Verbesserung der Leistungsskalierung des Jobsystems in 2022.2 - Teil 2: Overhead


Mit den Versionen 2022.2 und 2021.3.14f1 wurden die Planungskosten und die Leistungsskalierung des Unity-Jobsystems verbessert. Im ersten Teil dieses zweiteiligen Artikels über die Neuerungen bei Jobsystemen habe ich einige Hintergrundinformationen zur parallelen Programmierung gegeben und erklärt, warum Sie ein Jobsystem verwenden sollten. Im zweiten Teil gehen wir näher darauf ein, was Jobsystem-Overhead ist und wie Unity ihn abmildert.
Unter Overhead versteht man die Zeit, die die CPU nicht mit der Ausführung Ihres Auftrags verbringt, und zwar von dem Moment an, in dem Sie mit der Planung beginnen, bis zu dem Moment, in dem der Auftrag beendet ist und alle wartenden Aufträge freigegeben werden. Im Großen und Ganzen gibt es zwei Bereiche, in denen Zeit verbracht wird:
1. Die C# Job API-Schicht
2. Der native Job Scheduler (der alle geplanten C#- und intern C++-Jobs verwaltet und ausführt)
Die C# Job API hat die Aufgabe, einen sicheren Zugang zum nativen Jobsystem zu bieten. Dies ist zwar eine Bindungsschicht für den Übergang von C# zu C++, aber es ist auch eine Schicht, die es Ihnen ermöglicht, die versehentliche Planung von C#-Aufträgen zu verhindern, die beim Zugriff auf NativeContainers aus einem Auftrag heraus.
Darüber hinaus bietet diese Trennung eine bessere Möglichkeit, selbst Arbeitsplätze zu schaffen. Auf der C++-Ebene sind Jobs nur ein Zeiger auf Daten und ein Funktionszeiger. Mit der zusätzlichen C# API können Sie die Arten von Aufträgen, die Sie planen, individuell anpassen und so besser steuern, wie Auftragsdaten aufgeteilt und parallelisiert werden sollen, um benutzerspezifischen Anwendungsfällen gerecht zu werden.
Wenn Sie einen Auftrag planen, kopiert die C#-Auftragsbindungsschicht die Auftragsstruktur in eine nicht verwaltete Speicherzuweisung. Dadurch kann die Lebensdauer der C#-Job-Struktur von der Lebensdauer des Jobs im Jobsystem abgekoppelt werden, da diese von den Abhängigkeiten des Jobs und der Gesamtbelastung der Plattform beeinflusst wird. Das Jobsystem führt dann in den Editor-Playmode-Builds bedingte Sicherheitsprüfungen durch, um sicherzustellen, dass ein Job sicher ausgeführt werden kann.
Diese Schritte sind wichtig, aber sie sind nicht kostenlos und tragen zum Arbeitsaufwand des Systems bei. Da die Größe eines Auftrags variieren kann, ebenso wie die Anzahl der NativeContainer und der Abhängigkeiten, die ein Auftrag haben kann, sind die Kosten für das Kopieren von Aufträgen und die Überprüfung ihrer Sicherheit nicht festgelegt. Aus diesem Grund ist es wichtig, dass Unity die Kosten gering hält und sich auf eine lineare Berechnungskomplexität beschränkt.
Im Tech Stream 2021.2 hat das Entwicklungsteam das Job-Sicherheitssystem erheblich verbessert, indem es das Ergebnis der Sicherheitsprüfung für einzelne Job-Handles zwischengespeichert hat. Dies ist besonders wichtig, da das Sicherheitssystem ganze Ketten von Job-Abhängigkeiten und jede native Speicherreferenz, die alle Jobs enthalten, kennen muss, um zu verstehen, welche Abhängigkeitsinformationen möglicherweise fehlen und zu welchem Job eine Abhängigkeit hinzugefügt werden sollte. Dies kann zu einer nicht linearen Anzahl von Elementen führen, die bei der Planung durchlaufen werden müssen (d.h. für jeden Auftrag und seine Abhängigkeiten prüfen Sie den Lese-/Schreibzugriff für jeden NativeContainer, auf den der Auftrag verweist, und jeden Auftrag, der auf die NativeContainer verweist).
Unity kann jedoch die Tatsache ausnutzen, dass C#-Aufträge nur einzeln geplant werden, und die Sicherheit während dieser Planung überprüfen. Anstatt alle Aufträge bei jedem Zeitplan neu zu überprüfen, können wir schnell feststellen, ob eine erneute Überprüfung der Auftragsketten notwendig ist oder nicht. So können große Mengen an Arbeit übersprungen werden. Selbst bei kleinen Ketten von Abhängigkeiten von Aufträgen lassen sich so die Kosten für Sicherheitskontrollen drastisch senken. Idealerweise sollte es keinen Grund geben, die Job-Sicherheitsüberprüfungen bei der Entwicklung auszuschalten (Job-Sicherheitsüberprüfungen sind bei Spieler-/Schiffsbauwerken nicht eingeschaltet).
Wenn ein C#- oder C++-Auftrag zur Ausführung geplant wird, durchläuft er den Job Scheduler. Die Aufgabe des Planers ist es:
- Verfolgen Sie Aufträge über Auftrags-Handles
- Verwalten Sie Auftragsabhängigkeiten und stellen Sie sicher, dass Aufträge erst dann ausgeführt werden, wenn alle Abhängigkeiten abgeschlossen sind.
- Verwalten Sie "Worker-Threads", d.h. die Threads, die Aufträge ausführen
- Stellen Sie sicher, dass Aufträge so schnell wie möglich ausgeführt werden - das bedeutet in der Regel, dass sie parallel laufen sollten, wenn es die Abhängigkeiten erlauben.
Während die C# Job API die Planung von Aufträgen nur vom Haupt-Thread aus erlaubt, muss der Job Scheduler außerdem mehrere Threads unterstützen, die gleichzeitig Aufträge planen. Das liegt daran, dass die zugrunde liegende Unity-Engine viele Threads verwendet, die Aufträge planen und sogar Aufträge innerhalb von Aufträgen planen können. Diese Funktionalität hat Vor- und Nachteile, erfordert aber eine viel genauere Prüfung der Korrektheit und die zusätzliche Anforderung, dass der Job Scheduler thread-sicher sein muss.
In der Version 2017.3 war das grundlegende Aussehen des Job Schedulers:
- Warteschlange für Aufträge
- Stapel für Jobs
- Semaphor
- Array von Arbeits-Threads
Der typische Gebrauch folgt diesem Muster: Wenn Aufträge geplant werden, werden sie in eine globale, sperrfreie Warteschlange mit mehreren Produzenten und Verbrauchern eingereiht, die die Aufträge repräsentiert, die zur Bearbeitung durch einen Worker-Thread bereit sind. Der Hauptthread signalisiert dann über eine Semaphore, dass er die Worker-Threads aufweckt.
Die Anzahl der zu weckenden Worker hängt von der Art des geplanten Auftrags ab - Einzelaufträge wie IJob wecken nur einen einzigen Worker, da dieser Auftragstyp die Arbeit nicht auf mehrere Worker-Threads verteilt. IJobParallelFor-Aufträge hingegen stellen mehrere Arbeitsschritte dar, die parallel ausgeführt werden können. Auch wenn ein Auftrag geplant ist, kann es sein, dass einige oder alle Mitarbeiter gleichzeitig an mehreren Teilen arbeiten müssen. Der Planer errechnet also, wie viele Mitarbeiter potenziell helfen können, und weckt diese Zahl auf.
Sobald die Worker-Threads erwacht sind, findet die eigentliche Arbeit statt. In 2017.3 waren sie dafür verantwortlich, einen Auftrag aus der Warteschlange zu nehmen und sicherzustellen, dass alle relevanten Auftragsabhängigkeiten vollständig sind. Wenn sie noch nicht vollständig waren, wurden der Auftrag und die unvollständigen Abhängigkeiten zu einem sperrfreien Stapel hinzugefügt, um an den Anfang der Warteschlange zu gelangen und die Ausführung erneut zu versuchen. Die Worker-Threads tun dies in einer Schleife, bis entweder die Engine signalisiert, dass sie heruntergefahren werden soll, oder bis sich keine Aufträge mehr im Stapel und in der Warteschlange befinden. Zu diesem Zeitpunkt gehen die Worker-Threads in den Ruhezustand über, indem sie auf ein Signal der Semaphore des Hauptthreads warten.
while(!scheduler.isQuitting)
{
// Usually empty unless we need to prioritize a dependency
// to unblock a job we got from the queue. Alternatively
// pieces of work from a IJobParallelFor job can end up here to let
// many workers help finish IJobParallelFor work quickly
Job* pJob = m_stack.pop();
if(!pJob)
Job* pJob = m_queue.dequeue();
if(pJob) {
// ExecuteJob if all dependencies are complete, otherwise
// push this job and the dependencies to the stack and try again
if(EnsureDependenciesAreCompleteOtherwiseAddToStack(pJob))
ExecuteJob(pJob);
}
else
{
// Put the thread to sleep until more jobs are scheduled
m_semaphore.Wait(1);
}
}Der Job Scheduler erstellt so viele Worker-Threads, wie virtuelle Kerne auf der CPU vorhanden sind, standardmäßig minus einen. Die Absicht dabei ist, dass jeder Worker-Thread auf seinem eigenen CPU-Kern läuft, während ein CPU-Kern für den Haupt-Thread frei bleibt, um weiterzulaufen. In der Praxis kann es auf Plattformen, auf denen ein Kern nicht für spielfremde Prozesse reserviert ist, besser sein, die Anzahl der Worker-Threads zu reduzieren, damit die vom Betriebssystem oder den Treiber-Threads durchgeführten Berechnungen nicht mit den Haupt- oder Job-Worker-Threads des Spiels konkurrieren.
Da der Hauptthread der primäre Ort ist, von dem aus Aufträge geplant werden, ist es sehr wichtig, den Hauptthread nicht zu verzögern. Dies wirkt sich direkt darauf aus, wie viele Aufträge in das Auftragssystem gelangen und wie viel Parallelität innerhalb eines Rahmens auftreten kann.
Da der Haupt-Thread theoretisch eine Vielzahl von Aufträgen plant und der Rest der CPU-Kerne diese Aufträge ausführt, sollten wir in der Lage sein, die parallele Arbeit auf der CPU zu maximieren und die Leistung zu skalieren, wenn sich die Hardware ändert. Wenn wir mehr Worker-Threads als Kerne hätten, könnte das Betriebssystem den Haupt-Thread in den Kontext wechseln und zu einem Worker-Thread wechseln. Ein zusätzlicher Worker-Thread könnte dazu beitragen, dass Ihre Warteschlange schneller geleert wird, aber er würde mit Sicherheit verhindern, dass neue Arbeit in die Warteschlange gelangt, was letztendlich einen größeren negativen Effekt auf die Leistung hat.
Es gibt einige potenzielle Probleme mit dem obigen Job Scheduler-Ansatz, die zu einem Overhead des Jobsystems führen können. Schauen wir uns einige Beispiele an.
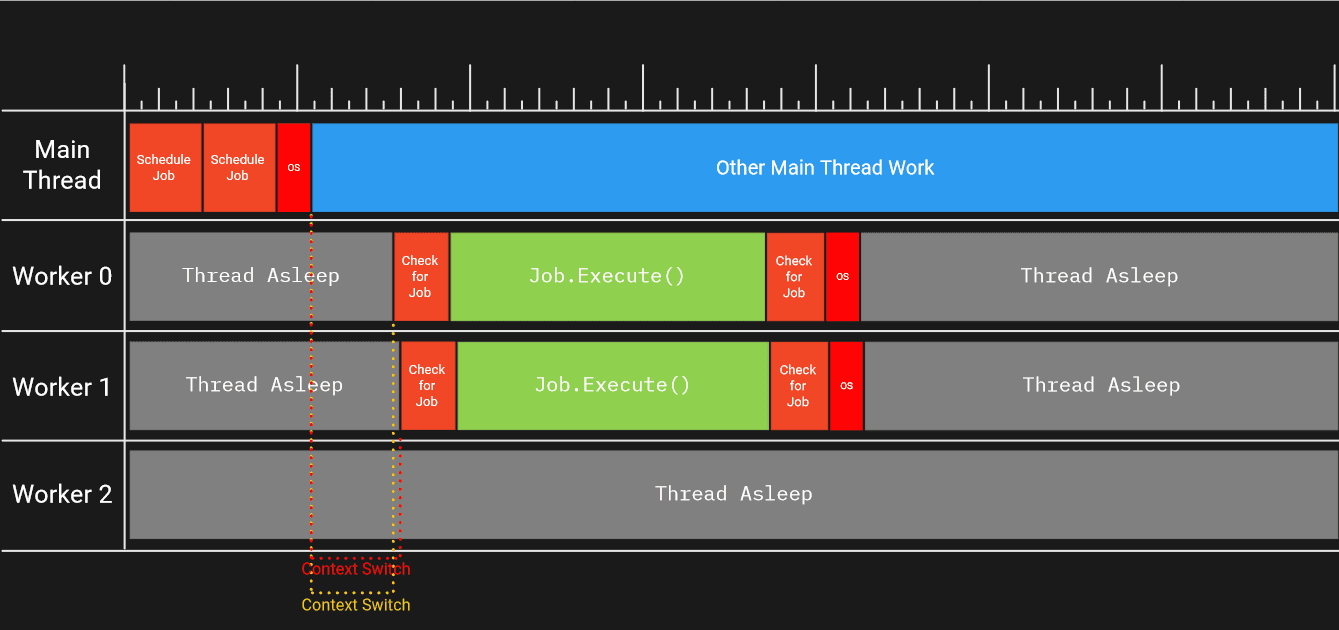
Der Hauptthread plant einen IJob (nicht-parallelen Job) ohne Abhängigkeiten:
- Ein Auftrag wird der Warteschlange hinzugefügt und ein Arbeitsthread wird zum Aufwachen signalisiert
- Ein Arbeits-Thread wacht auf
- Der Arbeiter führt den Auftrag aus
- Der Worker prüft, ob weitere Aufträge ausgeführt werden müssen
- Der Arbeiter geht schlafen, da es keine Arbeit mehr gibt
Sobald der Haupt-Thread über die Semaphore des Job Schedulers ein Signal gibt, wird einer der schlafenden Worker-Threads (nicht unbedingt Worker 0) aufwachen. Das Aufwachen und der Kontextwechsel nehmen auf dem Worker Core einige Zeit in Anspruch. Denn während der Worker-Thread schläft, war der CPU-Kern, auf dem der Worker-Thread am Ende läuft, wahrscheinlich mit etwas anderem beschäftigt - vielleicht mit einem anderen Thread, der vom Spiel oder einem anderen Prozess auf dem Rechner, der den Thread verwendet, erzeugt wurde.
Damit Threads angehalten und später wieder aufgenommen werden können, muss der Registerstatus eines Threads gespeichert werden, die Befehlspipelines müssen geleert werden und der Status des umgeschalteten Threads muss wiederhergestellt werden. Selbst die Signalisierung des Threads benötigt Zeit auf dem Kern des Hauptthreads, da die Benachrichtigung, welcher Thread aufgeweckt werden soll, vom Betriebssystem übernommen wird. Letztlich bedeutet dies, dass auf dem Haupt-Thread-Kern und dem Worker-Thread-Kern Arbeiten ausgeführt werden, die nicht zu unseren Aufgaben gehören und die wir daher reduzieren möchten.

Wie schnell die Mitarbeiter benachrichtigt werden können und wie viel Zeit ein einzelner Auftrag in Anspruch nimmt, kann ebenfalls Auswirkungen auf das System haben. Wenn Sie beispielsweise den obigen Anwendungsfall nehmen, aber zwei Aufträge statt einem planen:
- Ein Auftrag wird der Warteschlange hinzugefügt und ein Arbeitsthread wird zum Aufwachen signalisiert
- Der zweite Auftrag wird der Warteschlange hinzugefügt und ein Arbeits-Thread wird zum Aufwachen signalisiert
- In irgendeiner Reihenfolge, aber zweimal:
- Ein Arbeits-Thread wacht auf
- Ein Arbeiter führt den Auftrag aus
- Der Worker prüft, ob weitere Aufträge ausgeführt werden müssen
- Der Arbeiter geht schlafen, da es keine Arbeit mehr gibt
Wenn das Timing stimmt, haben Sie zwei Arbeiter, die parallel an dem Auftrag arbeiten.

Wenn jedoch einer der Aufträge zu klein ist und/oder es zu lange dauert, beide Worker zu signalisieren und aufzuwecken, könnte ein Worker die gesamte Arbeit in der Warteschlange an sich reißen, so dass wir einen Worker ohne Grund signalisiert haben.

Diese Art des Aushungerns von Aufträgen und des Zyklus Wake <-> Sleep kann ziemlich teuer werden und die Parallelität, die das Auftragssystem bietet, einschränken.
Sie werden vielleicht denken: "Ist der Overhead durch die Signalisierung von Threads und die Kontextumschaltung nicht ein Kostenfaktor, wenn man überhaupt mit Threads arbeitet?" Sie haben sicherlich nicht Unrecht. Sie haben zwar keine direkte Kontrolle darüber, wie teuer das Signalisieren oder Aufwecken von Threads ist, aber Sie können steuern, wie oft diese Vorgänge stattfinden.
Eine Lösung, um zu vermeiden, dass Arbeiter ohne Grund geweckt werden, besteht darin, sie nur dann zu wecken, wenn Sie vermuten, dass es viele Aufgaben in der Warteschlange gibt, die die Kosten für das Wecken rechtfertigen. Dies kann durch Dosierung geschehen: Anstatt die Arbeiter zu benachrichtigen, sobald Sie einen Auftrag planen, fügen Sie den Auftrag zu einer Liste hinzu und spülen zu bestimmten Zeiten diesen Stapel von Aufträgen in das Auftragssystem, so dass eine angemessene Anzahl von Arbeitern zur gleichen Zeit geweckt wird.
Es besteht immer noch das Risiko, dass das eigentliche Aufwachen zu lange dauert, die gestapelten Aufträge sehr klein sind oder die Anzahl der Aufträge in einem Stapel einfach nicht sehr hoch ist. Im Allgemeinen gilt: Je mehr Aufträge Sie in den Batch einbeziehen, desto wahrscheinlicher ist es, dass der Overhead durch das grundlose Aufwecken von Threads vermieden wird. Unity verwaltet einen globalen Stapel, der bei jedem Aufruf von JobHandle.Complete() gespült wird. Wenn Sie also explizit auf die Beendigung eines Auftrags warten müssen, versuchen Sie, dies so spät und so selten wie möglich zu tun, und bevorzugen Sie im Allgemeinen die Planung von Aufträgen mit Auftragsabhängigkeiten, um den sicheren Zugriff auf die Daten bestmöglich zu kontrollieren.
Vielleicht fragen Sie sich auch: "Wenn das Signalisieren von Threads und das Warten darauf, dass sie aufwachen bzw. schlafen gehen, reiner Overhead ist, warum halten wir unsere Threads dann nicht die ganze Zeit wach und suchen nach Arbeit?" Wenn sich viele Aufträge in der Warteschlange befinden, kann dies sogar auf natürliche Weise geschehen. Solange das Betriebssystem den Worker-Thread nicht als weniger prioritär einstuft als andere Arbeiten (oder er explizit in Zeitscheiben eingeteilt ist und ausgelagert werden sollte, damit andere Threads ihren fairen Anteil an der CPU-Zeit erhalten - das hängt von Ihrer Plattform ab), werden die Worker-Threads fröhlich weiterarbeiten.
Wie bei den Funktionen PartialUpdateA und PartialUpdateB, die wir im ersten Teil gesehen haben, sind jedoch nicht alle Aufträge parallelisierbar und frei von Datenabhängigkeiten. Daher müssen Sie in der Regel warten, bis eine Teilmenge der Aufträge abgeschlossen ist, bevor Sie andere ausführen können. Infolgedessen kommt es zu Engpässen in der Parallelität eines Auftragsgraphen, wenn es weniger lauffähige Aufträge (Aufträge ohne ausstehende Abhängigkeiten) als Arbeitsthreads gibt, was dazu führt, dass einige Arbeiter nichts Produktives mehr zu tun haben.
Wenn Sie Worker-Threads nicht immer schlafen lassen, können Sie auf eine Reihe von Problemen stoßen. Wenn Worker-Threads ständig nach neuen Aufträgen suchen und keine finden, gilt dies als "beschäftigtes Warten" oder als Arbeit, die verschwenderisch ist und das Programm nicht voranbringt. Alle Kerne mit maximaler Parallelität laufen zu lassen, ohne dass das Spiel voranschreitet, geht zu Lasten der Akkulaufzeit. Und nicht nur das: Wenn ein Kern keine Leerlaufzeit hat, steigt die Temperatur der CPU ohne ausreichende Kühlung an, was zum Downclocking führt - also zum langsameren Betrieb, um Schäden durch Überhitzung zu vermeiden. Auf mobilen Plattformen ist es sogar nicht ungewöhnlich, dass ganze CPU-Kerne vorübergehend deaktiviert werden, wenn sie zu heiß werden. Für ein Jobsystem ist es sehr wichtig, die Kerne effizient nutzen zu können. Es muss also ein Gleichgewicht gefunden werden zwischen dem Einschlafen der Arbeiter und der ständigen Suche nach neuen Jobs in der Hoffnung, dass sie Glück haben.
Ein weiterer Bereich, der im obigen Design Overhead erzeugen kann, ist die sperrfreie Warteschlange und der Stack. Wir werden hier nicht auf alle Feinheiten der Implementierung dieser Datenstrukturen eingehen, aber ein gemeinsames Merkmal sperrfreier Implementierungen ist die Verwendung einer Compare-and-Swap-Schleife (CAS). Sperrfreie Algorithmen verwenden keine sperrenden Synchronisationsprimitive, um einen sicheren Zugriff auf den gemeinsamen Zustand zu ermöglichen, sondern verwenden stattdessen atomare Anweisungen, um atomare Operationen höherer Ordnung, wie z.B. das Einfügen eines Elements in eine Warteschlange, sorgfältig und thread-sicher zu erstellen. Allerdings können sperrfreie Algorithmen immer noch verhindern, dass ein Thread fortschreitet, bis ein anderer abgeschlossen ist. Sie können auch sekundäre Auswirkungen auf die CPU-Befehls- und Speicherpipelines haben, was die Leistungsskalierung beeinträchtigt. ("wartungsfreie" Algorithmen würden es allen Threads ermöglichen, immer voranzukommen, aber das bietet in der Praxis nicht immer die beste Gesamtleistung).
Hier ein Beispiel für das Hinzufügen einer Zahl zu einer Mitgliedsvariablen, m_Sum, mit einer CAS-Schleife:
int Add(int val)
{
int newSum;
do
{
// Load the current value we want to update
var oldSum = m_Sum;
// Compute new value we want to store
newSum = oldSum + val;
// Attempt to write the new value. CompareExchange returns
// the value seen inside m_Sum when writing newSum to m_Sum.
// If newSum doesn't match oldSum, we will retry the loop
// since it means another thread wrote to the memory before us.
// If we wrote our value without this check, we might
// write an incorrect value
}while (oldSum != Interlocked.CompareExchange(ref m_Sum, newSum, oldSum));
return newSum ;
}CAS-Schleifen beruhen auf der Anweisung compare-and-swap (hier verwenden wir die C# Interlocked-Bibliothek, die die Plattformspezifika abstrahiert), die "zwei Werte auf Gleichheit vergleicht und, wenn sie gleich sind, den ersten Wert ersetzt". Da wir möchten, dass sich die Benutzer der Funktion Add() keine Sorgen machen müssen, dass diese Funktion möglicherweise fehlschlägt, wird eine Schleife verwendet, um es erneut zu versuchen, falls sie fehlschlägt, weil ein anderer Thread uns bei der Aktualisierung von m_Sum zuvorgekommen ist.
Diese Wiederholungsschleife ist im Wesentlichen eine "busy-wait" Schleife. Dies hat unangenehme Auswirkungen auf die Leistungsskalierung: Wenn mehrere Threads gleichzeitig in die CAS-Schleife eintreten, verlässt immer nur einer die Schleife, so dass die Operationen, die jeder Thread ausführt, serialisiert werden. Glücklicherweise machen CAS-Schleifen in der Regel absichtlich wenig Arbeit, aber es kann trotzdem große negative Auswirkungen auf die Leistung haben. Je mehr Kerne die Schleife parallel ausführen, desto länger braucht jeder Thread, um die Schleife abzuschließen, während die Threads miteinander konkurrieren.
Da CAS-Schleifen auf atomare Lese- und Schreibvorgänge im gemeinsamen Speicher angewiesen sind, muss jeder Thread seine Cache-Zeilen in der Regel bei jeder Iteration ungültig machen, was zusätzlichen Overhead verursacht. Dieser Overhead kann im Vergleich zu den Kosten für die Wiederholung der Berechnungen innerhalb der CAS-Schleife (im obigen Fall die Wiederholung der Arbeit der Addition zweier Zahlen) sehr teuer sein. Wie hoch die Kosten sind, kann also auf den ersten Blick nicht offensichtlich sein.
Unter dem 2017.3 Job Scheduler suchten die Worker-Threads, wenn sie keine Jobs ausführten, nach Arbeit in einem gemeinsam genutzten, sperrfreien Stack oder einer Warteschlange. Beide Datenstrukturen verwendeten mindestens eine CAS-Schleife, um Arbeit aus der Datenstruktur zu entfernen. Je mehr Kerne also zur Verfügung standen, desto höher waren die Kosten für die Entnahme von Arbeit aus dem Stack oder der Warteschlange, wenn die Datenstrukturen konkurrierten. Insbesondere bei kleinen Aufträgen verbrachten die Arbeits-Threads proportional mehr Zeit mit der Suche nach Arbeit in der Warteschlange oder im Stapel.
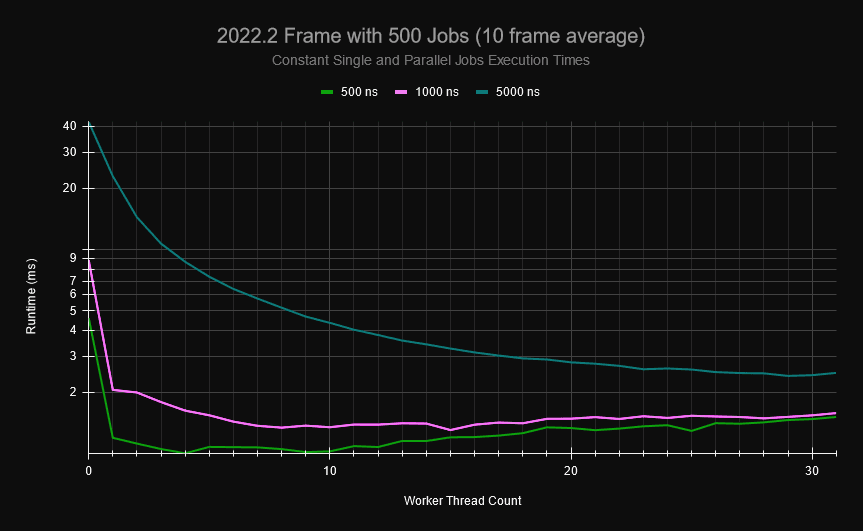
In einem kleinen Projekt habe ich deterministische Jobgraphen erstellt, die ein typisches Spiel für seine Frame-Aktualisierung haben könnte. Das Diagramm unten besteht aus Einzelaufträgen und parallelen Aufträgen (jeder parallelisiert in 1-100 parallele Aufträge), wobei jeder Auftrag 0-10 Auftragsabhängigkeiten haben kann und der Hauptthread gelegentlich explizite Synchronisierungspunkte hat, an denen er auf die Beendigung bestimmter Aufträge warten muss, bevor er weitere plant. Wenn ich 500 Aufträge im Auftragsdiagramm generiere und jedem Auftrag eine feste Ausführungszeit zuweise (jeder Teil eines parallelen Auftrags benötigt ebenfalls diese Zeit), können Sie sehen, dass der Overhead im Auftragssystem mit der Anzahl der verwendeten Kerne zunimmt.

Bei Aufträgen, die 0,5μs dauern, aktualisiert sich der Rahmen bei 20 Arbeitern so schnell wie ohne das Auftragssystem und läuft fast doppelt so langsam, wenn ich alle Kerne meines Rechners verwende. Standardmäßig werden in Unity alle Kerne verwendet, so dass bei 1μs-Aufträgen trotz der Verwendung von 31 Worker-Threads fast keine Leistungssteigerung zu verzeichnen ist. Dies ist eine direkte Folge des hohen Konkurrenzdrucks auf die sperrfreie Warteschlange und den Stack. Glücklicherweise sind die Benutzeraufträge in der Regel größer und können diesen Overhead verbergen. Das Problem der Skalierung ist jedoch vorhanden, und kleine Aufträge sind immer noch häufig genug (insbesondere bei parallelen Aufträgen). Selbst bei der Verwendung größerer Aufträge können Ihre Planungsmuster und die Zeitplanung der Worker aufgrund von Konflikten mit dem globalen, sperrfreien Stack und der Warteschlange im Job Scheduler große Mengen an Overhead verursachen.
Sie sehen also, dass es einige Bereiche gibt, die unser Team angehen musste, um den Overhead im Jobsystem zu reduzieren, sowohl auf Seiten von Unity als auch auf Seiten des Spieleentwicklers:
- Vermeiden Sie den Stillstand des Haupt-Threads:
- Die Signalisierung zum Aufwecken von Worker-Threads ist teuer - beschränken Sie dies auf ein Minimum.
- Die Änderung von Zuständen auf dem Haupt-Thread, die von Worker-Threads gemeinsam genutzt werden, führt wahrscheinlich zu Cache-Ungültigkeiten und potenziellem Busy-Waiting.
- Der Hauptthread sollte Aufträge häufig planen - vermeiden Sie es, explizit auf Aufträge zu warten, die .Complete() ausführen. Ziehen Sie es vor, Aufträge mit Abhängigkeiten zu übermitteln.
- Vermeiden von Stalls auf Worker-Threads:
- Die Effizienz der Worker-Threads wirkt sich direkt auf die Parallelität aus. Vermeiden Sie, wenn möglich, den Wettbewerb um gemeinsam genutzte Ressourcen.
- Das Warten auf Worker-Threads belastet die Akkulaufzeit und kann zu einem Downclocking aufgrund von Temperaturerhöhungen führen.
Unity kann zwar nicht ändern, wie viele Jobs Benutzer in ihren Spielen einreichen, aber es gibt eine ganze Reihe von Problemen, die unsere Ingenieure mit einem anderen Job Scheduler-Ansatz angehen können. In der Version 2022.2 gliedert sich der Job Scheduler auf einer hohen Ebene in ein paar grundlegende Komponenten:
- Array von Arbeits-Threads
- Array von Warteschlangen für Aufträge
- Array von Semaphore
Dies ist dem vorherigen Job Scheduler sehr ähnlich. Der Hauptunterschied besteht jedoch darin, dass der gemeinsame Status des Hauptthreads und der Worker-Threads aufgehoben wird. Stattdessen machen wir die Warteschlangen und Semaphoren (oder Futex auf Plattformen, die es unterstützen) lokal für jeden Worker-Thread. Wenn der Hauptthread einen Auftrag plant, wird dieser in die Warteschlange des Hauptthreads eingereiht und nicht in eine globale Warteschlange.
Ähnlich verhält es sich, wenn ein Worker-Thread einen Auftrag einplanen muss (z.B. wenn ein Job in seinem Execute einen Auftrag einplant), dann wird dieser Auftrag in der eigenen Warteschlange des Workers eingeplant und nicht in der Warteschlange des Hauptthreads. Dies reduziert den Speicherverkehr, da die Worker die Häufigkeit der Invalidierung von Cache-Zeilen reduzieren, wenn sie in eine Warteschlange schreiben. Daher lesen/schreiben die Worker nicht alle Warteschlangen mit der gleichen Häufigkeit.
Auch die Worker-Schleife hat sich geändert, da nun mehr Warteschlangen zur Verfügung stehen:
while(!scheduler.isQuitting)
{
// Take a job from our worker thread’s local queue
Job* pJob = m_worker_queue[m_workerId].dequeue();
// If our queue is empty try to steal work from someone
// else's queue to help them out.
if(pJob == nullptr) {
pJob = StealFromOtherQueues()
}
if(pJob) {
// If we found work, there may be more conditionally
// wake up other workers as necessary
WakeWorkers();
ExecuteJob(pJob);
}
// Conditionally go to sleep (perhaps we were told there is a
// parallel job we can help with)
else if(ShouldSleep())
{
// Put the thread to sleep until more jobs are scheduled
m_semaphores[m_workerId].Wait(1);
}
}Arbeitnehmer suchen in ihrer eigenen Warteschlange nach Arbeit und sehen nur dann in die Warteschlangen anderer Arbeitnehmer, wenn ihre eigene leer ist. Da die Arbeiter ihre eigenen Warteschlangen für das Ab- und Einreihen von Arbeit bevorzugen, wird die Anzahl der Konflikte in einer einzelnen Warteschlange reduziert.
Ein weiterer Unterschied besteht darin, wie Threads zum Aufwachen signalisiert werden. Die Worker-Threads sind nun dafür verantwortlich, andere Worker-Threads aufzuwecken, und der Haupt-Thread ist dafür verantwortlich, dass mindestens ein Worker-Thread wach ist, wenn er einen Auftrag plant.
Durch diese Änderung der Zuständigkeiten kann der Haupt-Thread übermäßigen Overhead vermeiden, da er nicht mehr allein für das Aufwecken von Threads verantwortlich sein muss, wenn parallele Aufträge eingereicht werden. Stattdessen führt das Jobsystem eine Überwachung durch, um zu wissen, ob es überhaupt Arbeiter wecken muss. Der Hauptthread kann dafür sorgen, dass ein Worker immer wach ist, um Aufträge zu bearbeiten. Wenn Worker aufwachen und einen Auftrag in ihrer eigenen Warteschlange oder in der eines anderen finden, können sie anderen Workern signalisieren, dass sie aufwachen und bei Bedarf helfen, die Warteschlange zu leeren.

Die Trennung der Warteschlangen für die Worker bietet auch einige interessante Spielräume für die Konfiguration und Optimierung, die unser Team weiter ausbaut und verbessert. In der Version 2022.2 sollten die Benutzer geringere Kosten für das Aufwecken von Worker-Threads durch den Haupt-Thread und einen verbesserten Durchsatz von Aufträgen auf Worker-Threads sehen, unabhängig davon, wie viele Kerne ihre Plattform hat. Darüber hinaus hat Unity die Trennung der Warteschlangen zwar nicht in 2021.3 LTS zurückportiert, aber wir haben die Design-Änderung zurückgebracht, damit die Worker-Threads für die gegenseitige Signalisierung verantwortlich sind und nicht nur der Haupt-Thread. Der hohe Jobsystem-Overhead auf dem Haupt-Thread aufgrund der Signalisierung der globalen Semaphore sollte ab 2021.3.14f1 kein Problem mehr sein.
Wenn Sie Fragen haben oder mehr erfahren möchten, besuchen Sie uns im C# Job System Forum. Sie können mich auch direkt über den Unity Discord unter dem Benutzernamen @Antifreeze#2763 erreichen. Achten Sie auf neue technische Blogs von anderen Unity-Entwicklern im Rahmen der fortlaufenden Serie Tech from the Trenches.