j'ai conçue moi-même et que j'appelle l'écart diagonal. Ce dernier examine les sommes des lignes diagonales de pixels du diagramme de coordonnées et mesure l'écart type de ces sommes.
Voici les résultats des trois fonctions de hachage :

PcgHash se distingue par le fait que, bien qu'il apparaisse très aléatoire dans les images de bruit des valeurs aléatoires séquentielles, le tracé des coordonnées révèle des modèles clairs, ce qui signifie qu'il ne résiste pas bien à des transformations simples. J'en conclus que créer sa propre fonction de hachage aléatoire est difficile et devrait probablement être laissé aux experts.
MD5 et xxHash semblent avoir des propriétés aléatoires très comparables, et parmi celles-ci, xxHash est environ 50 fois plus rapide.
xxHash présente également l'avantage, bien qu'il ne s'agisse pas d'un RNG, de conserver le concept de graine, ce qui n'est pas le cas de toutes les fonctions de hachage. Le fait de pouvoir spécifier une graine présente des avantages évidents pour la génération procédurale, puisque vous pouvez utiliser différentes graines pour différentes propriétés aléatoires d'entités, de cellules de la grille, ou similaires, et ensuite simplement utiliser l'index de l'entité / la coordonnée de la cellule comme entrée pour la fonction de hachage telle quelle. Il est important de noter qu'avec xxHash, les nombres provenant de différentes séquences sont aléatoires les uns par rapport aux autres (voir l'annexe 2 pour plus de détails).
Au cours de mes recherches sur les fonctions de hachage, il est apparu clairement que s'il est bon de choisir une fonction de hachage très performante dans les benchmarks de hachage à usage général, il est crucial pour les performances de l'optimiser en fonction des besoins de la génération procédurale plutôt que de l'utiliser en l'état.
Il y a deux optimisations importantes :
- Éviter les conversions entre entiers et octets. La plupart des fonctions de hachage d'usage général prennent en entrée un tableau d'octets et renvoient un entier ou quelques octets comme valeur de hachage. Cependant, certains des plus performants convertissent les octets d'entrée en nombres entiers, puisqu'ils opèrent sur des nombres entiers en interne. Étant donné que la génération procédurale obtient le plus souvent un hachage basé sur des valeurs d'entrée entières, la conversion en octets est totalement inutile. En supprimant la dépendance à l'égard des octets, il est possible de tripler les performances tout en conservant un résultat identique à 100 %.
- Mettre en œuvre des méthodes sans boucle qui ne prennent qu'une ou quelques entrées. La plupart des fonctions de hachage d'usage général prennent en entrée des données de longueur variable sous la forme d'un tableau. Ceci est également utile pour la génération procédurale, mais les utilisations les plus courantes sont probablement pour obtenir un hachage basé sur seulement 1, 2 ou 3 entiers d'entrée. La création de méthodes optimisées qui prennent un nombre fixe d'entiers plutôt qu'un tableau peut éliminer la nécessité d'une boucle dans la fonction de hachage, ce qui peut améliorer considérablement les performances (d'environ 4 à 5 fois dans mes tests). Je ne suis pas un expert en optimisation de bas niveau, mais la différence spectaculaire pourrait être due à un branchement implicite dans la boucle for ou à la nécessité d'allouer un tableau.
Ma recommandation actuelle pour une fonction de hachage est d'utiliser une implémentation de xxHash optimisée pour la génération procédurale. Voir l'annexe C pour plus de détails.
Vous pouvez obtenir mes implémentations de xxHash et d'autres fonctions de hachage en C# sur BitBucket. Ce site est maintenu en privé par moi pendant mon temps libre, et non par Unity Technologies.
Outre les optimisations, j'ai également ajouté des méthodes supplémentaires pour obtenir la sortie sous la forme d'un nombre entier dans un intervalle spécifié ou d'un nombre à virgule flottante dans un intervalle spécifié, qui sont des besoins typiques de la génération procédurale.
Remarque : Au moment où j'écris ces lignes, je n'ai ajouté qu'une optimisation de l'entrée d'un seul entier à xxHash et MurmurHash3. J'ajouterai des surcharges optimisées pour les entrées à deux et trois entiers lorsque j'aurai le temps.
Les fonctions de hachage aléatoire et les générateurs de nombres aléatoires peuvent également être combinés. Une approche judicieuse consiste à utiliser des générateurs de nombres aléatoires avec des graines différentes, mais dont les graines sont passées par une fonction de hachage aléatoire au lieu d'être utilisées directement.
Imaginez que vous disposiez d'un vaste monde labyrinthique, peut-être presque infini. Le monde a une grille à grande échelle où chaque cellule est un labyrinthe. Lorsque le joueur se déplace dans le monde, des labyrinthes sont générés dans les cellules de la grille qui l'entourent.
Dans ce cas, vous voudrez que chaque labyrinthe soit toujours généré de la même manière à chaque fois qu'il est visité, de sorte que les nombres aléatoires nécessaires à cette fin doivent pouvoir être produits indépendamment des nombres générés précédemment.
Cependant, les labyrinthes sont toujours générés un par un, il n'est donc pas nécessaire de contrôler l'ordre des nombres aléatoires individuels utilisés pour un labyrinthe.
L'approche idéale consiste à utiliser une fonction de hachage aléatoire pour créer une graine pour un labyrinthe sur la base des coordonnées de la cellule de la grille du labyrinthe, puis à utiliser cette graine pour une séquence de nombres aléatoires générée par un générateur de nombres aléatoires.

Le code C# pourrait ressembler à ceci :
Type de bloc inconnu "codeBlock", veuillez spécifier un sérialiseur pour ce type dans la propriété `serializers.types`.
Si vous avez besoin de contrôler l'ordre d'interrogation des nombres aléatoires, utilisez une fonction de hachage aléatoire appropriée (telle que xxHash) dans une implémentation optimisée pour la génération procédurale.
Si vous avez simplement besoin d'obtenir une série de nombres aléatoires et que l'ordre n'a pas d'importance, la méthode la plus simple consiste à utiliser un générateur de nombres aléatoires tel que la classe System.Random en C#. Pour que tous les nombres soient aléatoires les uns par rapport aux autres, il convient soit d'utiliser une seule séquence (initialisée avec une seule graine), soit, si plusieurs graines sont utilisées, de les faire passer d'abord par une fonction de hachage aléatoire (telle que xxHash).
Le code source du cadre de test des nombres aléatoires mentionné dans cet article, ainsi qu'une variété de RNG et de fonctions de hachage, est disponible sur BitBucket. Ce site est maintenu en privé par moi pendant mon temps libre, et non par Unity Technologies.
Cet article a été publié à l'origine sur le blog runevision, qui est consacré au développement de jeux et aux recherches que j'effectue pendant mon temps libre.
Pour certaines choses, vous voudrez être en mesure d'interroger des valeurs de bruit continues, c'est-à-dire que des valeurs d'entrée proches les unes des autres produisent des valeurs de sortie également proches les unes des autres. Les utilisations typiques sont les terrains ou les textures.
Ces exigences sont complètement différentes de celles présentées dans cet article. Pour le bruit continu, examinez le bruit Perlin ou, mieux encore, le bruit Simplex.
Toutefois, il faut savoir que ces derniers ne conviennent que pour un bruit continu. L'interrogation de fonctions de bruit continu dans le seul but d'obtenir des nombres aléatoires sans rapport avec d'autres nombres aléatoires produira des résultats médiocres, car ce n'est pas pour cela que ces algorithmes sont optimisés. Par exemple, j'ai découvert que l'interrogation d'une fonction Simplex Noise à des positions entières renvoie 0 toutes les trois entrées !
En outre, les fonctions de bruit continu utilisent généralement des nombres à virgule flottante dans leurs calculs, dont la stabilité et la précision diminuent à mesure que l'on s'éloigne de l'origine.
J'ai entendu plusieurs idées fausses au fil des ans et je vais essayer d'en aborder quelques-unes ici.
Non, je n'ai rien vu qui l'indique. Si vous regardez les images test dans cet article, il n'y a pas de différence entre les résultats pour des valeurs de semences faibles ou élevées.
Non. Encore une fois, si vous regardez les images de test, vous pouvez voir que les séquences de valeurs aléatoires suivent le même modèle du début (coin supérieur gauche et une ligne après l'autre) jusqu'à la fin.
Dans l'image ci-dessous, j'ai testé le 0e chiffre dans 65535 séquences ainsi que le 100e chiffre dans ces mêmes séquences. Comme on peut le constater, il n'y a pas de différence significative apparente dans la qualité (ou l'absence de qualité) du hasard.

Peut-être un tout petit peu mieux, mais pas assez. Contrairement à la classe Random en C#, la classe Random en Java n'utilise pas la graine fournie telle quelle, mais mélange les bits avant de stocker la graine.
Les nombres résultant de différentes séquences peuvent être un peu plus aléatoires, et nous pouvons voir dans les statistiques du test que la corrélation sérielle est bien meilleure. Cependant, le graphique des coordonnées montre clairement que les nombres se réduisent toujours à une seule ligne lorsqu'ils sont utilisés pour les coordonnées.

Cela dit, il n'y a aucune raison pour qu'un RNG ne puisse pas appliquer une fonction de hachage aléatoire de haute qualité à la graine avant de l'utiliser. En fait, cela semble être une très bonne idée, sans aucun inconvénient à mon sens. C'est juste que les implémentations RNG populaires que je connais ne le font pas, donc vous devrez le faire vous-même comme décrit précédemment.
Il n'y a pas de raison intrinsèque, mais les fonctions de hachage telles que xxHash et MurmurHash3 traitent la valeur de la graine de la même manière que les entrées, ce qui signifie qu'elles appliquent essentiellement une fonction de hachage aléatoire de haute qualité à la graine, pour ainsi dire. Parce qu'il est implémenté de cette manière, il est sûr d'utiliser le Nième nombre d'objets de hachage aléatoire semés différemment.

Dans la version originale de cet article, j'ai comparé PcgHash, MD5 et MurmurHash3 et j'ai recommandé d'utiliser MurmurHash3.
MurmurHash3 possède d'excellentes propriétés aléatoires et une vitesse très décente. L'auteur l'a mis en œuvre parallèlement à un cadre de test des fonctions de hachage appelé SMHasher, qui est devenu un cadre largement utilisé à cette fin.
Cette question de Stack Overflow sur les bonnes fonctions de hachage pour l'unicité et la vitesse contient également de bonnes informations qui comparent un grand nombre de fonctions de hachage et semblent brosser un tableau tout aussi favorable de MurmurHash.
Après avoir publié l'article, Aras Pranckevičius m'a recommandé d'étudier xxHash et Nathan Reed m'a recommandé d'étudier Wang Hash, sur lequel il a écrit ici.
xxHash est une fonction de hachage qui bat apparemment MurmurHash sur son propre terrain en obtenant un score de qualité aussi élevé dans le cadre de test SMHasher tout en ayant des performances nettement supérieures. Pour en savoir plus sur xxHash, consultez sa page Google Code.
Dans mon implémentation initiale, après avoir supprimé les conversions d'octets, il était légèrement plus rapide que MurmurHash3, mais pas autant que les résultats de SMHasher.
J'ai également mis en œuvre WangHash. La qualité s'est avérée insuffisante, car elle présentait des schémas clairs dans le tracé des coordonnées, mais elle était plus de cinq fois plus rapide que xxHash. J'ai essayé d'implémenter un "WangDoubleHash" dont le résultat est renvoyé à lui-même, et cela a donné de bons résultats dans mes tests, tout en étant trois fois plus rapide que xxHash.
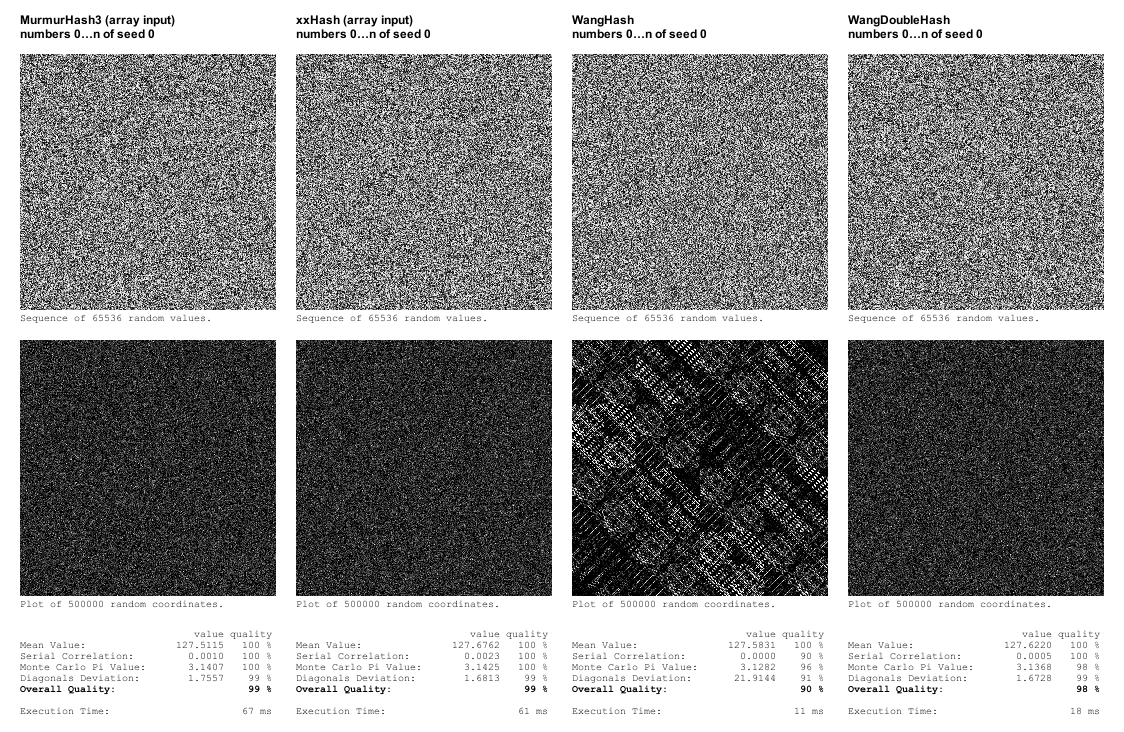
Cependant, comme WangHash (et WangDoubleHash) ne prend qu'un seul entier en entrée, j'ai choisi d'implémenter également des versions à entrée unique de xxHash et MurmurHash3 pour voir l'effet que cela aurait sur les performances. Et il s'est avéré que cela améliorait considérablement les performances (environ 4 à 5 fois plus rapide). À tel point que xxHash est désormais plus rapide que WangDoubleHash.

En ce qui concerne la qualité, mon propre cadre de test révèle des défauts assez évidents, mais il est loin d'être aussi sophistiqué que le cadre de test SMHasher, de sorte qu'une fonction de hachage qui obtient un score élevé dans ce cadre peut être considérée comme un meilleur label de qualité pour les propriétés aléatoires que le simple fait d'avoir l'air bien dans mes propres tests. En général, je dirais que passer les tests dans mon cadre de test peut être suffisant pour la génération de procédures, mais puisque xxHash (dans sa version optimisée) est la fonction de hachage la plus rapide qui passe mes propres tests de toute façon, il n'y a pas de problème à l'utiliser.
Il existe un très grand nombre de fonctions de hachage différentes et il serait toujours possible d'en inclure encore plus à des fins de comparaison. Cependant, je me suis principalement concentré sur les plus performants, largement reconnus, en termes de qualité de l'aléatoire et de performance, et je les ai ensuite optimisés pour la génération procédurale.
Je pense que les résultats obtenus avec cette version de xxHash sont assez proches de l'optimum et que les gains supplémentaires obtenus en trouvant et en utilisant quelque chose d'encore meilleur seront probablement faibles. Cela dit, n'hésitez pas à étendre le cadre de test avec d'autres implémentations.