Улучшение шкалирования производительности системы заданий в 2022.2 - часть 2: Накладные


В релизах 2022.2 и 2021.3.14f1 были улучшены стоимость планирования и масштабирование производительности системы заданий Unity. В первой части этой двухчастной статьи о том, что нового в системах заданий, я предложил некоторую справочную информацию о параллельном программировании и о том, почему Вы можете использовать систему заданий. Во второй части мы более подробно рассмотрим, что такое накладные расходы на систему заданий и какой подход Unity использует для их снижения.
Под накладными расходами понимается любое время, которое процессор тратит на невыполнение Вашего задания, с момента, когда Вы начали составлять расписание, до момента, когда оно завершится, разблокировав все ожидающие задания. В целом, есть две области, на которые тратится время:
1. Уровень C# Job API
2. Собственный планировщик заданий (который управляет и выполняет все запланированные задания на C# и, внутренне, на C++)
Цель C# Job API - предоставить безопасное средство доступа к родной системе заданий. Хотя это и связующий слой для перехода от C# к C++, это также слой, который позволяет Вам предотвратить случайное планирование заданий C#, которые будут сталкиваться с условиями гонки или тупиками при доступе к NativeContainers изнутри задания.
Кроме того, такое разделение обеспечивает более богатый способ создания рабочих мест. На уровне C++ задания - это просто указатель на некоторые данные и указатель на функцию. Но с помощью API на основе C# Вы можете настраивать типы заданий, которые Вы планируете, позволяя лучше контролировать то, как данные задания должны быть разделены и распараллелены, чтобы соответствовать конкретным пользовательским задачам.
При планировании задания уровень привязки заданий C# копирует структуру задания в неуправляемое распределение памяти. Это позволяет отделить время жизни структуры задания C# от времени жизни задания в системе заданий, поскольку на него влияют зависимости задания и общая нагрузка на платформу. Затем система заданий условно выполняет проверку безопасности в сборках Editor playmode, чтобы убедиться, что задание безопасно для выполнения.
Эти шаги важны, но они не бесплатны и вносят свой вклад в накладные расходы системы. Поскольку размер задания может варьироваться, равно как и количество NativeContainers и зависимостей, которые может иметь задание, стоимость копирования заданий и проверки их безопасности не является фиксированной. Поэтому важно, чтобы Unity сохраняла небольшие затраты и ограничивалась линейной вычислительной сложностью.
В 2021.2 Tech Stream команда инженеров внесла значительные улучшения в систему безопасности заданий, кэшируя результат проверки безопасности для отдельных ручек заданий. Это особенно важно, так как система безопасности должна понимать целые цепочки зависимостей между заданиями и каждую ссылку на родную память, которую содержат все задания, чтобы понять, какая информация о зависимостях может отсутствовать и к какому заданию следует добавить ту или иную зависимость. Это может привести к нелинейному количеству элементов для итераций при планировании (т.е. для каждого задания и его зависимостей проверьте доступ на чтение/запись для каждого NativeContainer, на который ссылается задание, и для любого задания, ссылающегося на NativeContainers).
Однако Unity может воспользоваться тем фактом, что задания в C# планируются только по одному, и проверить безопасность во время этого планирования. Вместо того, чтобы заново проверять все задания в каждом расписании, мы можем быстро определить, нужно ли перепроверять цепочки зависимостей между заданиями, что позволит пропустить большой объем работы. Даже для небольших цепочек зависимых работ это значительно снижает стоимость проверок безопасности работы. В идеале не должно быть причин отключать проверку безопасности заданий при разработке (проверка безопасности заданий не включена в сборках игроков/перевозчиков).
Когда задание на C# или C++ планируется к выполнению, оно проходит через планировщик заданий. Роль планировщика заключается в следующем:
- Отслеживайте задания с помощью ручек заданий
- Управляйте зависимостями заданий, гарантируя, что задания начнут выполняться только после завершения всех зависимостей
- Управляйте "рабочими потоками" - потоками, которые будут выполнять задания.
- Убедитесь, что задания выполняются как можно быстрее - обычно это означает, что они должны выполняться параллельно, если позволяют зависимости.
Кроме того, хотя C# Job API позволяет планировать задания только из главного потока, планировщик заданий должен поддерживать несколько потоков, планирующих задания одновременно. Это происходит потому, что движок Unity использует множество потоков, которые планируют задания и даже могут планировать задания внутри заданий. Эта функциональность имеет свои плюсы и минусы, но требует гораздо более тщательной проверки на корректность и добавляет требование, что планировщик заданий должен быть потокобезопасным.
В выпуске 2017.3 основной вид планировщика заданий был таким:
- Очередь на выполнение заданий
- Стек для работы
- Семафор
- Массив рабочих потоков
Типичное использование происходит следующим образом: По мере планирования заданий они попадают в глобальную очередь без блокировки, с несколькими производителями и несколькими потребителями, которая представляет задания, готовые к обработке рабочим потоком. Затем главный поток подает сигнал с помощью семафора, чтобы разбудить рабочие потоки.
Количество рабочих, которых нужно разбудить, зависит от типа планируемого задания - одиночные задания, такие как IJob, будят только одного рабочего, поскольку этот тип задания не распределяет работу между несколькими рабочими потоками. Задания IJobParallelFor, однако, представляют собой несколько частей работы, которые могут выполняться параллельно. В то время как запланирована одна работа, может быть много частей, с которыми некоторые или все работники должны помочь одновременно. Таким образом, планировщик определяет, сколько работников потенциально могут помочь, и будит это число.
После пробуждения рабочие потоки - это место, где происходит реальная работа. В версии 2017.3 они отвечали за удаление задания из очереди заданий, обеспечивая завершение всех соответствующих зависимостей задания. Если они еще не завершены, задание и неполные зависимости добавляются в стек без блокировки, чтобы переместиться в начало очереди для повторной попытки выполнения. Рабочие потоки делают это в цикле до тех пор, пока либо движок не подаст сигнал о том, что он хочет остановиться, либо в стеке и очереди больше нет заданий. В этот момент рабочие потоки переходят в спящий режим, ожидая сигнала от семафора главного потока.
while(!scheduler.isQuitting)
{
// Usually empty unless we need to prioritize a dependency
// to unblock a job we got from the queue. Alternatively
// pieces of work from a IJobParallelFor job can end up here to let
// many workers help finish IJobParallelFor work quickly
Job* pJob = m_stack.pop();
if(!pJob)
Job* pJob = m_queue.dequeue();
if(pJob) {
// ExecuteJob if all dependencies are complete, otherwise
// push this job and the dependencies to the stack and try again
if(EnsureDependenciesAreCompleteOtherwiseAddToStack(pJob))
ExecuteJob(pJob);
}
else
{
// Put the thread to sleep until more jobs are scheduled
m_semaphore.Wait(1);
}
}Планировщик заданий создает столько рабочих потоков, сколько виртуальных ядер имеется на CPU, минус одно по умолчанию. Смысл в том, чтобы каждый рабочий поток работал на своем ядре CPU, оставляя одно ядро CPU свободным для продолжения работы основного потока. На практике, на платформах, где ядро не зарезервировано для неигровых процессов, может быть лучше уменьшить количество рабочих потоков, чтобы вычисления, выполняемые операционной системой или потоками драйверов, не конкурировали с основными или рабочими потоками игры.
Поскольку основной поток - это основное место, откуда планируются задания, очень важно не задерживать основной поток. Это напрямую влияет на количество заданий, поступающих в систему заданий, и, следовательно, на количество параллелей, которые могут возникнуть в кадре.
Если теоретически основной поток будет планировать множество заданий, а остальные ядра CPU - выполнять их, мы сможем максимально увеличить объем параллельной работы на CPU и обеспечить масштабирование производительности по мере изменения аппаратного обеспечения. Если бы рабочих потоков было больше, чем ядер, операционная система могла бы контекстно переключить главный поток и переключиться на рабочий поток. Дополнительный рабочий поток может помочь быстрее освободить очередь заданий, но он, конечно, не позволит новым заданиям попасть в очередь, что в конечном итоге негативно скажется на производительности.
Существует несколько потенциальных проблем с описанным выше подходом к планировщику заданий, которые могут привести к перегрузке системы заданий. Давайте рассмотрим несколько примеров.
Главный поток планирует выполнение IJob (непараллельного задания) без зависимостей:
- Задание добавляется в очередь, и рабочий поток получает сигнал о пробуждении
- Рабочий поток просыпается
- Рабочий выполняет задание
- Рабочий проверяет, есть ли еще задания для выполнения
- Рабочий ложится спать, так как работы больше нет.
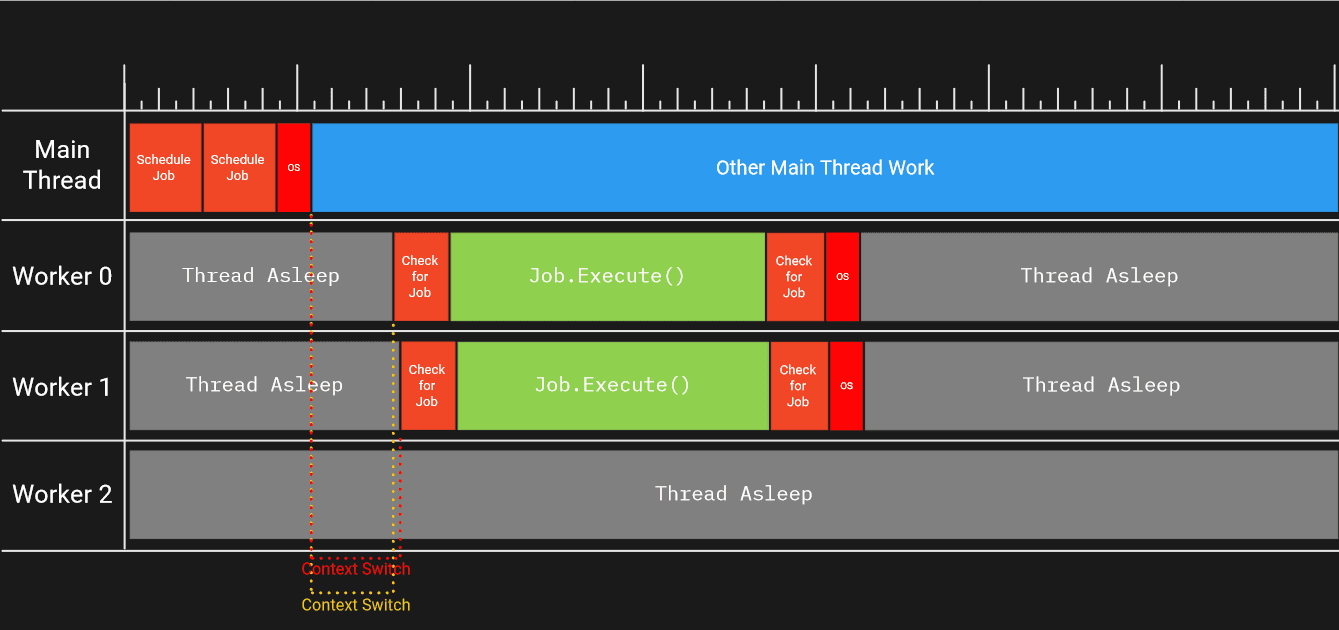
Как только главный поток подаст сигнал, используя семафор планировщика заданий, один из спящих рабочих потоков (не обязательно рабочий 0) проснется. Пробуждение и переключение контекста занимает некоторое время на рабочем ядре. Это происходит потому, что пока рабочий поток "спит", ядро процессора, на котором в итоге будет работать рабочий поток, скорее всего, было чем-то занято - возможно, выполнялся другой поток, порожденный игрой, или какой-то другой процесс на машине, которая использовала этот поток.
Чтобы потоки можно было приостановить и возобновить позже, необходимо сохранить состояние регистров потока, промыть конвейеры инструкций и восстановить состояние переключенного потока. Даже подача сигнала о потоке занимает время на ядре основного потока, поскольку уведомление о том, какой поток нужно разбудить, обрабатывается операционной системой. В конечном счете, все это означает, что на ядре основного и рабочего потоков выполняется работа, которая не входит в наши обязанности, и, следовательно, это накладные расходы, которые мы хотим сократить.

Скорость оповещения работников и время выполнения отдельного задания также могут оказывать влияние на систему. Например, если Вы возьмете приведенный выше пример, но запланируете два задания вместо одного:
- Задание добавляется в очередь, и рабочий поток получает сигнал о пробуждении
- Второе задание добавляется в очередь, и рабочему потоку подается сигнал на пробуждение
- В определенном порядке, но дважды:
- Рабочий поток просыпается
- Рабочий выполняет задание
- Рабочий проверяет, есть ли еще задания для выполнения
- Рабочий ложится спать, так как работы больше нет.
Если время подходит, у Вас есть два работника, которые работают параллельно над заданием.

Однако если одно из заданий слишком мало и/или требуется слишком много времени, чтобы подать сигнал и разбудить обоих работников, один работник может украсть всю работу в очереди, и в результате мы подадим сигнал работнику без всякой причины.

Такой тип "голодания" заданий и цикл "пробуждение <-> сон" может оказаться довольно дорогим и ограничить количество параллелизма, которое предлагает система заданий.
Вы можете подумать: "Разве накладные расходы, связанные с сигнализацией потоков и переключением контекста, не являются издержками бизнеса при работе с потоками в первую очередь?" Вы, конечно, не ошибаетесь. Но, хотя у Вас нет прямого контроля над тем, насколько дорого обходится подача сигнала или пробуждение потоков, Вы можете контролировать частоту выполнения этих операций.
Одно из решений, позволяющих избежать беспричинного пробуждения работников, заключается в том, чтобы будить их только тогда, когда Вы подозреваете, что в очереди есть много рабочих элементов, за которые работники должны взяться, чтобы оправдать затраты на пробуждение. Это можно сделать с помощью пакетной обработки: Вместо того, чтобы подавать сигнал рабочим, как только Вы запланировали задание, добавьте задание в список и в определенное время отправьте эту партию заданий в систему заданий, разбудив соответствующее количество рабочих в одно и то же время.
Все еще существует риск, что фактическое пробуждение занимает слишком много времени, пакетные задания очень малы, или количество заданий в пакете просто не очень велико. В общем, чем больше заданий Вы включаете в пакет, тем больше вероятность избежать накладных расходов, связанных с беспричинным пробуждением потоков. Unity поддерживает глобальную партию, которая смывается при каждом вызове JobHandle.Complete(). Поэтому, если Вам необходимо явно дождаться завершения задания, старайтесь делать это как можно позже и реже, и вообще предпочитайте планировать задания с зависимостями от заданий, чтобы лучше контролировать безопасный доступ к данным.
Вы также можете спросить себя: "Если подача сигналов потокам и ожидание их пробуждения/перехода в спящий режим - это чисто накладные расходы, почему бы нам не держать наши потоки бодрствующими все время в поисках работы?". Когда в очереди много заданий, это может происходить естественным образом. Если только операционная система не сочтет, что рабочий поток имеет более низкий приоритет по сравнению с другой работой (или он явно разделен по времени и должен быть заменен, чтобы дать другим потокам справедливую долю процессорного времени - это зависит от Вашей платформы), рабочие потоки будут радостно продолжать работать.
Однако, как и в случае с функциями PartialUpdateA и PartialUpdateB, которые мы рассматривали в первой части, не все задания можно распараллелить и освободить от зависимости от данных. Поэтому, как правило, Вам необходимо дождаться завершения некоторого подмножества заданий, прежде чем Вы сможете запустить другие. В результате мы видим узкие места в параллелизме графа заданий, когда количество выполняемых заданий (заданий без невыполненных зависимостей) становится меньше, чем количество рабочих потоков, в результате чего некоторым рабочим нечем заняться.
Если Вы никогда не разрешаете рабочим потокам спать, Вы можете столкнуться с рядом проблем. Когда рабочие потоки постоянно проверяют наличие новых заданий и не находят их, это считается "занятым ожиданием", или работой, которая является бесполезной и не продвигает программу. Если все ядра работают с максимальным параллелизмом, но при этом не продвигаются в игре, это сокращает срок службы батареи. Мало того, если у ядра нет времени для простоя, без достаточного охлаждения температура процессора будет расти, что приведет к даунлокингу - работе на пониженной скорости, чтобы избежать повреждений от перегрева. На самом деле, на мобильных платформах нередки случаи, когда целые ядра процессора временно отключаются, если они слишком сильно нагреваются. Для системы заданий очень важно уметь эффективно использовать ядра, поэтому необходимо соблюдать баланс между тем, чтобы работники спали, и тем, чтобы они постоянно искали новую работу, надеясь, что им повезет.
Еще одна область, которая может создавать накладные расходы в приведенном выше дизайне, - это очередь и стек без блокировки. Мы не будем вдаваться во все тонкости реализации этих структур данных, но одной общей чертой реализаций без блокировки является использование цикла сравнения и замены (CAS). Алгоритмы без блокировки не используют примитивы синхронизации блокировки для обеспечения безопасного доступа к общему состоянию, а вместо этого используют атомарные инструкции для аккуратного создания атомарных операций высшего порядка, таких как вставка элемента в очередь, безопасным для потока образом. Тем не менее, возможно, нелогично, что алгоритмы без блокировки все еще могут препятствовать продвижению одного потока до завершения другого. Они также могут оказывать вторичное влияние на конвейеры инструкций и памяти процессора, ухудшая масштабирование производительности. (Алгоритмы "без ожидания" позволяют всем потокам всегда выполнять работу, но на практике это не всегда обеспечивает наилучшую общую производительность).
Вот надуманный пример добавления числа в переменную-член m_Sum с помощью цикла CAS:
int Add(int val)
{
int newSum;
do
{
// Load the current value we want to update
var oldSum = m_Sum;
// Compute new value we want to store
newSum = oldSum + val;
// Attempt to write the new value. CompareExchange returns
// the value seen inside m_Sum when writing newSum to m_Sum.
// If newSum doesn't match oldSum, we will retry the loop
// since it means another thread wrote to the memory before us.
// If we wrote our value without this check, we might
// write an incorrect value
}while (oldSum != Interlocked.CompareExchange(ref m_Sum, newSum, oldSum));
return newSum ;
}Циклы CAS опираются на инструкцию сравнения и замены (здесь мы используем библиотеку C# Interlocked, абстрагируясь от особенностей платформы), которая "сравнивает два значения на предмет равенства и, если они равны, заменяет первое значение". Поскольку мы хотим, чтобы пользователи функции Add() не беспокоились о том, что эта функция может не сработать, используется цикл для повторной попытки, если она не сработает, потому что какой-то другой поток опередил нас в обновлении m_Sum.
Этот цикл повторных попыток, по сути, является циклом "занято-ожидание". Это имеет неприятные последствия для масштабирования производительности: Если несколько потоков одновременно входят в цикл CAS, только один из них одновременно выходит из него, сериализуя операции, выполняемые каждым потоком. К счастью, циклы CAS обычно выполняют заведомо небольшой объем работы, но это все равно может оказать большое негативное влияние на производительность. Поскольку больше ядер выполняют цикл параллельно, каждому потоку потребуется больше времени, чтобы завершить цикл, пока потоки находятся в состоянии конкуренции.
Кроме того, поскольку циклы CAS полагаются на атомарное чтение и запись в общую память, каждому потоку обычно требуется аннулировать свои строки кэша на каждой итерации, что приводит к дополнительным накладным расходам. Эти накладные расходы могут быть очень дорогими по сравнению с затратами на повторное выполнение вычислений внутри цикла CAS (в приведенном выше случае - повторное выполнение работы по сложению двух чисел). Поэтому, насколько высока стоимость, может быть неочевидно на первый взгляд.
В планировщике заданий 2017.3, когда рабочие потоки не выполняли задания, они искали работу в общем, свободном от блокировок стеке или очереди. Обе эти структуры данных использовали, по крайней мере, один цикл CAS для удаления работы из структуры данных. Таким образом, по мере того, как становилось больше ядер, стоимость выполнения работы из стека или очереди возрастала, если структуры данных были сопряжены. В частности, когда задания были небольшими, рабочие потоки пропорционально тратили больше времени на поиск работы в очереди или стеке.
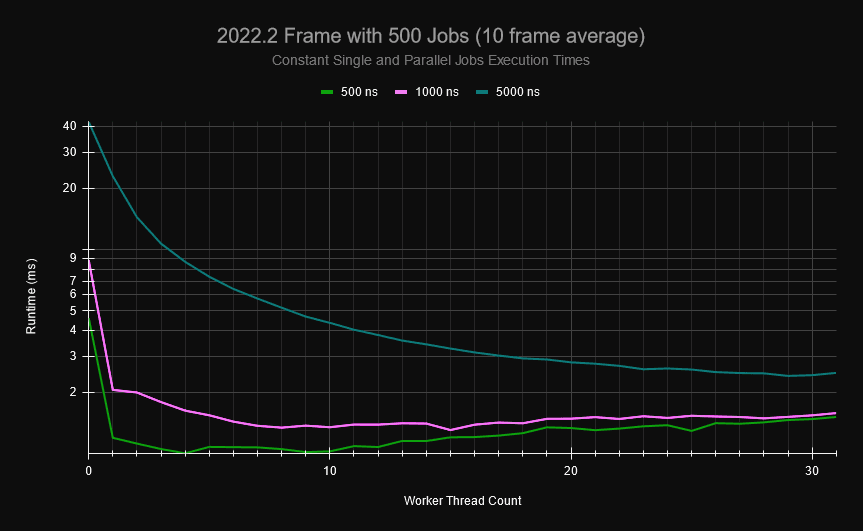
В небольшом проекте я сгенерировал детерминированные графики заданий, которые типичная игра может иметь для обновления кадров. График ниже состоит из одиночных и параллельных заданий (каждое распараллеливается на 1-100 параллельных заданий), где каждое задание может иметь 0-10 зависимых заданий, а главный поток периодически имеет явные точки синхронизации, где он должен дождаться завершения определенных заданий, прежде чем планировать другие. Если я создам 500 заданий в графике заданий и заставлю каждое из них выполнять фиксированное количество времени (каждая часть параллельного задания также занимает это время), Вы увидите, что по мере использования большего количества ядер накладные расходы в системе заданий возрастают.

Для заданий, занимающих 0,5 мкс, при наличии 20 рабочих кадр обновляется так же быстро, как если бы система заданий вообще не использовалась, и работает почти в два раза медленнее, если задействовать все ядра на моей машине. По умолчанию в Unity задействованы все ядра, поэтому при выполнении заданий 1 мкс производительность почти не повышается, несмотря на использование 31 рабочего потока. Это прямое следствие высокой нагрузки на очередь и стек без блокировки. К счастью, пользовательские задания обычно имеют больший размер и могут скрыть эти накладные расходы. Тем не менее, проблема масштабирования существует, а небольшие задания все еще достаточно распространены (особенно для параллельных заданий). Даже при использовании больших заданий, Ваши шаблоны планирования и время работы рабочих могут привести к большим накладным расходам из-за конкуренции с глобальным, свободным от блокировок стеком и очередью в планировщике заданий.
Теперь Вы видите, что есть несколько областей, которые наша команда должна была решить, чтобы уменьшить накладные расходы в системе заданий, как со стороны Unity, так и со стороны создателей игр:
- Избегайте застоев на главном потоке:
- Сигнал для пробуждения рабочих потоков стоит дорого - сведите его к минимуму.
- Изменение состояния в главном потоке, совместно используемом с рабочими потоками, скорее всего, приведет к аннулированию кэша и потенциальному ожиданию.
- Главный поток должен часто планировать задания - избегайте явного ожидания заданий до .Complete(). Предпочтите вместо этого отправлять задания с зависимостями.
- Избегайте застоев на рабочих потоках:
- Эффективность рабочих потоков напрямую влияет на параллелизм. По возможности избегайте соперничества за общие ресурсы.
- Ожидание рабочих потоков расходует заряд батареи и может привести к разгону из-за повышения температуры.
Хотя Unity не может изменить количество заданий, которые пользователи подают в своих играх, есть приличное количество проблем, которые наши инженеры могут решить с помощью другого подхода к планировщику заданий. В версии 2022.2 планировщик заданий, на высоком уровне, состоит из нескольких основных компонентов:
- Массив рабочих потоков
- Массив очередей для заданий
- Массив семафоров
Это очень похоже на предыдущий планировщик заданий. Однако главное отличие заключается в удалении общего состояния между главным и рабочими потоками. Вместо этого мы делаем очереди и семафоры (или futex на платформах, которые их поддерживают) локальными для каждого рабочего потока. Теперь, когда главный поток планирует задание, оно попадает в очередь главного потока, а не в глобальную очередь.
Аналогично, если рабочему потоку нужно запланировать задание (например, задание планирует задание в своем Execute), то это задание планируется в собственной очереди рабочего потока, а не в очереди главного потока. Это снижает трафик памяти, поскольку рабочие уменьшают частоту аннулирования строк кэша при записи в очередь. Поэтому рабочие не читают/пишут во все разные очереди с одинаковой частотой.
Рабочий цикл также изменился, теперь есть больше очередей, с которыми можно работать:
while(!scheduler.isQuitting)
{
// Take a job from our worker thread’s local queue
Job* pJob = m_worker_queue[m_workerId].dequeue();
// If our queue is empty try to steal work from someone
// else's queue to help them out.
if(pJob == nullptr) {
pJob = StealFromOtherQueues()
}
if(pJob) {
// If we found work, there may be more conditionally
// wake up other workers as necessary
WakeWorkers();
ExecuteJob(pJob);
}
// Conditionally go to sleep (perhaps we were told there is a
// parallel job we can help with)
else if(ShouldSleep())
{
// Put the thread to sleep until more jobs are scheduled
m_semaphores[m_workerId].Wait(1);
}
}Работники ищут работу в своей собственной очереди и заглядывают в очереди других работников только тогда, когда их очередь пуста. Поскольку работники предпочитают свои собственные очереди для снятия и постановки в очередь, количество конфликтов в одной очереди уменьшается.
Еще одно различие заключается в том, как потоки получают сигнал о пробуждении. Рабочие потоки теперь отвечают за пробуждение других рабочих потоков, а главный поток отвечает за то, чтобы хотя бы один рабочий поток был бодр, когда он планирует задание.
Такое изменение ответственности позволяет главному потоку избавиться от лишних накладных расходов, поскольку ему больше не нужно отвечать исключительно за пробуждение потоков при подаче параллельных заданий. Вместо этого система заданий отслеживает, нужно ли ей вообще будить работников. Главный поток может обеспечить постоянное бодрствование рабочего, чтобы он мог выполнять задания, а когда рабочий просыпается и обнаруживает задание в своей или чужой очереди, рабочий может подать сигнал другим рабочим, чтобы они проснулись и помогли освободить очередь, если это необходимо.

Разделение очередей для рабочих также предоставляет некоторую интересную свободу действий для настройки и оптимизации, которую наша команда продолжает дополнять и улучшать. В версии 2022.2 пользователи должны увидеть снижение затрат основного потока на пробуждение рабочих потоков и повышение производительности заданий на рабочих потоках, независимо от количества ядер на их платформе. Кроме того, хотя Unity не перенесла разделение очередей в 2021.3 LTS, мы вернули изменение дизайна, чтобы рабочие потоки отвечали за передачу сигналов друг другу, а не только главному потоку. Начиная с версии 2021.3.14f1, высокая нагрузка на систему заданий в главном потоке, связанная с передачей сигнала о глобальном семафоре, больше не должна быть проблемой.
Если у Вас есть вопросы или Вы хотите узнать больше, заходите к нам на форум C# Job System. Вы также можете связаться со мной напрямую через Unity Discord по имени пользователя @Antifreeze#2763. Обязательно следите за новыми техническими блогами от других разработчиков Unity в рамках продолжающейся серии Tech from the Trenches.