Eine Einführung in wiederholbare Zufallszahlen


In diesem Artikel verwenden wir die Level-/Weltengenerierung in Spielen als Anwendungsbeispiel, die Lektionen sind aber auch auf viele andere Dinge anwendbar, wie etwa prozedurale Texturen, Modelle, Musik usw. Sie sind jedoch nicht für Anwendungen mit sehr strengen Anforderungen, wie etwa Kryptographie, gedacht.
Warum sollten Sie dasselbe Ergebnis mehr als einmal wiederholen wollen?
- Möglichkeit, dasselbe Level/dieselbe Welt erneut zu besuchen. Beispielsweise kann aus einem bestimmten Seedein bestimmtes Level/eine bestimmte Welt erstellt werden. Wenn derselbe Seed erneut verwendet wird, erhalten Sie wieder dasselbe Level/dieselbe Welt. Sie können dies beispielsweise in Minecraft tun.
- Dauerhafte, im Handumdrehen generierte Welt. Wenn Sie eine Welt haben, die spontan generiert wird, während sich der Spieler darin bewegt, möchten Sie vielleicht, dass die Orte beim ersten und bei allen weiteren Besuchen des Spielers gleich bleiben (wie in Minecraft, dem kommenden Spiel „No Man‘s Sky“ und anderen) und nicht jedes Mal anders sind, als ob es einer Traumlogik entspräche.
- Dieselbe Welt für alle. Vielleicht möchten Sie, dass Ihre Spielwelt für jeden Spieler gleich ist, genau so, als wäre sie nicht prozedural generiert. Dies ist beispielsweise bei No Man’s Sky der Fall . Dies ist im Wesentlichen dasselbe wie die oben erwähnte Möglichkeit, dasselbe Level/dieselbe Welt erneut zu besuchen, mit der Ausnahme, dass immer derselbe Seed verwendet wird.
Wir haben das Wort „Same“ ein paar Mal erwähnt. Ein Seed kann eine Zahl, eine Textzeichenfolge oder andere Daten sein, die als Eingabe verwendet werden, um eine zufällige Ausgabe zu erhalten. Das entscheidende Merkmal eines Seeds ist, dass derselbe Seed immer das gleiche Ergebnis hervorbringt, aber selbst die kleinste Veränderung im Seed kann ein völlig anderes Ergebnis hervorbringen.
In diesem Artikel betrachten wir zwei verschiedene Möglichkeiten zur Erzeugung von Zufallszahlen – Zufallszahlengeneratoren und zufällige Hashfunktionen – und die Gründe für die Verwendung der einen oder anderen Methode. Mein Wissen hierzu habe ich mir hart erarbeitet und es scheint, als sei es anderswo nicht so leicht erhältlich. Deshalb dachte ich, es wäre an der Zeit, es aufzuschreiben und weiterzugeben.
Die gebräuchlichste Methode zum Erzeugen von Zufallszahlen ist die Verwendung eines Zufallszahlengenerators (kurz RNG). Viele Programmiersprachen enthalten RNG-Klassen oder -Methoden und tragen das Wort „random“ (zufällig) in ihrem Namen. Dies ist also der naheliegende Ansatz für den Einstieg in die Welt der Zufallszahlen.
Ein Zufallszahlengenerator erzeugt eine Folge von Zufallszahlen auf der Grundlage eines Anfangszahlenwerts. In objektorientierten Sprachen ist ein Zufallszahlengenerator typischerweise ein Objekt, das mit einem Seed initialisiert wird. Eine Methode für dieses Objekt kann dann wiederholt aufgerufen werden, um Zufallszahlen zu erzeugen.

Der Code in C# könnte so aussehen:
Unbekannter Blocktyp „codeBlock“, bitte geben Sie einen Serialisierer dafür in der Eigenschaft „serializers.types“ an
In diesem Fall erhalten wir zufällige Ganzzahlwerte zwischen 0 und dem maximal möglichen Ganzzahlwert (2147483647), aber es ist trivial, diese in eine zufällige Ganzzahl in einem bestimmten Bereich oder eine zufällige Gleitkommazahl zwischen 0 und 1 oder ähnliches umzuwandeln. Oftmals werden Methoden bereitgestellt, die dies sofort erledigen.
Hier ist ein Bild mit den ersten 65536 Zahlen, die von der Random-Klasse in C# aus dem Startwert 0 generiert wurden. Jede Zufallszahl wird als Pixel mit einer Helligkeit zwischen 0 (schwarz) und 1 (weiß) dargestellt.

Dabei ist es wichtig zu verstehen, dass Sie die dritte Zufallszahl nicht erhalten können, ohne vorher die erste und zweite zu erhalten. Dabei handelt es sich nicht nur um ein Versehen bei der Umsetzung. Ein RNG generiert naturgemäß jede Zufallszahl unter Verwendung der vorherigen Zufallszahl als Teil der Berechnung. Man spricht deshalb auch von einer Zufallsfolge.

Dies bedeutet, dass RNGs großartig sind, wenn Sie eine Reihe von Zufallszahlen nacheinander benötigen, aber wenn Sie in der Lage sein müssen, eine bestimmte Zufallszahl zu erhalten (sagen wir, die 26. Zufallszahl aus der Folge), dann haben Sie Pech gehabt. Nun, Sie könnten Next() 26 Mal aufrufen und die letzte Nummer verwenden, aber das ist eine sehr schlechte Idee.
Wenn man alles auf einmal generiert, braucht man vermutlich keine bestimmten Zufallszahlen aus einer Folge, zumindest fällt mir kein Grund dafür ein. Wenn Sie die Dinge jedoch spontan und Stück für Stück generieren, ist das der Fall.
Angenommen, Ihre Welt verfügt beispielsweise über drei Abschnitte: A, B und C. Der Spieler startet in Abschnitt A, daher wird Abschnitt A mithilfe von 100 Zufallszahlen generiert. Anschließend gelangt der Spieler zu Abschnitt B, der aus 100 verschiedenen Zahlen generiert wird. Der generierte Abschnitt A wird gleichzeitig zerstört, um Speicher freizugeben. Der Spieler geht zu Abschnitt C weiter, der 100, jedoch unterschiedliche Zahlen enthält, und Abschnitt B wird zerstört.
Wenn der Spieler jetzt jedoch erneut zu Abschnitt B zurückkehrt, sollten diese mit denselben 100 Zufallszahlen generiert werden wie beim ersten Mal, damit der Abschnitt gleich aussieht.
NEIN! Dies ist ein sehr verbreitetes Missverständnis über RNGs. Tatsache ist, dass die verschiedenen Zahlen in derselben Zahlenfolge zwar im Verhältnis zueinander zufällig sind, die gleichen indizierten Zahlen aus verschiedenen Zahlenfolgen jedoch nicht im Verhältnis zueinander zufällig sind, auch wenn es auf den ersten Blick so aussehen mag.

Wenn Sie also 100 Sequenzen haben und von jeder die erste Zahl nehmen, sind diese Zahlen im Verhältnis zueinander nicht zufällig. Und es wird nicht besser, wenn Sie aus jeder Folge die 10., 100., 1000. Zahl nehmen.
An diesem Punkt werden einige Leute skeptisch sein, und das ist in Ordnung. Sie können sich auch diese Stack Overflow-Frage zu RNG für prozedurale Inhalte ansehen, wenn diese vertrauenswürdiger ist. Aber damit es etwas lustiger und informativer wird, wollen wir ein paar Experimente durchführen und uns die Ergebnisse ansehen.
Schauen wir uns zur Referenz die aus derselben Sequenz generierten Zahlen an und vergleichen sie mit den Zahlen, die durch die Ermittlung der ersten Zahl jeder der 65.536 Sequenzen erstellt wurden, die aus den Startwerten 0 bis 65.535 erstellt wurden.
Obwohl das Muster ziemlich gleichmäßig verteilt ist, ist es nicht ganz zufällig. Tatsächlich habe ich zum Vergleich die Ausgabe einer rein linearen Funktion gezeigt und es ist offensichtlich, dass die Verwendung von Zahlen aus nachfolgenden Startwerten kaum besser ist als die Verwendung einer rein linearen Funktion.
Aber ist es trotzdem fast zufällig? Ist es gut genug?
An diesem Punkt kann es eine gute Idee sein, bessere Möglichkeiten zur Messung der Zufälligkeit einzuführen, da das bloße Auge nicht sehr zuverlässig ist. Warum nicht? Reicht es nicht aus, dass die Ausgabe zufällig genug aussieht ?
Nun ja, letztendlich ist unser Ziel einfach, dass die Dinge ausreichend zufällig aussehen. Allerdings kann die Zufallszahlenausgabe je nach Verwendungszweck sehr unterschiedlich aussehen. Ihre Generierungsalgorithmen können die Zufallswerte auf alle möglichen Arten transformieren, wodurch klare Muster sichtbar werden, die bei der bloßen Überprüfung der in einer einfachen Sequenz aufgelisteten Werte verborgen bleiben.
Eine alternative Möglichkeit zum Überprüfen der Zufallsausgabe besteht darin, 2D-Koordinaten aus Paaren der Zufallszahlen zu erstellen und diese Koordinaten in einem Bild darzustellen. Je mehr Koordinaten auf demselben Pixel landen, desto heller wird dieses Pixel.
Schauen wir uns ein solches Koordinatendiagramm sowohl für Zufallszahlen in derselben Folge als auch für Zufallszahlen an, die aus einzelnen Folgen mit unterschiedlichen Startwerten erstellt wurden. Oh, und lassen Sie uns auch die lineare Funktion mit einbeziehen.
Es ist vielleicht überraschend, dass beim Erstellen von Koordinaten aus Zufallszahlen mit unterschiedlichen Startwerten die Koordinaten alle in dünnen Linien dargestellt werden und nicht annähernd gleichmäßig verteilt sind. Dies ist wiederum genau wie bei einer linearen Funktion.
Stellen Sie sich vor, Sie hätten Koordinaten aus Zufallszahlen erstellt, um auf einem Gelände Bäume zu pflanzen. Jetzt wären alle Ihre Bäume in einer geraden Linie gepflanzt und das restliche Gelände wäre leer!
Zusammenfassend lässt sich sagen, dass Zufallszahlengeneratoren nur dann sinnvoll sind, wenn Sie nicht in einer bestimmten Reihenfolge auf die Zahlen zugreifen müssen. Wenn das zutrifft, sollten Sie sich zufällige Hash-Funktionen näher ansehen.
Im Allgemeinen ist eine Hash-Funktion jede Funktion, mit der Daten beliebiger Größe auf Daten fester Größe abgebildet werden können, wobei geringfügige Unterschiede in den Eingabedaten zu sehr großen Unterschieden in den Ausgabedaten führen.
Bei der prozeduralen Generierung bestehen typische Anwendungsfälle darin, eine oder mehrere Ganzzahlen als Eingabe bereitzustellen und als Ausgabe eine Zufallszahl zu erhalten. Beispielsweise besteht für große Welten, von denen immer nur Teile gleichzeitig generiert werden, typischerweise der Bedarf nach einer Zufallszahl, die mit einem Eingabevektor (wie etwa einem Standort in der Welt) verknüpft ist, und diese Zufallszahl sollte bei derselben Eingabe immer dieselbe sein. Anders als bei Zufallszahlengeneratoren (RNGs) gibt es keine Reihenfolge – Sie können die Zufallszahlen in jeder beliebigen Reihenfolge erhalten.

Der Code in C# könnte folgendermaßen aussehen (beachten Sie, dass Sie die Zahlen in beliebiger Reihenfolge erhalten können):
Unbekannter Blocktyp „codeBlock“, bitte geben Sie einen Serialisierer dafür in der Eigenschaft „serializers.types“ an
Die Hash-Funktion kann auch mehrere Eingaben annehmen, was bedeutet, dass Sie für eine gegebene 2D- oder 3D-Koordinate eine Zufallszahl erhalten können:
Unbekannter Blocktyp „codeBlock“, bitte geben Sie einen Serialisierer dafür in der Eigenschaft „serializers.types“ an
Die prozedurale Generierung ist nicht die typische Verwendung von Hash-Funktionen, und nicht alle Hash-Funktionen sind für die prozedurale Generierung gut geeignet, da sie entweder keine ausreichende Zufallsverteilung aufweisen oder unnötig teuer sind.
Eine Verwendung von Hash-Funktionen ist als Teil der Implementierung von Datenstrukturen wie Hash-Tabellen und Wörterbüchern. Diese sind zwar oft schnell, aber nicht zufällig genug, da sie nicht auf Zufälligkeit ausgelegt sind, sondern nur dafür sorgen sollen, dass Algorithmen effizient arbeiten. Theoretisch bedeutet dies, dass sie ebenfalls zufällig sein sollten, in der Praxis habe ich jedoch keine Ressourcen gefunden, die die Zufälligkeitseigenschaften dieser vergleichen, und bei den von mir getesteten Ressourcen stellte sich heraus, dass sie ziemlich schlechte Zufälligkeitseigenschaften aufweisen (Einzelheiten finden Sie in Anhang C).
Eine weitere Verwendung der Hash-Funktion ist die Kryptographie. Diese sind oft sehr zufällig, aber auch langsam, da die Anforderungen an kryptografisch starke Hashfunktionen viel höher sind als für lediglich zufällig erscheinende Werte.
Unser Ziel für die prozedurale Generierung ist eine zufällige Hash-Funktion, die zufällig aussieht, aber auch effizient ist, d. h., sie ist nicht langsamer als nötig. Es besteht die Möglichkeit, dass in der von Ihnen gewählten Programmiersprache kein passendes Tool integriert ist und Sie eines finden müssen, um es in Ihr Projekt zu integrieren.
Ich habe einige verschiedene Hash-Funktionen basierend auf Empfehlungen und Informationen aus verschiedenen Ecken des Internets getestet. Drei davon habe ich hier zum Vergleich ausgewählt.
- PcgHash: Ich habe diese Hash-Funktion von Adam Smith aus einer Diskussion im Google Groups- Forum zur prozeduralen Inhaltsgenerierung erhalten. Adam meinte, dass es mit ein wenig Geschick nicht allzu schwer sei, eine eigene zufällige Hash-Funktion zu erstellen, und bot seinen PcgHash-Codeausschnitt als Beispiel an.
- MD5: Dies ist möglicherweise eine der bekanntesten Hash-Funktionen. Es verfügt außerdem über kryptografische Stärke und ist teurer als für unsere Zwecke nötig. Darüber hinaus benötigen wir normalerweise nur einen 32-Bit-Integer als Rückgabewert, während MD5 einen viel größeren Hash-Wert zurückgibt, von dem wir den größten Teil einfach wegwerfen würden. Dennoch lohnt es sich, es zum Vergleich mit einzubeziehen.
- xxHash: Dies ist eine leistungsstarke moderne nichtkryptografische Hash-Funktion, die sowohl sehr schöne Zufallseigenschaften als auch eine großartige Leistung aufweist.
Außer der Generierung der Rauschsequenzbilder und Koordinatendiagramme habe ich auch Tests mit einer Zufallstestsuite namens „ENT – A Pseudorandom Number Sequence Test Program“durchgeführt. Ich habe in die Bilder ausgewählte ENT-Statistiken sowie eine von mir selbst entwickelte Statistik aufgenommen, die ich „Diagonalabweichung“ nenne. Letzteres betrachtet die Summen der diagonalen Pixellinien aus dem Koordinatendiagramm und misst die Standardabweichung dieser Summen.
Hier sind die Ergebnisse der drei Hash-Funktionen:

PcgHash fällt dadurch auf, dass es zwar in den Rauschbildern sequentieller Zufallswerte sehr zufällig erscheint, das Koordinatendiagramm jedoch klare Muster erkennen lässt und somit einfachen Transformationen nicht gut standhält. Daraus schließe ich, dass das Erstellen einer eigenen zufälligen Hash-Funktion schwierig ist und wahrscheinlich den Experten überlassen werden sollte.
MD5 und xxHash scheinen sehr vergleichbare Zufallseigenschaften zu haben, und von diesen ist xxHash etwa 50-mal schneller.
xxHash hat außerdem den Vorteil, dass es, obwohl es kein RNG ist, dennoch über das Konzept eines Seeds verfügt, was nicht bei allen Hash-Funktionen der Fall ist. Die Möglichkeit, einen Seed anzugeben, bietet klare Vorteile für die prozedurale Generierung, da Sie unterschiedliche Seeds für unterschiedliche zufällige Eigenschaften von Entitäten, Rasterzellen oder Ähnlichem verwenden und dann einfach den Entitätsindex/die Zellenkoordinate unverändert als Eingabe für die Hash-Funktion verwenden können. Entscheidend ist, dass bei xxHash die Zahlen aus unterschiedlich gesetzten Sequenzen im Verhältnis zueinander zufällig sind (weitere Einzelheiten finden Sie in Anhang 2).
Bei meinen Untersuchungen von Hash-Funktionen wurde deutlich, dass es zwar gut ist, eine Hash-Funktion zu wählen, die bei allgemeinen Hash-Benchmarks eine hohe Leistung erbringt, es für die Leistung jedoch entscheidend ist, sie an die Anforderungen der prozeduralen Generierung anzupassen, anstatt die Hash-Funktion einfach so zu verwenden, wie sie ist.
Es gibt zwei wichtige Optimierungen:
- Vermeiden Sie Konvertierungen zwischen Ganzzahlen und Bytes. Die meisten allgemeinen Hashfunktionen verwenden ein Byte-Array als Eingabe und geben eine Ganzzahl oder einige Bytes als Hashwert zurück. Einige der leistungsstärksten Programme konvertieren die Eingabebytes jedoch in Ganzzahlen, da sie intern mit Ganzzahlen arbeiten. Da es bei der prozeduralen Generierung am häufigsten vorkommt, einen Hash basierend auf ganzzahligen Eingabewerten zu erhalten, ist die Konvertierung in Bytes völlig sinnlos. Durch Refactoring der Abhängigkeit von Bytes Away kann die Leistung verdreifacht werden, während die Ausgabe zu 100 % identisch bleibt.
- Implementieren Sie No-Loop-Methoden, die nur eine oder wenige Eingaben akzeptieren. Die meisten allgemeinen Hashfunktionen akzeptieren Eingabedaten variabler Länge in Form eines Arrays. Dies ist auch für die prozedurale Generierung nützlich, aber die gängigsten Verwendungszwecke bestehen wahrscheinlich darin, einen Hash basierend auf nur 1, 2 oder 3 Eingabe-Ganzzahlen zu erhalten. Durch die Erstellung optimierter Methoden, die eine feste Anzahl ganzer Zahlen anstelle eines Arrays verwenden, kann die Notwendigkeit einer Schleife in der Hash-Funktion entfallen, was die Leistung erheblich verbessern kann (bei meinen Tests um etwa das Vier- bis Fünffache). Ich bin kein Experte für Low-Level-Optimierung, aber der dramatische Unterschied könnte entweder durch implizite Verzweigungen in der For-Schleife oder durch die Notwendigkeit, ein Array zuzuweisen, verursacht werden.
Meine aktuelle Empfehlung für eine Hash-Funktion ist die Verwendung einer Implementierung von xxHash, die für die prozedurale Generierung optimiert ist. Weitere Einzelheiten zu den Gründen finden Sie in Anhang C.
Sie können meine Implementierungen von xxHash und anderen Hash-Funktionen in C# auf BitBucket erhalten. Dies wird von mir privat in meiner Freizeit gepflegt, nicht von Unity Technologies.
Neben den Optimierungen habe ich auch zusätzliche Methoden hinzugefügt, um die Ausgabe als Ganzzahl in einem angegebenen Bereich oder als Gleitkommazahl in einem angegebenen Bereich zu erhalten, was typische Anforderungen bei der prozeduralen Generierung sind.
Notiz: Zum Zeitpunkt des Schreibens habe ich nur eine einzige Ganzzahl-Eingabeoptimierung zu xxHash und MurmurHash3 hinzugefügt. Wenn ich Zeit habe, werde ich auch optimierte Überladungen für zwei und drei ganzzahlige Eingaben hinzufügen.
Auch eine Kombination von Zufalls-Hashfunktionen und Zufallszahlengeneratoren ist möglich. Ein sinnvoller Ansatz besteht darin, Zufallszahlengeneratoren mit unterschiedlichen Seeds zu verwenden, wobei die Seeds jedoch nicht direkt verwendet, sondern durch eine zufällige Hash-Funktion geleitet werden.
Stellen Sie sich vor, Sie haben eine große, möglicherweise nahezu unendliche Labyrinthwelt. Die Welt besteht aus einem großflächigen Gitternetz, in dem jede Gitterzelle ein Labyrinth ist. Während sich der Spieler in der Welt bewegt, werden in den Gitterzellen um den Spieler herum Labyrinthe generiert.
In diesem Fall möchten Sie, dass jedes Labyrinth bei jedem Besuch immer auf die gleiche Weise generiert wird. Daher müssen die hierfür erforderlichen Zufallszahlen unabhängig von zuvor generierten Zahlen erzeugt werden können.
Da Labyrinthe jedoch immer als ganzes Labyrinth auf einmal generiert werden, besteht keine Notwendigkeit, die Reihenfolge der einzelnen Zufallszahlen, die für ein Labyrinth verwendet werden, zu kontrollieren.
Der ideale Ansatz besteht hier darin, mithilfe einer zufälligen Hash-Funktion einen Startwert für ein Labyrinth basierend auf der Koordinate der Gitterzelle des Labyrinths zu erstellen und diesen Startwert dann für eine Zufallszahlengeneratorfolge von Zufallszahlen zu verwenden.

Der C#-Code könnte folgendermaßen aussehen:
Unbekannter Blocktyp „codeBlock“, bitte geben Sie einen Serialisierer dafür in der Eigenschaft „serializers.types“ an
Wenn Sie Kontrolle über die Reihenfolge der Abfrage von Zufallszahlen benötigen, verwenden Sie eine geeignete Zufalls-Hash-Funktion (z. B. xxHash) in einer Implementierung, die für die prozedurale Generierung optimiert ist.
Wenn Sie nur eine Reihe von Zufallszahlen benötigen und die Reihenfolge keine Rolle spielt, ist die einfachste Möglichkeit die Verwendung eines Zufallszahlengenerators wie beispielsweise der Klasse System.Random in C#. Damit alle Zahlen im Verhältnis zueinander zufällig sind, darf entweder nur eine einzige Sequenz (initialisiert mit einem Seed) verwendet werden, oder, falls mehrere Seeds verwendet werden, müssen diese zunächst durch eine zufällige Hash-Funktion (wie etwa xxHash) geleitet werden.
Der Quellcode für das in diesem Artikel erwähnte Testframework für Zufallszahlen sowie verschiedene RNGs und Hashfunktionen sind auf BitBucket verfügbar. Dies wird von mir privat in meiner Freizeit gepflegt, nicht von Unity Technologies.
Dieser Artikel erschien ursprünglich auf dem Runevision-Blog , der sich der Spieleentwicklung und -forschung widmet, die ich in meiner Freizeit betreibe.
Für bestimmte Dinge möchten Sie in der Lage sein, Rauschwerte abzufragen, die kontinuierlich sind, was bedeutet, dass Eingabewerte, die nahe beieinander liegen, Ausgabewerte erzeugen, die ebenfalls nahe beieinander liegen. Typische Verwendungszwecke sind Gelände oder Texturen.
Diese Anforderungen unterscheiden sich völlig von den in diesem Artikel besprochenen. Bei kontinuierlichem Rauschen sehen Sie sich Perlin Noise – oder besser Simplex Noise – an.
Beachten Sie jedoch, dass diese nur für Dauerlärm geeignet sind. Das Abfragen kontinuierlicher Rauschfunktionen nur zum Erhalten von Zufallszahlen, die keinen Bezug zu anderen Zufallszahlen haben, führt zu schlechten Ergebnissen, da diese Algorithmen nicht dafür optimiert sind. Ich habe beispielsweise festgestellt, dass die Abfrage einer Simplex-Noise-Funktion an ganzzahligen Positionen für jede dritte Eingabe 0 zurückgibt!
Darüber hinaus verwenden kontinuierliche Rauschfunktionen in ihren Berechnungen normalerweise Gleitkommazahlen, deren Stabilität und Präzision abnimmt, je weiter man sich vom Ursprung entfernt.
Ich habe im Laufe der Jahre verschiedene Missverständnisse gehört und werde versuchen, hier noch ein paar davon anzusprechen.
Nein, ich habe nichts gesehen, was darauf hindeutet. Wenn Sie sich die Testbilder in diesem Artikel ansehen, werden Sie feststellen, dass zwischen den Ergebnissen für niedrige und hohe Startwerte kein Unterschied besteht.
Nein. Wenn Sie sich die Testbilder erneut ansehen, können Sie erkennen, dass die Folgen der Zufallswerte vom Anfang (obere linke Ecke und dann Zeile für Zeile weiter) bis zum Ende demselben Muster folgen.
Im Bild unten habe ich die 0. Zahl in 65535 Sequenzen sowie die 100. Zahl in denselben Sequenzen getestet. Wie man sieht, gibt es keinen offensichtlichen signifikanten Unterschied in der (fehlenden) Qualität der Zufälligkeit.

Vielleicht ein kleines bisschen besser, aber bei weitem nicht genug. Anders als die Random-Klasse in C# verwendet die Random-Klasse in Java den bereitgestellten Seed nicht unverändert, sondern mischt die Bits ein wenig, bevor der Seed gespeichert wird.
Die resultierenden Zahlen aus verschiedenen Sequenzen sehen möglicherweise ein klein wenig zufälliger aus, und wir können anhand der Teststatistiken erkennen, dass die serielle Korrelation viel besser ist. Im Koordinatendiagramm ist jedoch deutlich zu erkennen, dass die Zahlen bei Verwendung als Koordinaten immer noch zu einer einzigen Zeile zusammenfallen.

Dennoch gibt es keinen Grund, warum ein RNG nicht vor der Verwendung eine hochwertige zufällige Hash-Funktion auf den Seed anwenden könnte. Tatsächlich scheint es eine sehr gute Idee zu sein, und ich kann mir keine Nachteile vorstellen. Das liegt nur daran, dass die mir bekannten gängigen RNG-Implementierungen dies nicht tun. Sie müssen es also selbst tun, wie zuvor beschrieben.
Es gibt keinen eigentlichen Grund, aber Hash-Funktionen wie xxHash und MurmurHash3 behandeln den Startwert ähnlich wie die Eingaben, was bedeutet, dass sie sozusagen im Wesentlichen eine zufällige Hash-Funktion hoher Qualität auf den Startwert anwenden. Aufgrund dieser Implementierung ist es sicher, die N-te Zahl aus unterschiedlich gestarteten zufälligen Hash-Objekten zu verwenden.

In der Originalversion dieses Artikels habe ich PcgHash, MD5 und MurmurHash3 verglichen und die Verwendung von MurmurHash3 empfohlen.
MurmurHash3 hat hervorragende Zufälligkeitseigenschaften und eine sehr gute Geschwindigkeit. Der Autor hat es parallel mit einem Framework zum Testen von Hash-Funktionen namens SMShasher implementiert, das für diesen Zweck zu einem weit verbreiteten Framework geworden ist.
Es gibt auch gute Informationen zu dieser Stack Overflow-Frage zu guten Hash-Funktionen hinsichtlich Eindeutigkeit und Geschwindigkeit , die viele weitere Hash-Funktionen vergleicht und ein ebenso positives Bild von MurmurHash zu zeichnen scheint.
Nach der Veröffentlichung des Artikels erhielt ich von Aras Pranckevičius die Empfehlung, mir xxHash genauer anzusehen, und von Nathan Reed die Empfehlung, mir Wang Hash genauer anzusehen, worüber er hier geschrieben hat.
xxHash ist eine Hash-Funktion, die MurmurHash auf ihrem eigenen Gebiet offenbar schlägt, indem sie im SMHasher-Testframework eine ebenso hohe Qualität erzielt und gleichzeitig eine deutlich bessere Leistung aufweist. Weitere Informationen zu xxHash finden Sie auf der Google Code-Seite.
In meiner ersten Implementierung war es, nachdem ich die Byte-Konvertierungen entfernt hatte, etwas schneller als MurmurHash3, wenn auch bei weitem nicht so viel schneller wie die SMShasher-Ergebnisse.
Ich habe auch WangHash implementiert. Die Qualität erwies sich als unzureichend, da sich im Koordinatendiagramm klare Muster zeigten, aber es war über fünfmal schneller als xxHash. Ich habe versucht, einen „WangDoubleHash“ zu implementieren, dessen Ergebnis an sich selbst übermittelt wird. In meinen Tests war die Qualität gut, obwohl er immer noch über dreimal schneller war als xxHash.
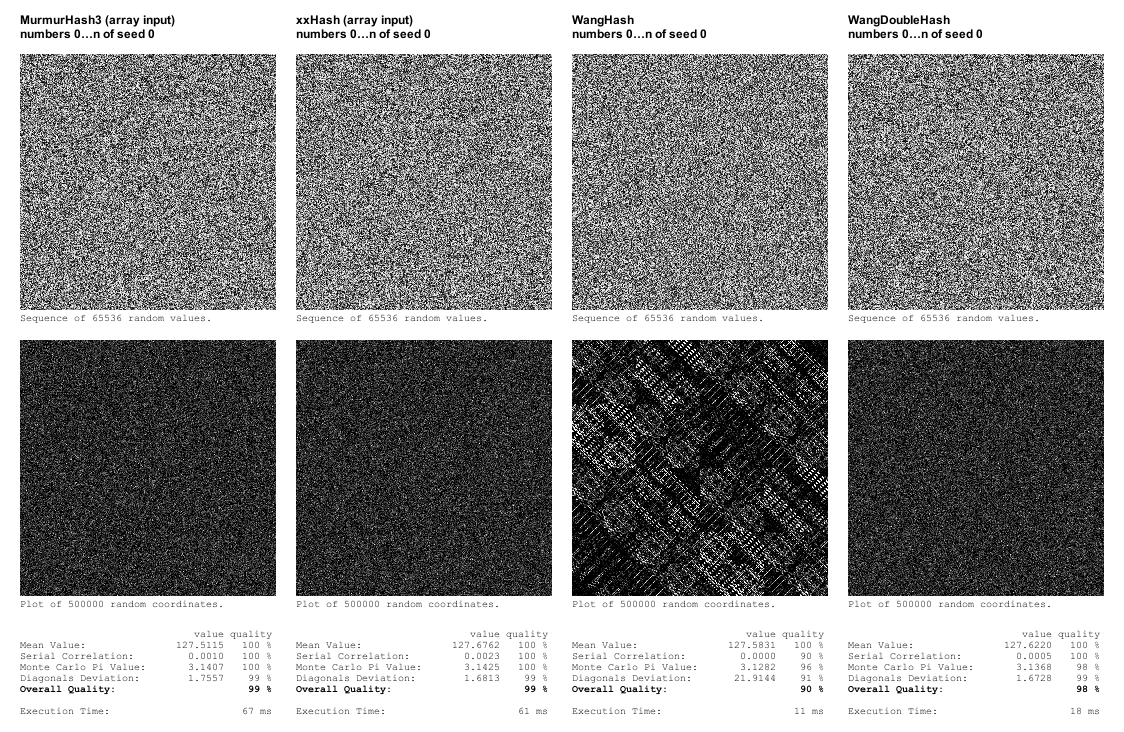
Da WangHash (und WangDoubleHash) jedoch nur eine einzelne Ganzzahl als Eingabe akzeptiert, habe ich mich dafür entschieden, auch Versionen von xxHash und MurmurHash3 mit einer einzigen Eingabe zu implementieren, um zu sehen, welche Auswirkungen dies auf die Leistung hätte. Und es stellte sich heraus, dass die Leistung dadurch dramatisch verbessert wurde (etwa 4-5 Mal schneller). So sehr, dass xxHash jetzt schneller war als WangDoubleHash.

Was die Qualität angeht, weist mein eigenes Test-Framework ziemlich offensichtliche Mängel auf, ist aber bei weitem nicht so ausgefeilt wie das SMHasher -Test-Framework, sodass davon ausgegangen werden kann, dass eine Hash-Funktion, die dort hohe Punktzahlen erzielt, ein besseres Qualitätssiegel für Zufallseigenschaften darstellt, als wenn sie in meinen eigenen Tests lediglich gut aussieht. Generell würde ich sagen, dass das Bestehen der Tests in meinem Testframework für Zwecke der prozeduralen Generierung ausreichen kann, aber da xxHash (in seiner optimierten Version) sowieso die schnellste Hash-Funktion ist, die meine eigenen Tests besteht, ist es ein Kinderspiel, einfach diese zu verwenden.
Es gibt extrem viele verschiedene Hashfunktionen und es wäre jederzeit möglich, noch mehr zum Vergleich einzubeziehen. Ich habe mich jedoch in erster Linie auf einige der allgemein anerkannten leistungsstärksten in Bezug auf Zufälligkeitsqualität und Leistung konzentriert und sie dann für die prozedurale Generierung weiter optimiert.
Ich denke, dass die mit dieser Version von xxHash erzielten Ergebnisse recht nahe am Optimum liegen und dass weitere Vorteile durch das Finden und Verwenden einer noch besseren Lösung wahrscheinlich gering ausfallen werden. Sie können das Testframework jedoch jederzeit um weitere Implementierungen erweitern.