Introducción a los números aleatorios repetibles


En este artículo utilizaremos la generación de niveles y mundos en juegos como ejemplo, pero las lecciones son aplicables a muchas otras cosas, como texturas procedurales, modelos, música, etc. Sin embargo, no están pensados para aplicaciones con requisitos muy estrictos, como la criptografía.
¿Por qué querrías repetir el mismo resultado más de una vez?
- Posibilidad de volver a visitar el mismo nivel/mundo. Por ejemplo, se puede crear un determinado nivel/mundo a partir de una semilla específica. Si se vuelve a utilizar la misma semilla, se volverá a obtener el mismo nivel/mundo. Puedes hacerlo, por ejemplo, en Minecraft.
- Mundo persistente que se genera sobre la marcha. Si tienes un mundo que se genera sobre la marcha a medida que el jugador se desplaza por él, es posible que quieras que los lugares sigan siendo los mismos la primera y las siguientes veces que el jugador los visite (como en Minecraft, el próximo juego No Man's Sky y otros), en lugar de ser diferentes cada vez como si estuvieran dirigidos por la lógica del sueño.
- El mismo mundo para todos. Quizá quieras que tu mundo de juego sea el mismo para todos los que lo jueguen, exactamente igual que si no se generara proceduralmente. Es el caso, por ejemplo, de No Man's Sky. Esto es esencialmente lo mismo que la posibilidad de volver a visitar el mismo nivel/mundo mencionada anteriormente, excepto que siempre se utiliza la misma semilla.
Hemos mencionado la palabra semilla unas cuantas veces. Una semilla puede ser un número, una cadena de texto u otros datos que se utilizan como entrada para obtener una salida aleatoria. El rasgo que define a una semilla es que la misma semilla siempre producirá el mismo resultado, pero incluso el más mínimo cambio en la semilla puede producir un resultado completamente diferente.
En este artículo veremos dos formas diferentes de producir números aleatorios -generadores de números aleatorios y funciones hash aleatorias- y las razones para usar uno u otro. Las cosas que sé sobre esto me las he ganado a pulso y no parecen estar fácilmente disponibles en otros sitios, así que pensé que estaría bien escribirlas y compartirlas.
La forma más habitual de producir números aleatorios es utilizar un generador de números aleatorios (o RNG, por sus siglas en inglés). Muchos lenguajes de programación tienen clases o métodos RNG incluidos, y tienen la palabra "aleatorio" en su nombre, por lo que es el enfoque obvio para empezar con números aleatorios.
Un generador de números aleatorios produce una secuencia de números aleatorios basada en una semilla inicial. En los lenguajes orientados a objetos, un generador de números aleatorios suele ser un objeto que se inicializa con una semilla. A continuación, se puede llamar repetidamente a un método de ese objeto para producir números aleatorios.

El código en C# podría tener este aspecto:
Tipo de bloque desconocido "codeBlock", especifique un serializador para él en la propiedad `serializers.types`.
En este caso estamos obteniendo valores enteros aleatorios entre 0 y el valor entero máximo posible (2147483647), pero es trivial convertir esto a un entero aleatorio en un rango específico, o un número de coma flotante aleatorio entre 0 y 1 o similar. A menudo se proporcionan métodos que lo hacen de forma inmediata.
Aquí hay una imagen con los primeros 65536 números generados por la clase Random en C# a partir de la semilla 0. Cada número aleatorio se representa como un píxel con un brillo entre 0 (negro) y 1 (blanco).

Es importante entender aquí que no se puede obtener el tercer número aleatorio sin obtener primero el primero y el segundo. No se trata sólo de un descuido en la aplicación. Por su propia naturaleza, un RNG genera cada número aleatorio utilizando el número aleatorio anterior como parte del cálculo. De ahí que hablemos de una secuencia aleatoria.

Esto significa que los RNG son geniales si necesitas un montón de números aleatorios uno detrás de otro, pero si necesitas poder obtener un número aleatorio específico (digamos, el 26º número aleatorio de la secuencia), entonces no tienes suerte. Bueno, podrías llamar a Next() 26 veces y usar el último número pero esto es una muy mala idea.
Si generas todo a la vez, probablemente no necesites números aleatorios específicos de una secuencia, o al menos no se me ocurre ninguna razón. Sin embargo, si generas las cosas poco a poco sobre la marcha, entonces sí.
Por ejemplo, supongamos que tienes tres secciones en tu mundo: A, B y C. El jugador empieza en la sección A, por lo que la sección A se genera utilizando 100 números aleatorios. A continuación, el jugador pasa a la sección B, que se genera utilizando 100 números diferentes. La sección A generada se destruye al mismo tiempo para liberar memoria. El jugador pasa a la sección C, que tiene 100 números diferentes, y la sección B se destruye.
Sin embargo, si el jugador vuelve ahora a la sección B, deberá generarse con los mismos 100 números aleatorios que la primera vez para que la sección tenga el mismo aspecto.
¡No! Este es un error muy común sobre los RNG. El hecho es que, mientras que los distintos números de una misma secuencia son aleatorios entre sí, los mismos números indexados de distintas secuencias no son aleatorios entre sí, aunque pueda parecerlo a primera vista.

Así que si tienes 100 secuencias y tomas el primer número de cada una, esos números no serán aleatorios entre sí. Y no será mejor si tomas el décimo, el centésimo o el milésimo número de cada secuencia.
Llegados a este punto, algunos se mostrarán escépticos, y no pasa nada. También puedes consultar esta pregunta de Stack Overflow sobre RNG para contenido procedimental si te resulta más fiable. Pero para algo un poco más divertido e informativo, hagamos algunos experimentos y veamos los resultados.
Veamos los números generados a partir de la misma secuencia como referencia y comparémoslos con los números creados obteniendo el primer número de cada una de las 65536 secuencias creadas a partir de las semillas 0 a 65535.
Aunque el patrón está distribuido de manera bastante uniforme, no es del todo aleatorio. De hecho, he mostrado la salida de una función puramente lineal para la comparación, y es evidente que el uso de números de semillas posteriores es apenas mejor que el uso de una función lineal.
Aun así, ¿es casi aleatorio? ¿Es suficiente?
En este punto puede ser una buena idea introducir mejores formas de medir la aleatoriedad, ya que a simple vista no es muy fiable. ¿Por qué no? ¿No basta con que la salida parezca suficientemente aleatoria?
Pues sí, al final nuestro objetivo es simplemente que las cosas parezcan suficientemente aleatorias. Pero la salida de números aleatorios puede tener un aspecto muy diferente dependiendo de cómo se utilice. Sus algoritmos de generación pueden transformar los valores aleatorios de todo tipo de formas que revelarán patrones claros que quedan ocultos cuando sólo se inspeccionan los valores enumerados en una secuencia simple.
Una forma alternativa de inspeccionar la salida aleatoria es crear coordenadas 2D a partir de pares de números aleatorios y trazar esas coordenadas en una imagen. Cuantas más coordenadas caigan en el mismo píxel, más brillante será ese píxel.
Veamos un gráfico de coordenadas para números aleatorios de la misma secuencia y para números aleatorios creados a partir de secuencias individuales con diferentes semillas. Ah, y añadamos también la función lineal.
Sorprendentemente, al crear coordenadas a partir de números aleatorios de diferentes semillas, todas las coordenadas se trazan en líneas finas en lugar de estar distribuidas uniformemente. Esto es igual que para una función lineal.
Imagina que creas coordenadas a partir de números aleatorios para plantar árboles en un terreno. Ahora todos tus árboles estarían plantados en línea recta y el resto del terreno estaría vacío.
Podemos concluir que los generadores de números aleatorios sólo son útiles si no necesitas acceder a los números en un orden concreto. Si es así, entonces es posible que desee buscar en las funciones hash aleatorias.
En general, una función hash es cualquier función que pueda utilizarse para asignar datos de tamaño arbitrario a datos de tamaño fijo, con pequeñas diferencias en los datos de entrada que producen diferencias muy grandes en los datos de salida.
Para la generación de procedimientos, los casos de uso típicos son proporcionar uno o más números enteros como entrada y obtener un número aleatorio como salida. Por ejemplo, para mundos grandes en los que sólo se generan partes a la vez, una necesidad típica es obtener un número aleatorio asociado a un vector de entrada (como una ubicación en el mundo), y este número aleatorio debe ser siempre el mismo dada la misma entrada. A diferencia de los generadores de números aleatorios (RNG), no hay secuencia: puede obtener los números aleatorios en el orden que desee.

El código en C# podría tener este aspecto - tenga en cuenta que puede obtener los números en el orden que desee:
Tipo de bloque desconocido "codeBlock", especifique un serializador para él en la propiedad `serializers.types`.
La función hash también puede tomar múltiples entradas, lo que significa que puedes obtener un número aleatorio para una coordenada 2D o 3D dada:
Tipo de bloque desconocido "codeBlock", especifique un serializador para él en la propiedad `serializers.types`.
La generación de procedimientos no es el uso típico de las funciones hash, y no todas las funciones hash son adecuadas para la generación de procedimientos, ya que pueden no tener una distribución suficientemente aleatoria o ser innecesariamente caras.
Una de las aplicaciones de las funciones hash es la implementación de estructuras de datos como tablas hash y diccionarios. Suelen ser rápidos pero no suficientemente aleatorios, ya que no están pensados para la aleatoriedad, sino sólo para que los algoritmos funcionen con eficacia. En teoría, esto significa que también deberían ser aleatorios, pero en la práctica no he encontrado recursos que comparen las propiedades de aleatoriedad de estos, y los que he probado han resultado tener propiedades de aleatoriedad bastante malas (véase el Apéndice C para más detalles).
Otro uso de la función hash es la criptografía. Estos suelen ser muy aleatorios, pero también son lentos, ya que los requisitos para funciones hash criptográficamente fuertes es mucho mayor que para valores que sólo parecen aleatorios.
Nuestro objetivo para la generación de procedimientos es una función hash aleatoria que parezca aleatoria pero que también sea eficiente, es decir, que no sea más lenta de lo necesario. Lo más probable es que no haya uno adecuado integrado en el lenguaje de programación que elijas y que tengas que encontrar uno para incluirlo en tu proyecto.
He probado algunas funciones hash diferentes basándome en recomendaciones e información de varios rincones de Internet. He seleccionado tres de ellas para compararlas.
- PcgHash: Obtuve esta función hash de Adam Smith en una discusión en el foro de Google Groups sobre Generación Procedimental de Contenidos. Adam propuso que, con un poco de habilidad, no es demasiado difícil crear tu propia función hash aleatoria y ofreció su fragmento de código PcgHash como ejemplo.
- MD5: Puede que sea una de las funciones hash más conocidas. También es de fuerza criptográfica y más caro de lo necesario para nuestros fines. Además, normalmente sólo necesitamos un int de 32 bits como valor de retorno, mientras que MD5 devuelve un valor hash mucho mayor, la mayor parte del cual estaríamos tirando a la basura. No obstante, merece la pena incluirlo para comparar.
- xxHash: Se trata de una función hash no criptográfica moderna de alto rendimiento que tiene propiedades aleatorias muy buenas y un gran rendimiento.
Además de generar las imágenes de la secuencia de ruido y los gráficos de coordenadas, también he realizado pruebas con una suite de pruebas de aleatoriedad llamada ENT - A Pseudorandom Number Sequence Test Program. He incluido algunas estadísticas de ENT en las imágenes, así como una estadística que he ideado yo mismo y que llamo Desviación Diagonal. Este último examina las sumas de las líneas diagonales de píxeles del gráfico de coordenadas y mide la desviación estándar de estas sumas.
Estos son los resultados de las tres funciones hash:

PcgHash destaca en que, aunque parece muy aleatorio en las imágenes de ruido de valores aleatorios secuenciales, el gráfico de coordenadas revela patrones claros, lo que significa que no resiste bien las transformaciones simples. De esto deduzco que crear tu propia función hash aleatoria es difícil y probablemente debería dejarse en manos de los expertos.
MD5 y xxHash parecen tener propiedades aleatorias muy comparables, y de ellas, xxHash es unas 50 veces más rápido.
xxHash también tiene la ventaja de que, aunque no es un RNG, sigue teniendo el concepto de semilla, que no es el caso de todas las funciones hash. Ser capaz de especificar una semilla tiene claras ventajas para la generación de procedimientos, ya que puede utilizar diferentes semillas para diferentes propiedades aleatorias de entidades, celdas de cuadrícula, o similares, y luego simplemente utilizar el índice de entidad / coordenada de celda como entrada para la función hash tal cual. Con xxHash, los números de secuencias sembradas de forma diferente son aleatorios entre sí (para más detalles, véase el Apéndice 2).
En mis investigaciones sobre las funciones hash ha quedado claro que, aunque es bueno elegir una función hash que tenga un alto rendimiento en las pruebas comparativas de hash de uso general, es crucial para el rendimiento optimizarla para las necesidades de generación de procedimientos en lugar de utilizar la función hash tal cual.
Hay dos optimizaciones importantes:
- Evite las conversiones entre números enteros y bytes. La mayoría de las funciones hash de propósito general toman una matriz de bytes como entrada y devuelven un entero o algunos bytes como valor hash. Sin embargo, algunos de los más potentes convierten los bytes de entrada en enteros, ya que operan internamente con enteros. Dado que lo más habitual en la generación procedimental es obtener un hash basado en valores de entrada enteros, la conversión a bytes es completamente inútil. La refactorización de la dependencia de los bytes puede triplicar el rendimiento, dejando la salida 100% idéntica.
- Implemente métodos sin bucle que tomen sólo una o unas pocas entradas. La mayoría de las funciones hash de propósito general toman datos de entrada de longitud variable en forma de matriz. Esto también es útil para la generación de procedimientos, pero los usos más comunes son probablemente para obtener un hash basado en sólo 1, 2 o 3 enteros de entrada. La creación de métodos optimizados que toman un número fijo de enteros en lugar de una matriz puede eliminar la necesidad de un bucle en la función hash, y esto puede mejorar drásticamente el rendimiento (en torno a 4x-5x en mis pruebas). No soy un experto en optimización de bajo nivel, pero la drástica diferencia podría deberse a la bifurcación implícita en el bucle for o a la necesidad de asignar una matriz.
Mi recomendación actual para una función hash es utilizar una implementación de xxHash que esté optimizada para la generación procedimental. Véase el Apéndice C para saber por qué.
Puedes obtener mis implementaciones de xxHash y otras funciones hash en C# en BitBucket. Esto lo mantengo yo de forma privada en mi tiempo libre, no Unity Technologies.
Además de las optimizaciones también he añadido métodos adicionales para obtener la salida como un número entero en un rango especificado o como un número de coma flotante en un rango especificado, que son necesidades típicas en la generación procedural.
Nota: En el momento de escribir esto sólo he añadido una única optimización de entrada de enteros a xxHash y MurmurHash3. También añadiré sobrecargas optimizadas para entradas de dos y tres enteros cuando tenga tiempo.
Las funciones hash aleatorias y los generadores de números aleatorios también pueden combinarse. Un enfoque sensato es utilizar generadores de números aleatorios con semillas diferentes, pero en los que las semillas se hayan pasado a través de una función hash aleatoria en lugar de utilizarse directamente.
Imagina que tienes un gran mundo laberíntico, posiblemente casi infinito. El mundo tiene una cuadrícula a gran escala donde cada celda de la cuadrícula es un laberinto. A medida que el jugador se desplaza por el mundo, se generan laberintos en las celdas de la cuadrícula que lo rodean.
En este caso, querrás que cada laberinto se genere siempre de la misma manera cada vez que se visite, por lo que los números aleatorios necesarios para ello deben poder producirse independientemente de los números generados previamente.
Sin embargo, los laberintos siempre se generan de uno en uno, por lo que no es necesario tener control sobre el orden de los números aleatorios individuales utilizados para un laberinto.
El enfoque ideal en este caso es utilizar una función hash aleatoria para crear una semilla para un laberinto basada en la coordenada de la celda de la cuadrícula del laberinto y, a continuación, utilizar esta semilla para una secuencia de números aleatorios del generador de números aleatorios.

El código C# podría tener este aspecto:
Tipo de bloque desconocido "codeBlock", especifique un serializador para él en la propiedad `serializers.types`.
Si necesitas controlar el orden de consulta de los números aleatorios, utiliza una función hash aleatoria adecuada (como xxHash) en una implementación optimizada para la generación procedimental.
Si sólo necesitas obtener un puñado de números aleatorios y el orden no importa, la forma más sencilla es utilizar un generador de números aleatorios como la clase System.Random en C#. Para que todos los números sean aleatorios entre sí, debe utilizarse una única secuencia (inicializada con una semilla) o, si se utilizan varias semillas, deben pasarse primero por una función hash aleatoria (como xxHash).
El código fuente del marco de pruebas de números aleatorios al que se hace referencia en este artículo, así como una variedad de RNG y funciones hash, está disponible en BitBucket. Esto lo mantengo yo de forma privada en mi tiempo libre, no Unity Technologies.
Este artículo apareció originalmente en el blog runevision, dedicado al desarrollo de juegos y a la investigación que realizo en mi tiempo libre.
Para determinadas cosas, querrá poder consultar valores de ruido que sean continuos, es decir, que los valores de entrada cercanos entre sí produzcan valores de salida también cercanos entre sí. Los usos típicos son para terrenos o texturas.
Estos requisitos son completamente diferentes de los que se tratan en este artículo. Para el ruido continuo, consulte Perlin Noise o, mejor aún, Simplex Noise.
Sin embargo, tenga en cuenta que sólo son adecuados para ruido continuo. Consultar funciones de ruido continuo sólo para obtener números aleatorios no relacionados con otros números aleatorios producirá resultados pobres, ya que no es para lo que estos algoritmos están optimizados. Por ejemplo, he descubierto que si se consulta una función Simplex Noise en posiciones enteras, se obtiene 0 en una de cada tres entradas.
Además, las funciones de ruido continuo suelen utilizar números en coma flotante en sus cálculos, que tienen peor estabilidad y precisión cuanto más se alejan del origen.
A lo largo de los años he oído varias ideas erróneas y voy a tratar de abordar algunas de ellas aquí
No, no he visto nada que indique eso. Si observas las imágenes de prueba a lo largo de este artículo, no hay diferencia entre los resultados para valores de semilla bajos o altos.
No. De nuevo, si observas las imágenes de prueba, puedes ver que las secuencias de valores aleatorios siguen el mismo patrón desde el principio (esquina superior izquierda y avanzando una línea tras otra) hasta el final.
En la imagen de abajo he probado el número 0 en 65535 secuencias, así como el número 100 en esas mismas secuencias. Como puede verse, no hay ninguna diferencia significativa aparente en la (falta de) calidad de la aleatoriedad.

Tal vez un poco mejor, pero no lo suficiente. A diferencia de la clase Random en C#, la clase Random en Java no utiliza la semilla proporcionada tal cual, sino que baraja un poco los bits antes de almacenar la semilla.
Los números resultantes de secuencias diferentes pueden tener un aspecto un poco más aleatorio, y podemos ver en las estadísticas de prueba que la Correlación Serial es mucho mejor. Sin embargo, en el gráfico de coordenadas se ve claramente que los números siguen reduciéndose a una sola línea cuando se utilizan para las coordenadas.

Dicho esto, no hay ninguna razón por la que un RNG no pueda aplicar una función hash aleatoria de alta calidad a la semilla antes de utilizarla. De hecho, me parece una muy buena idea hacerlo, sin ningún inconveniente que se me ocurra. Es sólo que las implementaciones populares de RNG que conozco no lo hacen, así que tendrás que hacerlo tú mismo como se ha descrito anteriormente.
No hay una razón intrínseca, pero las funciones hash como xxHash y MurmurHash3 tratan el valor de la semilla de forma similar a las entradas, lo que significa que esencialmente aplica una función hash aleatoria de alta calidad a la semilla, por así decirlo. Como está implementado de esa forma, es seguro usar el número N de objetos hash aleatorios sembrados de forma diferente.

En la versión original de este artículo comparé PcgHash, MD5 y MurmurHash3 y recomendé utilizar MurmurHash3.
MurmurHash3 tiene excelentes propiedades de aleatoriedad y una velocidad muy decente. El autor lo implementó en paralelo con un marco para probar funciones hash llamado SMHasher, que se ha convertido en un marco muy utilizado para ese fin.
También hay buena información en esta pregunta de Stack Overflow sobre buenas funciones hash para unicidad y velocidad que compara muchas más funciones hash y parece pintar una imagen igualmente favorable de MurmurHash.
Después de publicar el artículo recibí recomendaciones de Aras Pranckevičius para investigar xxHash y de Nathan Reed para investigar Wang Hash, sobre el que ha escrito aquí.
xxHash es una función hash que aparentemente vence a MurmurHash en su propio terreno al obtener una puntuación tan alta en calidad en el marco de pruebas SMHasher mientras que tiene un rendimiento significativamente mejor. Más información sobre xxHash en su página de Google Code.
En mi implementación inicial, después de eliminar las conversiones de bytes, era ligeramente más rápido que MurmurHash3, aunque no tanto como se muestra en los resultados de SMHasher.
También implementé WangHash. La calidad resultó insuficiente, ya que mostraba patrones claros en el gráfico de coordenadas, pero fue más de cinco veces más rápido que xxHash. Intenté implementar un "WangDoubleHash" en el que su resultado se alimenta a sí mismo, y que tenía una buena calidad en mis pruebas, mientras que sigue siendo más de tres veces más rápido que xxHash.
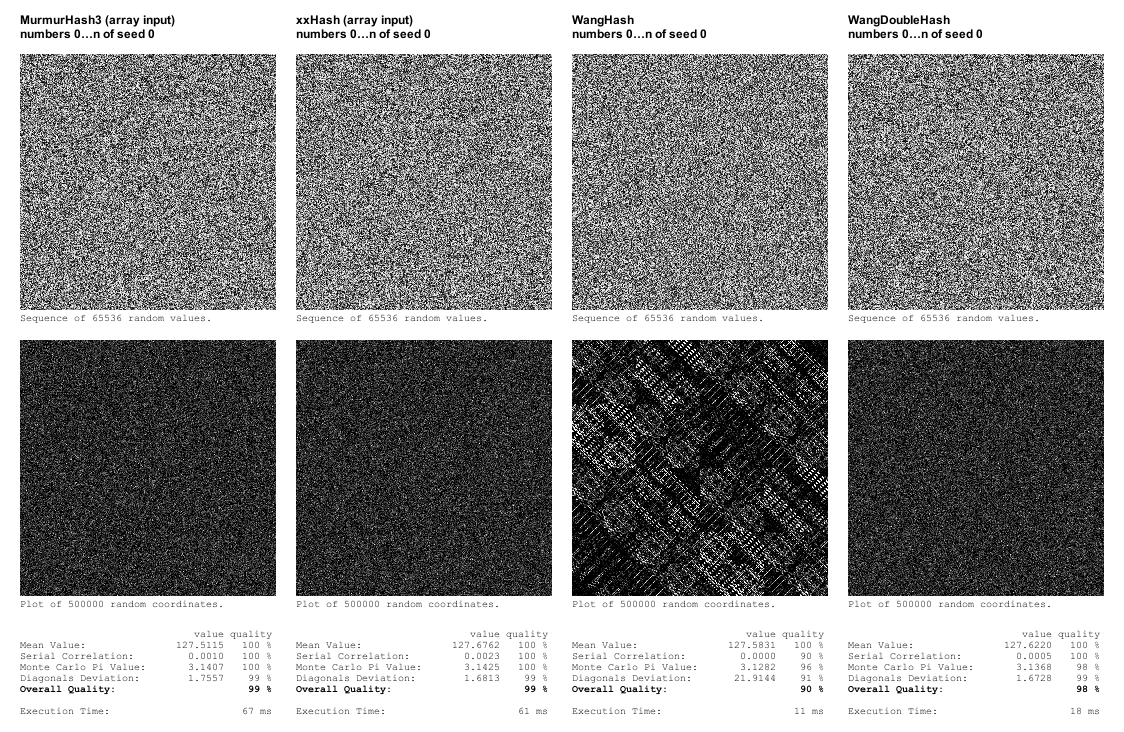
Sin embargo, como WangHash (y WangDoubleHash) sólo toma un entero como entrada, opté por implementar también versiones de entrada única de xxHash y MurmurHash3 para ver qué efecto tendría en el rendimiento. Y resultó mejorar el rendimiento de forma espectacular (unas 4-5 veces más rápido). Tanto que xxHash era ahora más rápido que WangDoubleHash.

En cuanto a la calidad, mi propio marco de pruebas revela fallos bastante obvios, pero no es ni de lejos tan sofisticado como el marco de pruebas SMHasher, por lo que una función hash que obtiene una puntuación alta allí se puede asumir que es un mejor sello de calidad para las propiedades de aleatoriedad que simplemente verse bien en mis propias pruebas. En general, yo diría que pasar las pruebas en mi marco de pruebas puede ser suficiente para fines de generación de procedimiento, pero como xxHash (en su versión optimizada) es la función hash más rápida que pasa mis propias pruebas de todos modos, es una obviedad usar eso.
Existen muchísimas funciones hash diferentes y siempre sería posible incluir más para comparar. Sin embargo, me he centrado principalmente en algunos de los más reconocidos en términos de calidad de la aleatoriedad y rendimiento, y luego los he optimizado para la generación de procedimientos.
Creo que los resultados producidos con esta versión de xxHash se acercan bastante a los óptimos y es probable que las ganancias adicionales por encontrar y utilizar algo aún mejor sean pequeñas. Dicho esto, siéntete libre de ampliar el marco de pruebas con más implementaciones.