Uma cartilha sobre números aleatórios repetíveis


Neste artigo, usaremos a geração de níveis/mundo em jogos como exemplo de casos de uso, mas as lições são aplicáveis a muitas outras coisas, como texturas procedurais, modelos, música etc. No entanto, eles não se destinam a aplicativos com requisitos muito rigorosos, como criptografia.
Por que você gostaria de repetir o mesmo resultado mais de uma vez?
- Capacidade de revisitar o mesmo nível/mundo. Por exemplo, um determinado nível/mundo pode ser criado a partir de uma semente específica. Se a mesma semente for usada novamente, você obterá o mesmo nível/mundo novamente. Você pode, por exemplo, fazer isso no Minecraft.
- Mundo persistente que é gerado em tempo real. Se você tiver um mundo que é gerado instantaneamente à medida que o jogador se move nele, talvez queira que os locais permaneçam os mesmos na primeira e nas próximas vezes que o jogador visitar esses locais (como no Minecraft, no próximo jogo No Man's Sky e outros), em vez de serem diferentes a cada vez, como se fossem movidos pela lógica dos sonhos.
- O mesmo mundo para todos. Talvez você queira que o mundo do seu jogo seja o mesmo para todos que o jogam, exatamente como se não tivesse sido gerado processualmente. Esse é o caso, por exemplo, do No Man's Sky. Isso é essencialmente o mesmo que a capacidade de revisitar o mesmo nível/mundo mencionado acima, exceto pelo fato de que a mesma semente é sempre usada.
Já mencionamos a palavra semente algumas vezes. Uma semente pode ser um número, uma cadeia de texto ou outros dados que são usados como entrada para obter um resultado aleatório. A característica que define uma semente é que a mesma semente sempre produzirá o mesmo resultado, mas até mesmo a menor alteração na semente pode produzir um resultado completamente diferente.
Neste artigo, examinaremos duas maneiras diferentes de produzir números aleatórios - geradores de números aleatórios e funções de hash aleatórias - e os motivos para usar uma ou outra. As coisas que sei sobre esse assunto foram adquiridas com muito esforço e não parecem estar prontamente disponíveis em outros lugares, por isso achei que seria bom escrevê-las e compartilhá-las.
A maneira mais comum de produzir números aleatórios é usar um gerador de números aleatórios (ou RNG, na sigla em inglês). Muitas linguagens de programação têm classes ou métodos RNG incluídos e têm a palavra "aleatório" em seu nome, portanto, é a abordagem óbvia para começar a usar números aleatórios.
Um gerador de números aleatórios produz uma sequência de números aleatórios com base em uma semente inicial. Em linguagens orientadas a objetos, um gerador de números aleatórios é normalmente um objeto inicializado com uma semente. Um método nesse objeto pode então ser chamado repetidamente para produzir números aleatórios.

O código em C# poderia ter a seguinte aparência:
Tipo de bloco desconhecido "codeBlock", especifique um serializador para ele na propriedade `serializers.types`.
Nesse caso, estamos obtendo valores inteiros aleatórios entre 0 e o valor inteiro máximo possível (2147483647), mas é trivial converter isso em um número inteiro aleatório em um intervalo específico, ou em um número de ponto flutuante aleatório entre 0 e 1 ou similar. Em geral, são fornecidos métodos que fazem isso imediatamente.
Aqui está uma imagem com os primeiros 65536 números gerados pela classe Random em C# a partir da semente 0. Cada número aleatório é representado como um pixel com um brilho entre 0 (preto) e 1 (branco).

É importante entender aqui que não é possível obter o terceiro número aleatório sem antes obter o primeiro e o segundo. Isso não é apenas um descuido na implementação. Em sua própria natureza, um RNG gera cada número aleatório usando o número aleatório anterior como parte do cálculo. Por isso, falamos de uma sequência aleatória.

Isso significa que os RNGs são ótimos se você precisar de vários números aleatórios, um após o outro, mas se precisar obter um número aleatório específico (por exemplo, o 26º número aleatório da sequência), você não terá sorte. Bem, você poderia chamar Next() 26 vezes e usar o último número, mas essa é uma ideia muito ruim.
Se você gerar tudo de uma vez, provavelmente não precisará de números aleatórios específicos de uma sequência, ou pelo menos não consigo pensar em um motivo. No entanto, se você gerar as coisas pouco a pouco, você o faz.
Por exemplo, digamos que você tenha três seções no seu mundo: A, B e C. O jogador começa na seção A, portanto, a seção A é gerada usando 100 números aleatórios. Em seguida, o jogador passa para a seção B, que é gerada usando 100 números diferentes. A seção A gerada é destruída ao mesmo tempo para liberar memória. O jogador prossegue para a seção C, que tem 100 números diferentes, e a seção B é destruída.
No entanto, se o jogador voltar à seção B novamente, ela deverá ser gerada com os mesmos 100 números aleatórios da primeira vez para que a seção tenha a mesma aparência.
Não! Essa é uma concepção errônea muito comum sobre RNGs. O fato é que, embora os diferentes números da mesma sequência sejam aleatórios em relação uns aos outros, os mesmos números indexados de diferentes sequências não são aleatórios em relação uns aos outros, mesmo que isso possa parecer à primeira vista.

Portanto, se você tiver 100 sequências e pegar o primeiro número de cada uma, esses números não serão aleatórios em relação uns aos outros. E não será melhor se você pegar o 10º, 100º, 1000º número de cada sequência.
Nesse ponto, algumas pessoas serão céticas, e isso não tem problema. Você também pode dar uma olhada nesta pergunta do Stack Overflow sobre RNG para conteúdo procedural, se for mais confiável. Mas para algo um pouco mais divertido e informativo, vamos fazer alguns experimentos e ver os resultados.
Vamos dar uma olhada nos números gerados a partir da mesma sequência para referência e comparar com os números criados ao obter o primeiro número de cada uma das 65536 sequências criadas a partir das sementes de 0 a 65535.
Embora o padrão seja distribuído de maneira bastante uniforme, ele não é totalmente aleatório. De fato, mostrei o resultado de uma função puramente linear para comparação, e é evidente que o uso de números de sementes subsequentes não é melhor do que o uso de uma função linear.
Ainda assim, é quase aleatório? É bom o suficiente?
Nesse ponto, pode ser uma boa ideia introduzir maneiras melhores de medir a aleatoriedade, já que o olho nu não é muito confiável. Por que não? Não é suficiente que o resultado pareça suficientemente aleatório?
Bem, sim, no final, nosso objetivo é simplesmente que as coisas pareçam suficientemente aleatórias. Mas a saída de números aleatórios pode ter uma aparência muito diferente, dependendo de como é usada. Seus algoritmos de geração podem transformar os valores aleatórios de todas as formas que revelarão padrões claros que estão ocultos quando se inspeciona apenas os valores listados em uma sequência simples.
Uma maneira alternativa de inspecionar a saída aleatória é criar coordenadas 2D a partir de pares de números aleatórios e plotar essas coordenadas em uma imagem. Quanto mais coordenadas pousarem no mesmo pixel, mais brilhante esse pixel ficará.
Vamos dar uma olhada nesse gráfico de coordenadas para números aleatórios na mesma sequência e para números aleatórios criados a partir de sequências individuais com sementes diferentes. Ah, e vamos incluir também a função linear.
Talvez surpreendentemente, ao criar coordenadas a partir de números aleatórios de diferentes sementes, todas as coordenadas são plotadas em linhas finas em vez de serem distribuídas de maneira uniforme. Novamente, isso é como em uma função linear.
Imagine que você criou coordenadas a partir de números aleatórios para plantar árvores em um terreno. Agora todas as suas árvores seriam plantadas em linha reta e o terreno restante ficaria vazio!
Podemos concluir que os geradores de números aleatórios só são úteis se não for necessário acessar os números em uma ordem específica. Se for esse o caso, talvez você queira dar uma olhada nas funções de hash aleatórias.
Em geral, uma função de hash é qualquer função que possa ser usada para mapear dados de tamanho arbitrário para dados de tamanho fixo, com pequenas diferenças nos dados de entrada produzindo diferenças muito grandes nos dados de saída.
Para a geração de procedimentos, os casos de uso típicos são fornecer um ou mais números inteiros como entrada e obter um número aleatório como saída. Por exemplo, para mundos grandes em que apenas partes são geradas de cada vez, uma necessidade típica é obter um número aleatório associado a um vetor de entrada (como um local no mundo), e esse número aleatório deve ser sempre o mesmo com a mesma entrada. Ao contrário dos geradores de números aleatórios (RNGs), não há sequência - você pode obter os números aleatórios na ordem que quiser.

O código em C# poderia ter a seguinte aparência - observe que você pode obter os números em qualquer ordem que desejar:
Tipo de bloco desconhecido "codeBlock", especifique um serializador para ele na propriedade `serializers.types`.
A função hash também pode receber várias entradas, o que significa que você pode obter um número aleatório para uma determinada coordenada 2D ou 3D:
Tipo de bloco desconhecido "codeBlock", especifique um serializador para ele na propriedade `serializers.types`.
A geração de procedimentos não é o uso típico das funções de hash, e nem todas as funções de hash são adequadas para a geração de procedimentos, pois podem não ter uma distribuição suficientemente aleatória ou ser desnecessariamente caras.
Um dos usos das funções de hash é como parte da implementação de estruturas de dados, como tabelas de hash e dicionários. Eles costumam ser rápidos, mas não são suficientemente aleatórios, pois não se destinam à aleatoriedade, mas apenas ao desempenho eficiente dos algoritmos. Em teoria, isso significa que eles também deveriam ser aleatórios, mas, na prática, não encontrei recursos que comparassem as propriedades de aleatoriedade desses itens, e os que testei acabaram tendo propriedades de aleatoriedade bastante ruins (consulte o Apêndice C para obter detalhes).
Outro uso da função hash é para criptografia. Eles geralmente são muito aleatórios, mas também são lentos, pois os requisitos para funções de hash criptograficamente fortes são muito maiores do que para valores que parecem aleatórios.
Nosso objetivo para fins de geração de procedimentos é uma função de hash aleatória que pareça aleatória, mas que também seja eficiente, ou seja, que não seja mais lenta do que o necessário. É provável que não haja um adequado incorporado à linguagem de programação de sua escolha e que você precise encontrar um para incluir em seu projeto.
Testei algumas funções de hash diferentes com base em recomendações e informações de vários cantos da Internet. Selecionei três deles para comparação aqui.
- PcgHash: Obtive essa função de hash de Adam Smith em uma discussão no fórum do Google Groups sobre Geração de conteúdo procedural. Adam propôs que, com um pouco de habilidade, não é muito difícil criar sua própria função de hash aleatória e ofereceu seu trecho de código PcgHash como exemplo.
- MD5: Essa pode ser uma das funções de hash mais conhecidas. Ele também tem força criptográfica e é mais caro do que o necessário para nossos objetivos. Além disso, normalmente precisamos apenas de um int de 32 bits como valor de retorno, enquanto o MD5 retorna um valor de hash muito maior, a maior parte do qual estaríamos jogando fora. No entanto, vale a pena incluí-lo para fins de comparação.
- xxHash: Essa é uma função hash não criptográfica moderna e de alto desempenho que tem propriedades aleatórias muito boas e ótimo desempenho.
Além de gerar as imagens de sequência de ruído e os gráficos de coordenadas, também testei com um conjunto de testes de aleatoriedade chamado ENT - A Pseudorandom Number Sequence Test Program. Incluí estatísticas otorrinolaringológicas selecionadas nas imagens, bem como uma estatística que eu mesmo criei e que chamo de Desvio das Diagonais. O último analisa as somas das linhas diagonais de pixels do gráfico de coordenadas e mede o desvio padrão dessas somas.
Aqui estão os resultados das três funções de hash:

O PcgHash se destaca pelo fato de que, embora pareça muito aleatório nas imagens de ruído de valores aleatórios sequenciais, o gráfico de coordenadas revela padrões claros, o que significa que ele não resiste bem a transformações simples. Concluo com isso que desenvolver sua própria função de hash aleatório é difícil e deve ser deixado para os especialistas.
O MD5 e o xxHash parecem ter propriedades aleatórias muito comparáveis e, dentre elas, o xxHash é cerca de 50 vezes mais rápido.
O xxHash também tem a vantagem de que, embora não seja um RNG, ele ainda tem o conceito de uma semente, o que não é o caso de todas as funções de hash. A possibilidade de especificar uma semente tem vantagens claras para a geração de procedimentos, pois é possível usar sementes diferentes para propriedades aleatórias diferentes de entidades, células de grade ou similares e, em seguida, usar apenas o índice da entidade/coordenação da célula como entrada para a função de hash como está. Crucialmente, com o xxHash, os números de sequências com sementes diferentes são aleatórios em relação uns aos outros (consulte o Apêndice 2 para obter mais detalhes).
Em minhas investigações sobre as funções de hash, ficou claro que, embora seja bom escolher uma função de hash de alto desempenho em benchmarks de hash de uso geral, é crucial para o desempenho otimizá-la para as necessidades de geração de procedimentos, em vez de apenas usar a função de hash como está.
Há duas otimizações importantes:
- Evite conversões entre inteiros e bytes. A maioria das funções de hash de uso geral recebe uma matriz de bytes como entrada e retorna um número inteiro ou alguns bytes como valor de hash. No entanto, alguns dos de alto desempenho convertem os bytes de entrada em números inteiros, pois operam internamente com números inteiros. Como é mais comum que a geração de procedimentos obtenha um hash com base em valores de entrada inteiros, a conversão para bytes é completamente inútil. Refatorar a dependência de bytes pode triplicar o desempenho e deixar o resultado 100% idêntico.
- Implemente métodos sem loop que recebem apenas uma ou poucas entradas. A maioria das funções hash de uso geral recebe dados de entrada de comprimento variável na forma de uma matriz. Isso também é útil para a geração de procedimentos, mas os usos mais comuns provavelmente são para obter um hash com base em apenas 1, 2 ou 3 números inteiros de entrada. A criação de métodos otimizados que recebem um número fixo de números inteiros, em vez de uma matriz, pode eliminar a necessidade de um loop na função hash, o que pode melhorar drasticamente o desempenho (em torno de 4x a 5x em meus testes). Não sou especialista em otimização de baixo nível, mas a diferença drástica pode ser causada por uma ramificação implícita no loop for ou pela necessidade de alocar uma matriz.
Minha recomendação atual para uma função de hash é usar uma implementação do xxHash que seja otimizada para geração de procedimentos. Consulte o Apêndice C para obter detalhes sobre o motivo.
Você pode obter minhas implementações do xxHash e de outras funções de hash em C# no BitBucket. Ele é mantido de forma privada por mim em meu tempo livre, não pela Unity Technologies.
Além das otimizações, também adicionei métodos extras para obter a saída como um número inteiro em um intervalo especificado ou como um número de ponto flutuante em um intervalo especificado, que são necessidades típicas da geração de procedimentos.
Observação: No momento em que escrevo, adicionei apenas uma otimização de entrada de um único número inteiro ao xxHash e ao MurmurHash3. Quando tiver tempo, adicionarei sobrecargas otimizadas para entradas de dois e três números inteiros.
As funções de hash aleatórias e os geradores de números aleatórios também podem ser combinados. Uma abordagem sensata é usar geradores de números aleatórios com sementes diferentes, mas em que as sementes tenham passado por uma função de hash aleatória em vez de serem usadas diretamente.
Imagine que você tenha um grande mundo de labirinto, possivelmente quase infinito. O mundo tem uma grade de grande escala em que cada célula da grade é um labirinto. À medida que o jogador se move no mundo, são gerados labirintos nas células da grade ao redor do jogador.
Nesse caso, você desejará que cada labirinto seja sempre gerado da mesma forma toda vez que for visitado, portanto, os números aleatórios necessários para isso precisam ser produzidos independentemente dos números gerados anteriormente.
No entanto, os labirintos são sempre gerados um labirinto inteiro de cada vez, portanto, não é necessário ter controle sobre a ordem dos números aleatórios individuais usados para um labirinto.
A abordagem ideal aqui é usar uma função de hash aleatório para criar uma semente para um labirinto com base na coordenada da célula da grade do labirinto e, em seguida, usar essa semente para uma sequência de números aleatórios do gerador de números aleatórios.

O código C# poderia ter a seguinte aparência:
Tipo de bloco desconhecido "codeBlock", especifique um serializador para ele na propriedade `serializers.types`.
Se precisar de controle sobre a ordem de consulta dos números aleatórios, use uma função de hash aleatória adequada (como xxHash) em uma implementação otimizada para geração de procedimentos.
Se você só precisa obter um monte de números aleatórios e a ordem não importa, a maneira mais simples é usar um gerador de números aleatórios, como a classe System.Random em C#. Para que todos os números sejam aleatórios em relação uns aos outros, deve ser usada apenas uma única sequência (inicializada com uma semente) ou, se forem usadas várias sementes, elas devem passar primeiro por uma função de hash aleatória (como xxHash).
O código-fonte da estrutura de teste de números aleatórios mencionada neste artigo, bem como uma variedade de RNGs e funções de hash, está disponível no BitBucket. Ele é mantido de forma privada por mim em meu tempo livre, não pela Unity Technologies.
Este artigo foi publicado originalmente no blog da runevision, que é dedicado ao desenvolvimento de jogos e à pesquisa que faço em meu tempo livre.
Para determinadas coisas, você poderá consultar valores de ruído que sejam contínuos, o que significa que os valores de entrada próximos uns dos outros produzem valores de saída que também estão próximos uns dos outros. Os usos típicos são para terrenos ou texturas.
Esses requisitos são completamente diferentes dos discutidos neste artigo. Para ruído contínuo, procure o Perlin Noise ou, melhor ainda, o Simplex Noise.
No entanto, esteja ciente de que eles são adequados apenas para ruído contínuo. Consultar funções de ruído contínuo apenas para obter números aleatórios não relacionados a outros números aleatórios produzirá resultados ruins, pois não é para isso que esses algoritmos são otimizados. Por exemplo, descobri que a consulta de uma função Simplex Noise em posições inteiras retornará 0 para cada terceira entrada!
Além disso, as funções de ruído contínuo geralmente usam números de ponto flutuante em seus cálculos, que têm estabilidade e precisão piores quanto mais você se afasta da origem.
Já ouvi vários equívocos ao longo dos anos e tentarei abordar mais alguns deles aqui
Não, não vi nada que indique isso. Se você observar as imagens de teste ao longo deste artigo, não haverá diferença entre os resultados para valores de semente baixos ou altos.
Não. Novamente, se você observar as imagens de teste, verá que as sequências de valores aleatórios seguem o mesmo padrão do início (canto superior esquerdo e prosseguindo uma linha após a outra) até o fim.
Na imagem abaixo, testei o 0º número em 65535 sequências, bem como o 100º número nessas mesmas sequências. Como pode ser visto, não há diferença significativa aparente na (falta de) qualidade da aleatoriedade.

Talvez um pouco melhor, mas não o suficiente. Diferentemente da classe Random em C#, a classe Random em Java não usa a semente fornecida como está, mas embaralha os bits um pouco antes de armazenar a semente.
Os números resultantes de sequências diferentes podem ter uma aparência um pouco mais aleatória, e podemos ver nas estatísticas de teste que a correlação serial é muito melhor. No entanto, fica claro no gráfico de coordenadas que os números ainda se reduzem a uma única linha quando usados para coordenadas.

Dito isso, não há motivo para que um RNG não possa aplicar uma função hash aleatória de alta qualidade à semente antes de usá-la. De fato, parece ser uma ideia muito boa fazer isso, sem nenhuma desvantagem que eu possa imaginar. Só que as implementações populares de RNG que eu conheço não fazem isso, então você terá que fazer isso sozinho, conforme descrito anteriormente.
Não há nenhuma razão intrínseca, mas funções de hash como xxHash e MurmurHash3 tratam o valor da semente de forma semelhante às entradas, o que significa que elas basicamente aplicam uma função de hash aleatória de alta qualidade à semente, por assim dizer. Por ter sido implementado dessa forma, é seguro usar o enésimo número de objetos de hash aleatórios com sementes diferentes.

Na versão original deste artigo, comparei o PcgHash, o MD5 e o MurmurHash3 e recomendei o uso do MurmurHash3.
O MurmurHash3 tem excelentes propriedades de aleatoriedade e uma velocidade muito boa. O autor o implementou em paralelo com uma estrutura para testar funções de hash chamada SMHasher, que se tornou uma estrutura amplamente usada para essa finalidade.
Também há boas informações nesta pergunta do Stack Overflow sobre boas funções de hash para exclusividade e velocidade, que compara muitas outras funções de hash e parece apresentar uma imagem igualmente favorável do MurmurHash.
Depois de publicar o artigo, recebi recomendações de Aras Pranckevičius para dar uma olhada no xxHash e de Nathan Reed para dar uma olhada no Wang Hash, sobre o qual ele escreveu aqui.
O xxHash é uma função hash que, aparentemente, supera o MurmurHash em seu próprio território, obtendo a mesma pontuação em termos de qualidade na estrutura de testes do SMHasher e apresentando um desempenho significativamente melhor. Leia mais sobre o xxHash em sua página do Google Code.
Em minha implementação inicial, depois que removi as conversões de bytes, ele foi um pouco mais rápido que o MurmurHash3, embora não tão mais rápido quanto o mostrado nos resultados do SMHasher.
Também implementei o WangHash. A qualidade provou ser insuficiente, pois mostrou padrões claros no gráfico de coordenadas, mas foi cinco vezes mais rápido que o xxHash. Tentei implementar um "WangDoubleHash" em que o resultado é alimentado a ele mesmo, e isso teve uma boa qualidade em meus testes, sendo ainda três vezes mais rápido que o xxHash.
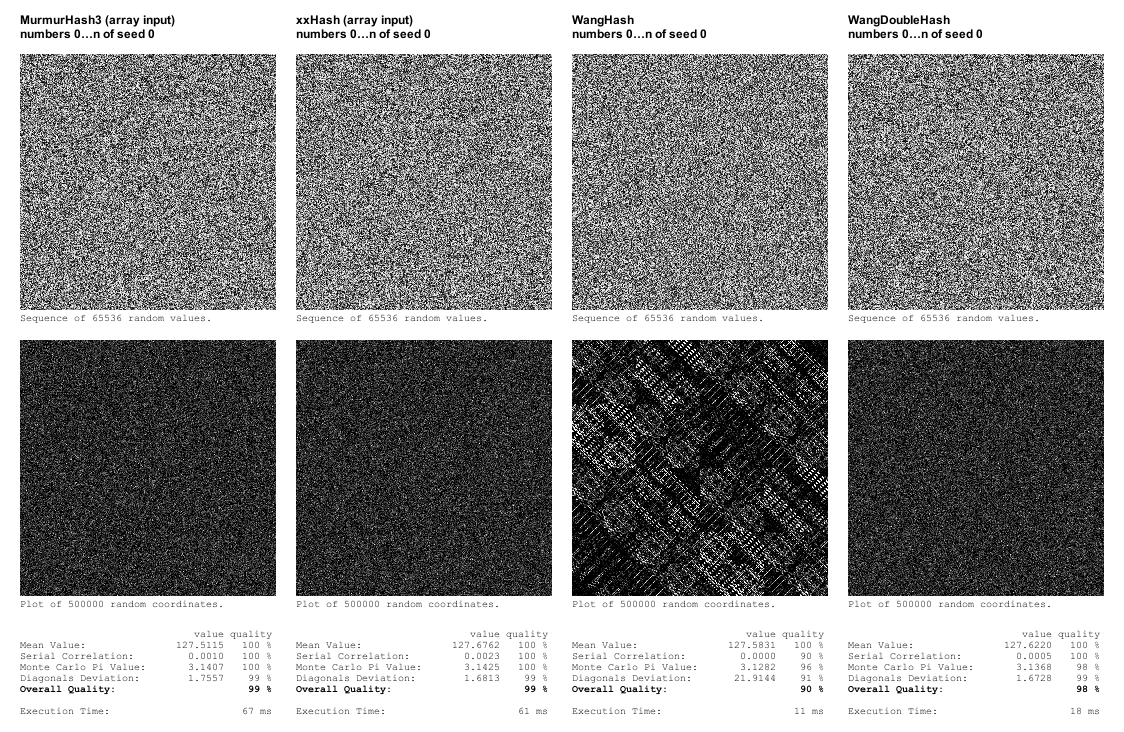
No entanto, como o WangHash (e o WangDoubleHash) usa apenas um único número inteiro como entrada, optei por implementar também versões de entrada única do xxHash e do MurmurHash3 para ver o efeito que isso teria no desempenho. E isso acabou melhorando drasticamente o desempenho (cerca de 4 a 5 vezes mais rápido). De fato, o xxHash era agora mais rápido que o WangDoubleHash.

Quanto à qualidade, minha própria estrutura de testes revela falhas bastante óbvias, mas não é tão sofisticada quanto a estrutura de testes do SMHasher, portanto, pode-se presumir que uma função de hash com pontuação alta é um selo de qualidade melhor para as propriedades de aleatoriedade do que apenas uma boa aparência em meus próprios testes. Em geral, eu diria que passar nos testes em minha estrutura de testes pode ser suficiente para fins de geração de procedimentos, mas como o xxHash (em sua versão otimizada) é a função hash mais rápida que passa em meus próprios testes, é fácil usá-la.
Existem muitas funções de hash diferentes no mercado e sempre seria possível incluir ainda mais para comparação. No entanto, eu me concentrei principalmente em alguns dos melhores desempenhos amplamente reconhecidos, tanto em termos de qualidade de aleatoriedade quanto de desempenho, e depois os otimizei ainda mais para a geração de procedimentos.
Acho que os resultados produzidos com essa versão do xxHash estão bem próximos do ideal, e os ganhos adicionais ao encontrar e usar algo ainda melhor provavelmente serão pequenos. Dito isso, sinta-se à vontade para estender a estrutura de teste com mais implementações.