Améliorer la mise à l’échelle des performances du système d’emploi en 2022.2 – partie 2 : Aérien


Les versions 2022.2 et 2021.3.14f1 ont amélioré le coût de planification et la mise à l'échelle des performances du système de tâches Unity . Dans la première partie de cet article en deux parties sur les nouveautés des systèmes de travail, j'ai fourni quelques informations générales sur la programmation parallèle et pourquoi vous pourriez utiliser un système de travail. Pour la deuxième partie, examinons plus en détail ce qu'est la surcharge du système de travail et l'approche d'Unity pour l'atténuer.
La surcharge désigne tout le temps que le processeur passe sans exécuter votre tâche, à partir du moment où vous commencez à la planifier jusqu'au moment où elle se termine, débloquant ainsi toutes les tâches en attente. En gros, il y a deux domaines dans lesquels le temps est passé :
1. La couche API de travail C#
2. Le planificateur de tâches natif (qui gère et exécute toutes les tâches planifiées C# et, en interne, C++)
L’objectif de l’API C# Job est de fournir un moyen sûr d’accéder au système de travail natif. Bien qu'il s'agisse d'une couche de liaison pour la transition de C# vers C++, c'est également une couche qui vous permet d'empêcher la planification accidentelle de tâches C# qui se heurteront à des conditions de concurrence ou à des blocages lors de l'accès à NativeContainers à partir d'une tâche.
De plus, cette séparation offre une manière plus riche de créer des emplois eux-mêmes. Au niveau de la couche C++, les tâches ne sont qu'un pointeur vers des données et un pointeur de fonction. Mais avec l' API C# en plus, vous pouvez personnaliser les types de tâches que vous planifiez, ce qui permet un meilleur contrôle sur la manière dont les données de tâche doivent être divisées et parallélisées pour s'adapter aux cas d'utilisation spécifiques à l'utilisateur.
Lors de la planification d'une tâche, la couche de liaison de tâche C# copie la structure de tâche dans une allocation de mémoire non gérée. Cela permet de déconnecter la durée de vie de la structure de tâche C# de la durée de vie de la tâche dans le système de tâches, car celle-ci est affectée par les dépendances de la tâche et la charge globale sur la plateforme. Le système de tâches effectue ensuite des contrôles de sécurité de manière conditionnelle dans les versions en mode de lecture de l'éditeur pour garantir qu'une tâche peut être exécutée en toute sécurité.
Ces étapes sont importantes, mais elles ne sont pas gratuites et contribuent aux frais généraux du système d’emploi. Étant donné que la taille des tâches peut varier, ainsi que le nombre de NativeContainers et de dépendances qu'une tâche peut avoir, le coût de copie des tâches et de validation de leur sécurité n'est pas fixe. Pour cette raison, il est important Unity maintienne les coûts à un niveau faible et limité à une complexité de calcul linéaire.
Dans le Tech Stream 2021.2, l'équipe d'ingénierie a apporté des améliorations significatives au système de sécurité des tâches en mettant en cache le résultat du contrôle de sécurité pour les tâches individuelles. Ceci est particulièrement important, car le système de sécurité doit comprendre des chaînes entières de dépendances de tâches et chaque référence de mémoire native que contiennent toutes les tâches pour comprendre à quelles informations de dépendance il peut manquer et à quelle tâche une dépendance doit être ajoutée. Cela peut entraîner une quantité non linéaire d'éléments sur lesquels itérer lors de la planification (c'est-à-dire, pour chaque tâche et ses dépendances, vérifiez l'accès en lecture/écriture pour chaque NativeContainer auquel la tâche fait référence et toute tâche faisant référence aux NativeContainers).
Cependant, Unity peut tirer parti du fait que les tâches C# ne sont planifiées qu'une à la fois et vérifier la sécurité pendant cette planification. Au lieu de réanalyser tous les travaux à chaque planification, nous pouvons rapidement déterminer si la revalidation des chaînes de dépendance des travaux est nécessaire ou non, ce qui permet d'ignorer de grandes quantités de travail. Même pour les petites chaînes de dépendance professionnelle, cela réduit considérablement le coût des contrôles de sécurité des emplois. Idéalement, il ne devrait y avoir aucune raison de désactiver les contrôles de sécurité des emplois lors du développement (les contrôles de sécurité des emplois ne sont pas activés dans les versions joueur/expédition).
Chaque fois qu'une tâche C# ou C++ est planifiée pour être exécutée, elle passe par le planificateur de tâches. Le rôle du planificateur est de :
- Suivre les tâches via les poignées de tâches
- Gérer les dépendances des tâches, en veillant à ce que les tâches ne commencent à s'exécuter qu'une fois toutes les dépendances terminées
- Gérer les « threads de travail », qui sont les threads qui exécuteront les tâches
- Assurez-vous que les tâches sont exécutées le plus rapidement possible, ce qui signifie généralement qu'elles doivent s'exécuter en parallèle lorsque les dépendances le permettent
De plus, bien que l’ API C# Job permette uniquement de planifier des tâches à partir du thread principal, le planificateur de tâches doit prendre en charge plusieurs threads planifiant des tâches en même temps. Cela est dû au fait que le moteur Unity sous-jacent utilise de nombreux threads qui planifient des tâches et peuvent même planifier des tâches à partir de tâches. Cette fonctionnalité présente des avantages et des inconvénients, mais nécessite un examen beaucoup plus approfondi pour garantir son exactitude et ajoute l'exigence selon laquelle le planificateur de tâches doit être thread-safe.
Dans la version 2017.3, l'apparence de base du planificateur de tâches était :
- File d'attente pour les emplois
- Pile pour les emplois
- Sémaphore
- Tableau de threads de travail
L'utilisation typique suit ce modèle : Lorsque les tâches sont planifiées, elles sont placées dans une file d'attente globale, sans verrouillage, à producteurs multiples et à consommateurs multiples, qui représente les tâches prêtes à être traitées par un thread de travail. Le thread principal signale ensuite à l'aide d'un sémaphore de réveiller les threads de travail.
Le nombre de travailleurs auxquels il est demandé de se réveiller dépend du type de tâche planifiée : les tâches uniques telles que IJob ne réveillent qu'un seul travailleur, car ce type de tâche ne répartit pas le travail sur plusieurs threads de travail. Les jobs IJobParallelFor représentent cependant plusieurs éléments de travail qui peuvent être exécutés en parallèle. Lorsqu'un travail est planifié, il peut y avoir de nombreuses pièces sur lesquelles certains ou tous les travailleurs doivent intervenir en même temps. Ainsi, le planificateur détermine combien de travailleurs peuvent potentiellement aider et réveille ce nombre.
Une fois réveillés, les threads de travail sont l'endroit où le travail réel se déroule. En 2017.3, ils étaient responsables de retirer un travail de la file d'attente des travaux, en s'assurant que toutes les dépendances de travail pertinentes étaient complètes. S'ils n'étaient pas encore terminés, le travail et les dépendances incomplètes seraient ajoutés à une pile sans verrou afin de passer au début de la file d'attente pour essayer de s'exécuter à nouveau. Les threads de travail font cela en boucle jusqu'à ce que le moteur signale qu'il veut s'arrêter ou qu'il n'y ait plus de tâches dans la pile et la file d'attente. À ce stade, les threads de travail se mettent en veille en attendant un signal provenant du sémaphore du thread principal.
while(!scheduler.isQuitting)
{
// Usually empty unless we need to prioritize a dependency
// to unblock a job we got from the queue. Alternatively
// pieces of work from a IJobParallelFor job can end up here to let
// many workers help finish IJobParallelFor work quickly
Job* pJob = m_stack.pop();
if(!pJob)
Job* pJob = m_queue.dequeue();
if(pJob) {
// ExecuteJob if all dependencies are complete, otherwise
// push this job and the dependencies to the stack and try again
if(EnsureDependenciesAreCompleteOtherwiseAddToStack(pJob))
ExecuteJob(pJob);
}
else
{
// Put the thread to sleep until more jobs are scheduled
m_semaphore.Wait(1);
}
}Le planificateur de tâches crée autant de threads de travail qu'il y a de cœurs virtuels sur le processeur, moins un par défaut. L'intention ici est que chaque thread de travail s'exécute sur son propre cœur de processeur, tout en laissant un cœur de processeur libre pour que le thread principal puisse continuer à s'exécuter. En pratique, sur les plateformes où un cœur n'est pas réservé aux processus non liés au jeu, il peut être préférable de réduire le nombre de threads de travail afin que les calculs effectués par les threads du système d'exploitation ou du pilote n'entrent pas en concurrence avec les threads de travail principaux ou de travail du jeu.
Étant donné que le thread principal est l'endroit principal à partir duquel les tâches sont planifiées, il est très important de ne pas retarder le thread principal. Cela affecte directement le nombre de tâches entrant dans le système de tâches et donc le degré de parallélisme qui peut se produire dans une trame.
Avec le thread principal planifiant théoriquement de nombreuses tâches et le reste des cœurs du processeur exécutant ces tâches, nous devrions être en mesure de maximiser la quantité de travail parallèle pouvant être effectuée sur le processeur et de permettre aux performances d'évoluer à mesure que le matériel évolue. Si nous avions plus de threads de travail que de cœurs, le système d'exploitation pourrait changer de contexte pour le thread principal et passer à un thread de travail. L'exécution d'un thread de travail supplémentaire peut aider à vider votre file d'attente de tâches plus rapidement, mais cela empêcherait certainement de nouveaux travaux d'entrer dans la file d'attente, ce qui a finalement un effet négatif plus important sur les performances.
L’approche du planificateur de tâches ci-dessus présente quelques problèmes potentiels qui peuvent entraîner une surcharge du système de tâches. Regardons quelques exemples.
Le thread principal planifie un IJob (travail non parallèle) sans dépendances :
- Un travail est ajouté à la file d'attente et un thread de travail reçoit un signal pour se réveiller
- Un thread de travail se réveille
- Le travailleur exécute le travail
- Le travailleur vérifie s'il reste des tâches à exécuter
- Le travailleur va dormir car il n'y a plus de travail
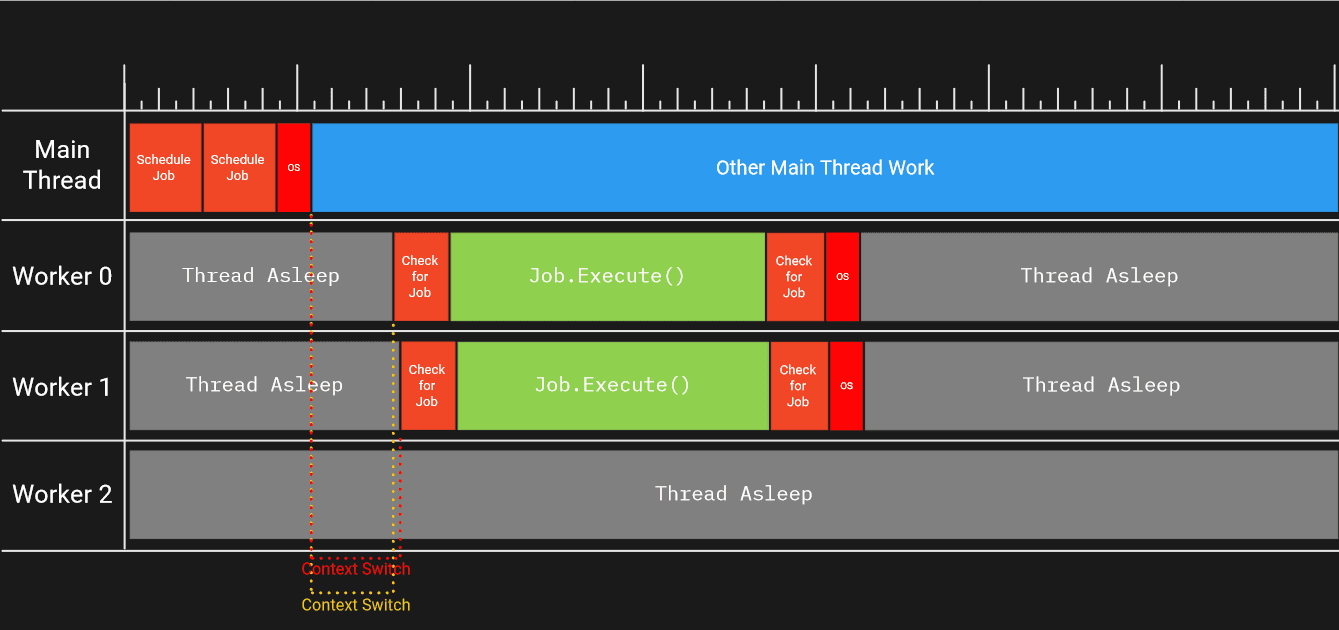
Une fois que le thread principal signale à l'aide du sémaphore du planificateur de tâches, l'un des threads de travail en veille (pas nécessairement le thread de travail 0) se réveillera. Le réveil et le changement de contexte prennent un certain temps sur le noyau du travailleur. C'est parce que, pendant que le thread de travail est en veille, le cœur du processeur sur lequel le thread de travail finira par s'exécuter faisait probablement quelque chose - peut-être l'exécution d'un autre thread généré par le jeu ou d'un autre processus sur la machine qui utilisait le thread.
Pour permettre aux threads d'être suspendus et repris ultérieurement, l'état du registre d'un thread doit être enregistré, les pipelines d'instructions doivent être vidés et l'état du thread commuté doit être restauré. Même la signalisation du thread prend du temps sur le noyau du thread principal, puisque la notification du thread à réveiller est gérée par le système d'exploitation. En fin de compte, tout cela signifie que du travail est effectué sur le noyau du thread principal et sur le noyau du thread de travail, ce qui n'est pas notre travail et constitue donc une surcharge que nous souhaitons réduire.

La rapidité avec laquelle les travailleurs peuvent être informés et le temps nécessaire à l'exécution d'une tâche individuelle peuvent également avoir un impact sur le système. Par exemple, si vous prenez le cas d’utilisation ci-dessus mais que vous planifiez deux tâches au lieu d’une :
- Un travail est ajouté à la file d'attente et un thread de travail reçoit un signal pour se réveiller
- Le deuxième travail est ajouté à la file d'attente et un thread de travail reçoit un signal pour se réveiller
- Dans un certain ordre, mais deux fois :
- Un thread de travail se réveille
- Un travailleur exécute le travail
- Le travailleur vérifie s'il reste des tâches à exécuter
- Le travailleur va dormir car il n'y a plus de travail
Si le timing est bon, vous avez deux travailleurs travaillant en parallèle sur le chantier.

Cependant, si l'une des tâches est trop petite et/ou qu'il faut trop de temps pour signaler et réveiller les deux travailleurs, l'un d'eux peut voler tout le travail de la file d'attente et, par conséquent, nous avons signalé un travailleur sans raison.

Ce type de manque de travail et de cycle veille <-> sommeil peut s'avérer assez coûteux et limiter la quantité de parallélisme offerte par le système de travail.
Vous vous demandez peut-être : « Les frais généraux liés à la signalisation des threads et au changement de contexte ne constituent-ils pas un coût d'exploitation lorsque l'on traite avec des threads en premier lieu ? » Vous n’avez certainement pas tort. Mais, même si vous n'avez pas de contrôle direct sur le coût de la signalisation ou du réveil des threads, vous pouvez contrôler la fréquence à laquelle ces opérations se produisent.
Une solution pour éviter de réveiller les travailleurs sans raison est de les réveiller uniquement lorsque vous soupçonnez qu'il y a beaucoup d'éléments de travail dans la file d'attente que les travailleurs doivent prendre en charge, justifiant ainsi le coût du réveil. Cela peut être fait par lots : Au lieu de signaler aux travailleurs dès que vous planifiez une tâche, ajoutez la tâche à une liste et, à des moments précis, envoyez ce lot de tâches dans le système de tâches, réveillant ainsi un nombre approprié de travailleurs en même temps.
Il existe toujours un risque que le réveil réel prenne trop de temps, que les tâches par lots soient très petites ou que le nombre de tâches dans un lot ne soit tout simplement pas très élevé. En général, plus vous incluez de tâches dans le lot, plus vous avez de chances d'éviter la surcharge due au réveil des threads sans raison. Unity maintient un lot global qui est vidé chaque fois qu'un appel à JobHandle.Complete() est appelé. Ainsi, si vous devez explicitement attendre qu'une tâche soit terminée, essayez de le faire le plus tard et le moins souvent possible, et préférez généralement planifier des tâches avec des dépendances de tâches pour mieux contrôler l'accès sécurisé aux données.
Vous vous demandez peut-être aussi : « Si signaler les threads et attendre qu'ils se réveillent/s'endorment est une simple surcharge, pourquoi ne gardons-nous pas nos threads éveillés en permanence à la recherche de travail ? » Lorsqu'il y a beaucoup de tâches dans la file d'attente, cela peut en fait se produire naturellement. À moins que le système d’exploitation ne considère que le thread de travail a une priorité inférieure à celle d’un autre travail (ou qu’il est explicitement divisé en tranches de temps et doit être échangé pour donner aux autres threads leur juste part de temps CPU – cela dépend de votre plate-forme), les threads de travail continueront à fonctionner avec plaisir.
Cependant, comme pour les fonctions PartialUpdateA et PartialUpdateB que nous avons vues dans la première partie, tous les travaux ne sont pas parallélisables et exempts de dépendances de données. Par conséquent, vous devez généralement attendre qu’un sous-ensemble de tâches soit terminé avant de pouvoir en exécuter d’autres. Par conséquent, nous observons des goulots d'étranglement dans le parallélisme d'un graphique de tâches lorsqu'il y a moins de tâches exécutables (tâches sans dépendances en suspens) que de threads de travail, ce qui fait que certains travailleurs n'ont plus rien de productif à faire.
Si vous ne laissez jamais les threads de travail dormir, vous pouvez rencontrer une poignée de problèmes. Lorsque les threads de travail recherchent constamment de nouvelles tâches et n'en trouvent aucune, cela est considéré comme une «attente occupée» ou un travail inutile qui ne fait pas progresser le programme. Garder tous les cœurs en fonctionnement avec un parallélisme maximal, mais sans faire progresser le jeu, consomme de la batterie. De plus, si un cœur n'a pas de temps d'inactivité, sans refroidissement suffisant, la température du processeur augmentera, ce qui entraînera un downclocking - un fonctionnement plus lent pour éviter les dommages dus à la surchauffe. En fait, sur les plateformes mobiles, il n’est pas rare que des cœurs de processeur entiers soient temporairement désactivés s’ils deviennent trop chauds. Pour un système de travail, il est très important de pouvoir utiliser les cœurs de manière efficace. Il faut donc trouver un équilibre entre endormir les travailleurs et les faire constamment tourner en rond à la recherche de nouveaux emplois, en espérant qu'ils aient de la chance.
Un autre domaine qui peut générer une surcharge dans la conception ci-dessus est la file d'attente et la pile sans verrouillage. Nous n'entrerons pas dans toutes les nuances de la mise en œuvre de ces structures de données, mais un trait commun des implémentations sans verrouillage est l'utilisation d'une boucle de comparaison et d'échange (CAS). Les algorithmes sans verrouillage n'utilisent pas de primitives de synchronisation de verrouillage pour fournir un accès sécurisé à l'état partagé, mais utilisent plutôt des instructions atomiques pour créer soigneusement des opérations atomiques d'ordre supérieur telles que l'insertion d'un élément dans une file d'attente de manière thread-safe. Cependant, peut-être de manière peu intuitive, les algorithmes sans verrouillage peuvent toujours empêcher un thread de progresser jusqu'à ce qu'un autre soit terminé. Ils peuvent également avoir des effets secondaires sur les pipelines d'instructions et de mémoire du processeur, nuisant à la mise à l'échelle des performances. (Les algorithmes «sans attente» permettraient à tous les threads de toujours progresser, mais cela ne fournit pas toujours les meilleures performances globales dans la pratique.)
Voici un exemple artificiel d'ajout d'un nombre à une variable membre, m_Sum, avec une boucle CAS :
int Add(int val)
{
int newSum;
do
{
// Load the current value we want to update
var oldSum = m_Sum;
// Compute new value we want to store
newSum = oldSum + val;
// Attempt to write the new value. CompareExchange returns
// the value seen inside m_Sum when writing newSum to m_Sum.
// If newSum doesn't match oldSum, we will retry the loop
// since it means another thread wrote to the memory before us.
// If we wrote our value without this check, we might
// write an incorrect value
}while (oldSum != Interlocked.CompareExchange(ref m_Sum, newSum, oldSum));
return newSum ;
}Les boucles CAS s'appuient sur l'instruction compare-and-swap (ici nous utilisons la bibliothèque C# Interlocked qui fait abstraction des spécificités de la plateforme), qui « compare deux valeurs pour l'égalité et, si elles sont égales, remplace la première valeur ». Étant donné que nous voulons que les utilisateurs de la fonction Add() ne s'inquiètent pas de l'échec potentiel de cette fonction, une boucle est utilisée pour réessayer si elle échoue parce qu'un autre thread nous a devancé pour mettre à jour m_Sum.
Cette boucle de nouvelle tentative est, par essence, une boucle « occupé-attente ». Cela a des conséquences néfastes sur la mise à l’échelle des performances : Si plusieurs threads entrent dans la boucle CAS en même temps, un seul en sortira à la fois, sérialisant les opérations effectuées par chaque thread. Heureusement, les boucles CAS effectuent généralement une quantité de travail intentionnellement faible, mais elles peuvent néanmoins avoir des impacts négatifs importants sur les performances. À mesure que davantage de cœurs exécutent la boucle en parallèle, chaque thread mettra plus de temps à terminer la boucle pendant que les threads sont en conflit.
De plus, comme les boucles CAS reposent sur des lectures et écritures atomiques dans la mémoire partagée, chaque thread nécessite généralement que ses lignes de cache soient invalidées à chaque itération, ce qui entraîne une surcharge supplémentaire. Cette surcharge peut être très coûteuse par rapport au coût de refaire les calculs à l'intérieur de la boucle CAS (dans le cas ci-dessus, refaire le travail d'addition de deux nombres ensemble). Ainsi, le coût peut ne pas être évident à première vue.
Dans le planificateur de tâches 2017.3, lorsque les threads de travail n'exécutaient pas de tâches, ils recherchaient du travail dans une pile ou une file d'attente partagée et sans verrouillage. Ces deux structures de données utilisaient au moins une boucle CAS pour supprimer le travail de la structure de données. Ainsi, à mesure que davantage de cœurs devenaient disponibles, le coût de la récupération du travail depuis la pile ou la file d'attente augmentait lorsque les structures de données étaient en conflit. En particulier, lorsque les tâches étaient petites, les threads de travail passaient proportionnellement plus de temps à chercher du travail dans la file d'attente ou la pile.
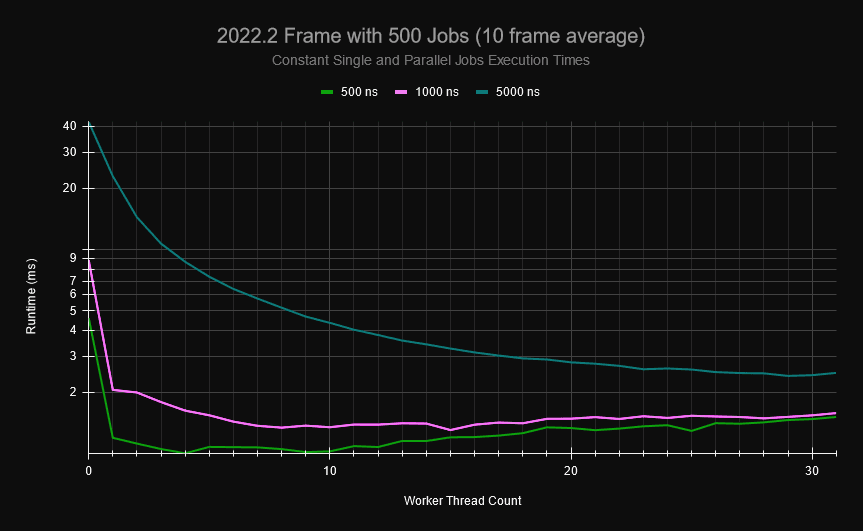
Dans un petit projet, j'ai généré des graphiques de tâches déterministes qu'un jeu typique peut avoir pour sa mise à jour d'image. Le graphique ci-dessous est composé de tâches uniques et de tâches parallèles (chacune se parallélisant en 1 à 100 tâches parallèles), où chaque tâche peut avoir 0 à 10 dépendances de tâches et le thread principal a des points de synchronisation explicites occasionnels où il doit attendre que certaines tâches se terminent avant d'en planifier d'autres. Si je génère 500 tâches dans le graphique de tâches et que je fais en sorte que chacune d'elles prenne un temps d'exécution fixe (chaque partie d'une tâche parallèle prend également ce temps), vous pouvez voir que, à mesure que davantage de cœurs sont utilisés, la surcharge du système de tâches augmente.

Pour les tâches qui prennent 0,5 µs, une fois qu'il y a 20 travailleurs, la trame se met à jour aussi rapidement que si vous n'utilisiez pas du tout le système de tâches, et s'exécute presque deux fois plus lentement lorsque vous utilisez tous les cœurs de ma machine. Par défaut, tous les cœurs sont utilisés dans Unity, donc avec des tâches de 1 μs, il n'y a presque aucune amélioration des performances malgré l'utilisation de 31 threads de travail. Il s’agit du résultat direct d’une forte contention sur la file d’attente et la pile sans verrouillage. Heureusement, les tâches utilisateur ont tendance à être plus volumineuses et peuvent masquer cette surcharge. Cependant, le problème de mise à l’échelle est là et les petits travaux sont encore assez courants (en particulier pour les travaux parallèles). Même lorsque vous utilisez des tâches plus volumineuses, vos modèles de planification et le calendrier des travailleurs peuvent entraîner des frais généraux importants en raison de conflits avec la pile et la file d'attente globales et sans verrouillage dans le planificateur de tâches.
À présent, vous pouvez voir qu'il y a quelques domaines que notre équipe doit aborder pour réduire les frais généraux du système de travail, à la fois du côté d'Unity et du côté du créateur du jeu :
- Éviter les blocages sur le thread principal :
- La signalisation pour réveiller les threads de travail est coûteuse – gardez-la au minimum.
- La modification de l'état du thread principal partagé avec les threads de travail est susceptible d'entraîner des invalidations du cache et une attente potentielle.
- Le thread principal doit planifier fréquemment les tâches – évitez d’attendre explicitement que les tâches soient terminées. Préférez plutôt soumettre des tâches avec des dépendances.
- Éviter les blocages sur les threads de travail :
- L’efficacité du thread de travail a un impact direct sur le parallélisme. Évitez autant que possible les conflits autour des ressources partagées.
- Les attentes occupées sur les threads de travail épuisent la durée de vie de la batterie et peuvent entraîner une baisse de fréquence en raison de l'augmentation de la température.
Bien Unity ne puisse pas modifier le nombre de tâches que les utilisateurs soumettent dans leurs jeux, il existe un nombre décent de problèmes que nos ingénieurs peuvent résoudre avec une approche différente du planificateur de tâches. Dans la version 2022.2, le planificateur de tâches, à un niveau élevé, se décompose en quelques composants de base :
- Tableau de threads de travail
- Tableau de files d'attente pour les travaux
- Tableau de sémaphores
Ceci est très similaire au planificateur de tâches précédent. Cependant, la principale différence est la suppression de l’état partagé entre le thread principal et les threads de travail. Au lieu de cela, nous rendons les files d'attente et les sémaphores (ou futex sur les plateformes qui le prennent en charge) locaux pour chaque thread de travail. Désormais, lorsque le thread principal planifie une tâche, celle-ci est placée dans la file d'attente du thread principal plutôt que dans une file d'attente globale.
De même, si un thread de travail doit planifier une tâche (par exemple, une tâche planifie une tâche dans son Exécution), cette tâche est planifiée dans la propre file d'attente du thread de travail plutôt que dans la file d'attente du thread principal. Cela réduit le trafic mémoire, car les travailleurs réduisent la fréquence d’invalidation des lignes de cache lorsqu’ils écrivent dans une file d’attente. De ce fait, les travailleurs ne lisent/écrivent pas dans toutes les différentes files d’attente à la même fréquence.
La boucle de travail a également changé, maintenant qu'il y a plus de files d'attente avec lesquelles travailler :
while(!scheduler.isQuitting)
{
// Take a job from our worker thread’s local queue
Job* pJob = m_worker_queue[m_workerId].dequeue();
// If our queue is empty try to steal work from someone
// else's queue to help them out.
if(pJob == nullptr) {
pJob = StealFromOtherQueues()
}
if(pJob) {
// If we found work, there may be more conditionally
// wake up other workers as necessary
WakeWorkers();
ExecuteJob(pJob);
}
// Conditionally go to sleep (perhaps we were told there is a
// parallel job we can help with)
else if(ShouldSleep())
{
// Put the thread to sleep until more jobs are scheduled
m_semaphores[m_workerId].Wait(1);
}
}Les travailleurs recherchent du travail dans leur propre file d'attente et ne consultent les files d'attente des autres travailleurs que lorsque la leur est vide. Étant donné que les travailleurs préfèrent disposer de leurs propres files d'attente pour retirer et mettre en file d'attente le travail, le niveau de conflit sur une file d'attente est réduit.
Une autre différence réside dans la manière dont les threads sont signalés pour se réveiller. Les threads de travail sont désormais responsables du réveil des autres threads de travail, et le thread principal est chargé de s'assurer qu'au moins un thread de travail est éveillé lorsqu'il planifie une tâche.
Ce changement de responsabilité permet au thread principal de supprimer une surcharge excessive puisqu'il n'a plus besoin d'être seul responsable du réveil des threads lorsque des tâches parallèles sont soumises. Au lieu de cela, le système de travail effectue un suivi pour savoir s'il doit réveiller des travailleurs. Le thread principal peut garantir qu'un travailleur est toujours éveillé pour progresser dans ses tâches et lorsque les travailleurs se réveillent et trouvent un travail dans leur propre file d'attente ou dans celle d'un autre, les travailleurs peuvent signaler aux autres travailleurs de se réveiller et d'aider à vider la file d'attente si nécessaire.

La séparation des files d'attente pour les travailleurs offre également une marge de manœuvre intéressante pour la configuration et les optimisations, que notre équipe continue d'ajouter et d'améliorer. En 2022.2, les utilisateurs devraient constater une réduction du coût du thread principal pour réveiller les threads de travail et une amélioration du débit des tâches sur les threads de travail, quel que soit le nombre de cœurs de leur plateforme. De plus, bien Unity n'ait pas rétroporté la séparation des files d'attente vers 2021.3 LTS, nous avons ramené le changement de conception pour rendre les threads de travail responsables de la signalisation mutuelle plutôt que du thread principal uniquement. La surcharge élevée du système de tâches sur le thread principal en raison de la signalisation du sémaphore global ne devrait plus être un problème à partir de 2021.3.14f1.
Si vous avez des questions ou souhaitez en savoir plus, visitez-nous sur le forum C# Job System. Vous pouvez également me contacter directement via le Discord Unity sous le nom d'utilisateur @Antifreeze#2763. Assurez-vous de surveiller les nouveaux blogs techniques d'autres développeurs Unity dans le cadre de la SérieTech from the Trenches.