改进 2022.2 中的工作系统性能缩放 - 第 2 部分:高架


开销(overhead)指的是CPU未运行作业时,从派发作业到工作完成,再执行队列下一个作业的时间。总体上,这段时间会花在两个地方:
1.C# 工作 API 层
2.本地作业调度程序(管理并运行所有计划的 C# 作业和内部的 C++ 作业)
C# Job API的作用是以安全的方式访问原生作业系统。虽然这是 C# 到 C++ 过渡的绑定层,但它也是一个允许您防止意外调度 C# 作业的层,这些作业在访问 本地容器时会遇到竞赛条件或死锁。
另外,这一单独的抽象层也能让作业的创建方式更多样。在C++层,作业只是指向数据和函数的指针。但在 C# API 的基础上,您可以自定义作业类型,从而更好地控制作业数据的拆分和并行化,以适应用户的特定用例。
在派发作业时,C#捆绑层会把作业结构复制到一段未托管的内存中。这使得 C# 作业结构的生命周期与作业系统中的作业生命周期脱节,因为作业生命周期受作业的依赖关系和平台总体负载的影响。然后,作业系统会有条件地在编辑器运行模式构建中执行安全检查,以确保作业可以安全运行。
这些步骤非常关键,但也会带来一定的系统开销。由于作业大小以及作业可能具有的 NativeContainers 和依赖关系的数量都可能不同,因此复制作业和验证其安全性的成本并不固定。因此,Unity必须限制并减少这部分开销以精简运算的复杂度。
在2021.2 Tech Stream,我们的工程团队将每条作业句柄的安全检测结果缓存起来,大幅改善了安全系统。这一点尤为重要,因为安全系统需要了解整个作业依赖链和所有作业包含的每个本地内存引用,以了解哪些依赖信息可能缺失,以及应将依赖信息添加到哪个作业中。这也使得派发时检测项目的数量不固定(即在每项作业及其依赖项上读取/写入所引用的NativeContainer及作业本身的次数)。
不过,Unity利用了C#作业一次仅派发一项的特点,会在派发时检测安全性。与其在派发时重新扫描作业,我们可以先快速检验作业依赖链是否需要重新验证,借此跳过大量的工作。即便是较小的依赖链,也能极大地降低安全性检验的开销。理想情况下我们在开发时再也不用关闭作业安全检查了(在运行/发售版禁用安全检查)。
每当C#/C++作业需要运行,它就会经由派发器发出。派发器的职责有:
- 根据句柄跟踪作业
- 管理作业依赖关系,确保作业仅在所有依赖关系完成后才开始执行
- 管理“工作线程”,即执行作业的线程
- 确保作业尽快执行——在依赖项允许时并行执行
此外,虽然 C# 作业 API 只允许从主线程调度作业,但作业调度程序需要支持多个线程同时调度作业。这是因为底层的 Unity 引擎使用许多线程来调度作业,甚至可以从作业内部调度作业。这种功能有利有弊,但需要对其正确性进行更严格的审查,并要求作业调度程序必须是线程安全的。
回到2017.3,作业派发器的基本组成有:
- 作业队列
- 作业堆栈
- 信号(Semaphore)
- 工作线程阵列
典型的用法是这样的:当作业被调度时,它们会被排入一个全局、无锁、多生产者、多消费者的队列,该队列代表的是已准备好由工作线程处理的作业。主线程随后发出信号来唤起工作线程。
要求唤醒的工人数量取决于调度的作业类型--单个作业(如IJob)只唤醒一个工人,因为这种作业类型不会将工作分散到多个工人线程上。而IJobParallelFor作业则代表可以并行运行的多个工作。在安排一项工作的同时,可能会有许多工作需要某些或所有工人同时帮助完成。如此一来,派发器可以明确该唤起多少工作线程。
唤起后,所有作业都会在工作线程里运行。在 2017.3 版中,他们负责从作业队列中取消作业,确保所有相关的作业依赖关系都已完成。如果它们尚未完成,作业和未完成的依赖项将被添加到无锁堆栈中,以便跳到队列的前面再次尝试运行。工作线程会循环执行这些操作,直到引擎发出要关闭的信号,或者堆栈和队列中不再有作业。此时,工作线程会等待来自主线程 semaphore 的信号,从而进入休眠状态。
while(!scheduler.isQuitting)
{
// Usually empty unless we need to prioritize a dependency
// to unblock a job we got from the queue. Alternatively
// pieces of work from a IJobParallelFor job can end up here to let
// many workers help finish IJobParallelFor work quickly
Job* pJob = m_stack.pop();
if(!pJob)
Job* pJob = m_queue.dequeue();
if(pJob) {
// ExecuteJob if all dependencies are complete, otherwise
// push this job and the dependencies to the stack and try again
if(EnsureDependenciesAreCompleteOtherwiseAddToStack(pJob))
ExecuteJob(pJob);
}
else
{
// Put the thread to sleep until more jobs are scheduled
m_semaphore.Wait(1);
}
}派发器会创建和CPU虚拟核心数一样多的工作线程,默认数量减一。这样做的目的是让每个工作线程在自己的 CPU 内核上运行,同时留出一个 CPU 内核供主线程继续运行。实际上,在没有为非游戏进程保留内核的平台上,减少工作线程的数量会更好,这样操作系统或驱动程序线程的计算就不会与游戏主线程或工作线程竞争。
由于主线程是作业派发的主要位置,其运行不能被拖延。这样做会直接影响进入作业系统的作业数量,从而影响帧内的并行性。
理论上,主线程可以调度大量工作,CPU 的其他内核也可以执行这些工作,这样我们就能最大限度地提高 CPU 的并行工作效率,并使性能随着硬件的变化而扩展。如果我们的工作线程比内核多,操作系统就可以上下文切换主线程,并切换到工作线程。多一条工作线程也许能更快清空作业队列,但新作业将无法进入队列,总的来说对性能弊大于利。
上述作业调度程序方法有几个潜在问题,可能会导致作业系统开销过大。我们来看一些例子。
主线程派发了一个不带依赖项的IJob(非并行作业):
- 作业被添加到队列,一条工作线程收到唤醒信号
- 线程被唤起
- 线程执行作业
- 线程检测是否有更多作业需执行
- 若无,线程重新休眠
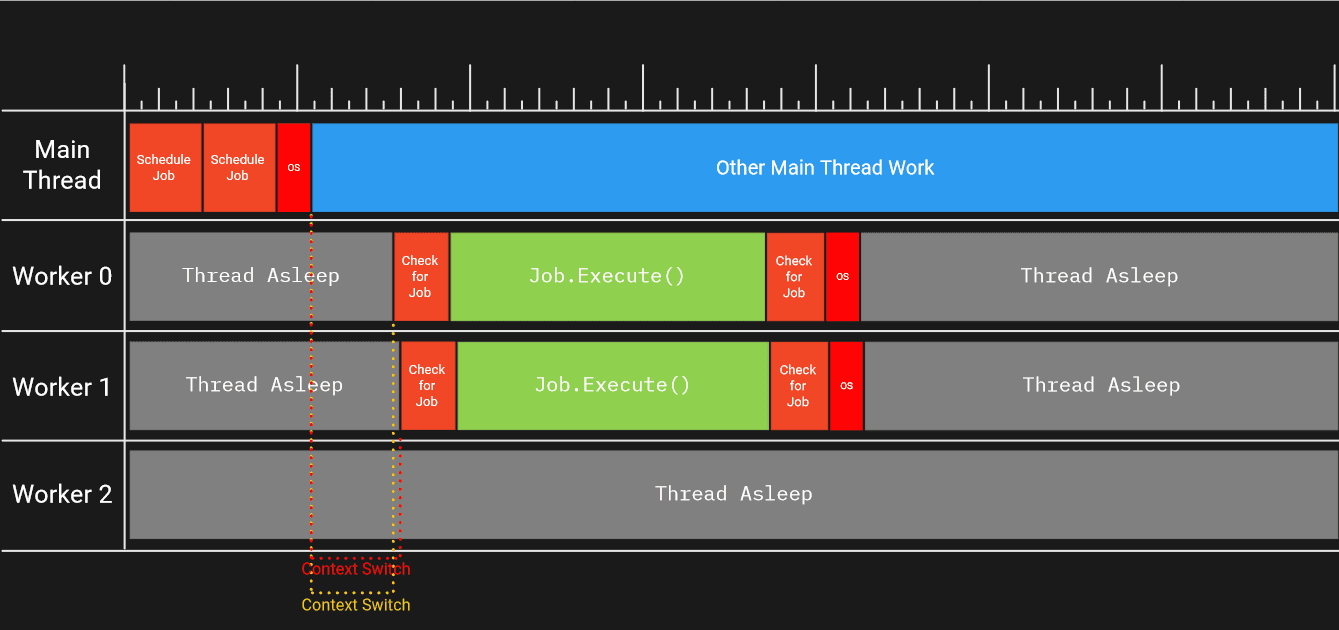
一旦主线程用派发器发出信号,一条工作线程(并非只是worker 0)便会被唤起。唤醒和上下文切换也会占用一定的工作核心时间。这是因为,当工作线程处于休眠状态时,工作线程最终运行的 CPU 内核很可能在做某些事情--可能在运行游戏生成的另一个线程,也可能在运行使用该线程的机器上的其他进程。
为使线程能够暂停并在稍后恢复,需要保存线程的寄存器状态,刷新指令流水线,并恢复切换到线程的状态。仅仅是发信号都会占用主核心的时间,因为操作系统需要决定唤醒哪条线程。归根结底,这意味着主线程核心和工作线程核心正在进行的工作并不是我们的工作,因此是我们希望减少的开销。

工作线程收到信号的时间,以及单次作业的运行耗时也会影响到整个作业系统。还是以上方用法为例,这次我们派发两份作业:
- 作业被添加到队列,一条工作线程收到唤醒信号
- 第二份作业被添加到队列,工作线程收到唤醒信号
- 流程以同样的顺序执行了两次:
- 线程被唤起
- 线程执行作业
- 线程检测是否有更多作业需执行
- 若无,线程重新休眠
只要时机得当,这次作业可以同时由两条线程运行。

但是,如果其中一个工作太小,或者发出信号和唤醒两个工人的时间太长,一个工人可能会抢走队列中的所有工作,结果我们就会无缘无故地向一个工人发出信号。

这种作业饥饿和唤醒 <-> 休眠的循环方式最终会导致相当高的成本,并限制作业系统提供的并行性。
你可能会想:"在处理线程时,发出线程信号和上下文切换带来的开销难道不是业务成本吗?你当然没有错。不过,虽然你无法直接控制发送信号或唤醒线程的成本有多高,但你可以控制这些操作发生的频率。
避免无缘无故唤醒工人的一个办法是,只有当你怀疑队列中有大量工作项目需要工人处理时,才唤醒他们,以证明唤醒成本是合理的。这可以通过分批进行:与其在安排工作时立即向工人发出信号,不如将工作添加到列表中,并在特定时间将这批工作冲入工作系统,同时唤醒适当数量的工人。
但仍然存在这样的风险:实际唤醒时间过长,批处理的作业量很小,或者批处理的作业量不是很大。一般来说,批处理中包含的作业越多,就越有可能避免无故唤醒线程造成的开销。Unity 会维护一个全局批处理,每当调用JobHandle.Complete(),该批处理就会被刷新。因此,如果需要明确等待作业完成,应尽可能晚地、不频繁地等待作业完成,而且通常更倾向于调度具有作业依赖性的作业,以便最好地控制对数据的安全访问。
你可能还会问自己:"如果向线程发出信号并等待它们醒来/入睡纯粹是开销,那我们为什么不让线程一直醒着找工作呢?当队列中有大量工作时,这种情况就会自然发生。除非操作系统认为工作线程的优先级比其他工作低(或者被明确划分了时间片,应该被交换,以便给其他线程公平的 CPU 时间份额--这取决于你的平台),否则工作线程会愉快地继续工作。
然而,就像我们在第一部分中看到的PartialUpdateA和PartialUpdateB函数一样,并非所有作业都是可并行和无数据依赖的。因此,您通常需要等待某些子作业集完成后才能运行其他作业。因此,当可运行作业(无未完成依赖关系的作业)的数量少于工人线程的数量时,我们就会看到作业图的并行性出现瓶颈,导致一些工人无事可做。
如果不让工作线程休眠,就会出现一些问题。如果工作线程不断检查新任务,却找不到任何新任务,这就被认为是 "忙碌的等待",或者说是一种浪费,不会使程序取得进展的工作。让所有内核以最大并行度运行,但又不推进游戏,会消耗电池寿命。不仅如此,如果内核没有空闲时间,没有足够的冷却,CPU 的温度就会升高,从而导致降频 --运行速度变慢,以避免过热造成损坏。事实上,在移动平台上,如果 CPU 内核温度过高,整个内核暂时失效的情况并不少见。对于工作系统来说,高效地使用核心非常重要,因此在让工人睡觉和让他们不断循环寻找新工作之间需要取得平衡,希望他们能幸运地找到新工作。
int Add(int val)
{
int newSum;
do
{
// Load the current value we want to update
var oldSum = m_Sum;
// Compute new value we want to store
newSum = oldSum + val;
// Attempt to write the new value. CompareExchange returns
// the value seen inside m_Sum when writing newSum to m_Sum.
// If newSum doesn't match oldSum, we will retry the loop
// since it means another thread wrote to the memory before us.
// If we wrote our value without this check, we might
// write an incorrect value
}while (oldSum != Interlocked.CompareExchange(ref m_Sum, newSum, oldSum));
return newSum ;
}CAS 循环依赖于比较和交换指令(这里我们使用C# 互锁库来抽象平台细节),该指令 "比较两个值是否相等,如果相等,则替换第一个值"。由于我们希望Add() 函数的用户不必担心该函数可能会失败,因此如果因为其他线程抢先更新 m_Sum 而导致函数失败,我们会使用一个循环来重试。
这种重试循环实质上是一种 "忙碌等待 "循环。这对性能缩放有不良影响:如果多个线程同时进入 CAS 循环,那么每次只会有一个线程离开,从而使每个线程执行的操作序列化。幸运的是,CAS 循环通常只做少量的工作,但仍会对性能产生较大的负面影响。当更多内核并行执行循环时,每个线程完成循环所需的时间会更长,同时线程之间也会出现竞争。
此外,由于 CAS 循环依赖于共享内存的原子读写,因此每个线程通常需要在每次迭代时对其缓存行进行无效处理,从而造成额外的开销。与 CAS 循环内部重做计算的成本相比,这种开销可能非常昂贵(在上述情况下,重做两个数字相加的工作)。因此,成本有多高可能不是一眼就能看出来的。
在 2017.3 作业调度程序中,当工人线程没有运行作业时,它们会在共享的无锁堆栈或队列中寻找作业。这两种数据结构都至少使用了一个 CAS 循环来从数据结构中删除工作。因此,随着可用内核越来越多,当数据结构出现竞争时,从堆栈或队列中提取工作的成本就会增加。特别是,当作业量较小时,工作线程在队列或堆栈中寻找作业的时间会按比例增加。
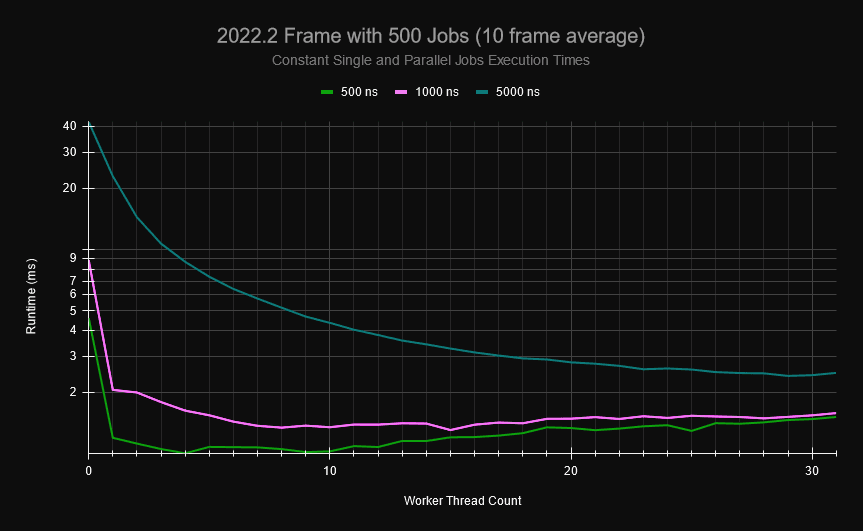
在一个小项目中,我生成了一个典型游戏帧更新的确定性作业图。下图由单个作业和并行作业(每个并行作业可分为 1-100 个并行作业)组成,其中每个作业可能有 0-10 个作业依赖关系,主线程偶尔会有显式同步点,必须等待某些作业完成后才能调度更多作业。如果我在作业图中生成 500 个作业,并规定每个作业的执行时间都是固定的(并行作业的每个部分也需要这个时间),你可以看到,随着使用的内核增多,作业系统的开销也会增加。

对于耗时 0.5μs 的作业,一旦有 20 个工人,框架更新的速度就会和不使用作业系统时一样快,而使用我机器上的所有内核时,运行速度几乎是不使用作业系统时的两倍。默认情况下,Unity 会使用所有内核,因此对于 1μs 的作业,尽管使用了 31 个工作线程,但性能几乎没有提高。这是无锁队列和堆栈争用严重的直接结果。幸运的是,用户作业的规模往往较大,可以掩盖这种开销。不过,扩展问题还是存在的,而且小型作业仍然很常见(尤其是并行作业)。即使使用较大的作业,由于与作业调度器中的全局无锁堆栈和队列发生争用,您的调度模式和工人计时也会造成大量开销。
现在,您可以看到我们的团队需要解决几个方面的问题,以减少作业系统的开销,包括 Unity 方面和游戏创建者方面的开销:
- 避免主线程停滞:
- 唤醒工作线程的信令成本很高,应尽量减少。
- 在主线程上修改与工作线程共享的状态很可能会导致缓存失效和潜在的忙碌等待。
- 主线程应频繁调度作业,避免明确等待作业 .Complete()。更倾向于提交有依赖关系的工作。
- 避免工作线程停滞:
- 工作线程的效率直接影响并行性。尽可能避免争夺共享资源。
- 工作线程的忙碌等待会耗尽电池寿命,并可能因温度升高而导致降频。
虽然 Unity 无法改变用户在游戏中提交作业的数量,但我们的工程师可以通过不同的作业调度方法来解决相当多的问题。在 2022.2 版本中,作业调度程序可高度分解为几个基本组件:
- 工作线程阵列
- 作业队列数组
- 信号数组
这与之前的作业调度程序非常相似。不过,主要区别在于取消了主线程和工作线程之间的共享状态。相反,我们将队列和 Semaphores(或支持它的平台上的futex)设为每个工作线程的 Localization。现在,当主线程调度作业时,作业会被排入主线程队列,而不是全局队列。
同样,如果工作线程需要调度作业(例如,作业在其执行中调度作业),该作业会被调度到工作线程自己的队列中,而不是主线程队列中。这可以减少内存流量,因为工人在向队列写入数据时,会减少缓存行失效的频率。因此,工人不会以相同的频率读/写所有不同的队列。
由于有了更多的队列,工人循环也发生了变化:
while(!scheduler.isQuitting)
{
// Take a job from our worker thread’s local queue
Job* pJob = m_worker_queue[m_workerId].dequeue();
// If our queue is empty try to steal work from someone
// else's queue to help them out.
if(pJob == nullptr) {
pJob = StealFromOtherQueues()
}
if(pJob) {
// If we found work, there may be more conditionally
// wake up other workers as necessary
WakeWorkers();
ExecuteJob(pJob);
}
// Conditionally go to sleep (perhaps we were told there is a
// parallel job we can help with)
else if(ShouldSleep())
{
// Put the thread to sleep until more jobs are scheduled
m_semaphores[m_workerId].Wait(1);
}
}工人在自己的队列中寻找工作,只有在自己的队列空闲时才查看其他工人的队列。由于工人更倾向于在自己的队列中进行工作排序和排队,因此任何一个队列上的争用量都会减少。
另一个区别是唤醒线程的信号方式。现在,工作线程负责唤醒其他工作线程,而主线程负责确保在调度作业时至少有一个工作线程是清醒的。
这种责任上的变化使得主线程不再需要在并行作业提交时单独负责唤醒线程,从而消除了过多的开销。相反,工作系统会进行跟踪,以了解是否需要唤醒任何工人。主线程可以确保工人始终处于唤醒状态,以便在作业上取得进展;当工人唤醒并发现自己队列或其他队列中有作业时,工人可以向其他工人发出唤醒信号,并在需要时帮助清空队列。

工人队列的分离也为配置和优化提供了一些有趣的余地,我们的团队正在继续添加和改进这些功能。在 2022.2 版中,无论平台有多少内核,用户都能看到主线程唤醒工作线程的成本降低,工作线程的作业吞吐量提高。此外,虽然 Unity 没有将队列分离功能回传至 2021.3 LTS,但我们已将设计变更带回,使工作线程负责相互发出信号,而非仅由主线程负责。从 2021.3.14f1 起,全局 semaphore 信号导致主线程作业系统开销过高的问题应不再存在。
如果您有问题或想了解更多信息,请访问我们的C# 工作系统论坛。您也可以通过用户名 @Antifreeze#2763 直接通过 Unity Discord与我联系。作为 Tech from the Trenches 系列的一部分,请务必关注其他 Unity 开发人员的新技术博客。