Mejora del escalado del rendimiento del sistema de trabajo en 2022.2 - parte 2: Sobrecarga


Las versiones 2022.2 y 2021.3.14f1 han mejorado el coste de programación y el escalado de rendimiento del sistema de trabajos de Unity. En la primera parte de este artículo en dos partes sobre las novedades de los sistemas de trabajos, ofrecí algunos antecedentes sobre la programación paralela y por qué podría utilizar un sistema de trabajos. Para la segunda parte, vamos a profundizar en lo que es la sobrecarga del sistema de trabajo y el enfoque de Unity para mitigarla.
Por sobrecarga se entiende todo el tiempo que la CPU pasa sin ejecutar su trabajo, desde el momento en que empieza a programarlo hasta el momento en que termina, desbloqueando cualquier trabajo en espera. A grandes rasgos, hay dos áreas en las que se emplea el tiempo:
1. La capa API de trabajo de C#
2. El programador de trabajos nativo (que gestiona y ejecuta todos los trabajos programados en C# e, internamente, en C++)
El propósito de la API de trabajos de C# es proporcionar un medio seguro para acceder al sistema nativo de trabajos. Aunque se trata de una capa de enlace para la transición de C# a C++, también es una capa que le permite evitar la programación accidental de trabajos en C# que se encontrarán con condiciones de carrera o bloqueos al acceder a NativeContainers desde dentro de un trabajo.
Además, esta separación proporciona una forma más rica de crear puestos de trabajo por sí mismos. En la capa C++, los trabajos son sólo un puntero a unos datos y un puntero a una función. Pero con la API de C# encima, puede personalizar los tipos de trabajos que programa, lo que permite un mejor control sobre cómo deben dividirse y paralelizarse los datos de los trabajos para adaptarse a los casos de uso específicos del usuario.
Al programar un trabajo, la capa de vinculación de trabajos de C# copia la estructura del trabajo en una asignación de memoria no gestionada. Esto permite desconectar el tiempo de vida de la estructura del trabajo C# del tiempo de vida del trabajo en el sistema de trabajo, ya que éste se ve afectado por las dependencias del trabajo y la carga global de la plataforma. A continuación, el sistema de trabajos realiza comprobaciones de seguridad de forma condicional en las construcciones del modo de juego Editor para garantizar que un trabajo se ejecuta de forma segura.
Estos pasos son importantes, pero no son gratuitos y contribuyen a la sobrecarga del sistema de trabajo. Dado que el tamaño de los trabajos puede variar, así como el número de NativeContainers y dependencias que pueda tener un trabajo, el coste de copiar los trabajos y validar su seguridad no es fijo. Por ello, es importante que Unity mantenga los costes reducidos y limitados a una complejidad computacional lineal.
En la versión 2021.2 Tech Stream, el equipo de ingeniería introdujo mejoras significativas en el sistema de seguridad de los trabajos al almacenar en caché el resultado de la comprobación de seguridad de las asas de trabajo individuales. Esto es especialmente importante, ya que el sistema de seguridad necesita comprender cadenas enteras de dependencias de trabajos y cada referencia de memoria nativa que contienen todos los trabajos para entender cuál puede ser la información de dependencia que falta y a qué trabajo debe añadirse una dependencia. Esto puede dar lugar a una cantidad no lineal de elementos sobre los que iterar al programar (es decir, para cada trabajo y sus dependencias, comprobar el acceso de lectura/escritura para cada NativeContainer al que se refiera el trabajo y cualquier trabajo que se refiera a los NativeContainers).
Sin embargo, Unity puede aprovechar el hecho de que los trabajos en C# sólo se programan de uno en uno, y comprobar la seguridad durante esta programación. En lugar de volver a analizar todos los trabajos en cada planificación, podemos determinar rápidamente si es necesario o no revalidar las cadenas de dependencia de los trabajos, lo que permite omitir grandes cantidades de trabajo. Incluso para las cadenas de dependencia de trabajos pequeños, esto reduce drásticamente el coste de los controles de seguridad en el trabajo. Lo ideal sería que no hubiera ninguna razón para desactivar las comprobaciones de seguridad en el trabajo durante el desarrollo (las comprobaciones de seguridad en el trabajo no están activadas en las construcciones de jugador/envío).
Siempre que se programa la ejecución de un trabajo C# o C++, éste pasa por el programador de trabajos. El papel del programador es:
- Seguimiento de los trabajos a través de los gestores de trabajos
- Gestione las dependencias de los trabajos, asegurándose de que los trabajos sólo comienzan a ejecutarse una vez que se han completado todas las dependencias
- Gestionar los "hilos trabajadores", que son los hilos que ejecutarán los trabajos
- Garantizar que los trabajos se ejecutan lo más rápidamente posible, lo que suele significar que deben ejecutarse en paralelo cuando las dependencias lo permiten.
Además, mientras que la API de trabajos de C# sólo permite programar trabajos desde el subproceso principal, el programador de trabajos necesita admitir varios subprocesos que programen trabajos al mismo tiempo. Esto se debe a que el motor subyacente de Unity utiliza muchos hilos que programan trabajos e incluso pueden programar trabajos desde dentro de trabajos. Esta funcionalidad tiene pros y contras, pero requiere mucho más escrutinio para su corrección y añade el requisito de que el programador de trabajos debe ser seguro para los hilos.
En la versión 2017.3, el aspecto básico del programador de trabajos era:
- Cola de trabajos
- Pila de trabajos
- Semáforo
- Matriz de hilos trabajadores
El uso típico sigue este patrón: A medida que se programan los trabajos, se ponen en cola en una cola global, sin bloqueos, de múltiples productores y múltiples consumidores, que representa los trabajos que están listos para ser manejados por un hilo trabajador. A continuación, el hilo principal envía una señal mediante un semáforo para despertar a los hilos trabajadores.
El número de trabajadores a los que se les dice que despierten depende del tipo de trabajo que se esté programando - los trabajos individuales como IJob sólo despiertan a un único trabajador, ya que ese tipo de trabajo no reparte el trabajo entre varios hilos de trabajadores. Los trabajos IJobParallelFor, sin embargo, representan múltiples piezas de trabajo que pueden ejecutarse en paralelo. Mientras se programa un trabajo, puede haber muchas piezas para que algunos o todos los trabajadores ayuden al mismo tiempo. Así, el programador calcula cuántos trabajadores pueden ayudar potencialmente y despierta a ese número.
Una vez despiertos, los hilos de trabajo son donde tiene lugar el trabajo real. En 2017.3, eran responsables de retirar un trabajo de la cola de trabajos, asegurándose de que todas las dependencias relevantes del trabajo estaban completas. Si aún no se hubieran completado, el trabajo y las dependencias incompletas se añadirían a una pila sin bloqueos como forma de saltar al frente de la cola para intentar ejecutarse de nuevo. Los subprocesos de trabajo hacen esto en un bucle hasta que el motor señala que quiere apagarse o no hay más trabajos en la pila y la cola. En ese momento, los hilos trabajadores pasan a dormir esperando una señal del semáforo del hilo principal.
while(!scheduler.isQuitting)
{
// Usually empty unless we need to prioritize a dependency
// to unblock a job we got from the queue. Alternatively
// pieces of work from a IJobParallelFor job can end up here to let
// many workers help finish IJobParallelFor work quickly
Job* pJob = m_stack.pop();
if(!pJob)
Job* pJob = m_queue.dequeue();
if(pJob) {
// ExecuteJob if all dependencies are complete, otherwise
// push this job and the dependencies to the stack and try again
if(EnsureDependenciesAreCompleteOtherwiseAddToStack(pJob))
ExecuteJob(pJob);
}
else
{
// Put the thread to sleep until more jobs are scheduled
m_semaphore.Wait(1);
}
}El programador de trabajos crea tantos hilos de trabajo como núcleos virtuales haya en la CPU, menos uno por defecto. La intención aquí es que cada hilo trabajador se ejecute en su propio núcleo de CPU, dejando un núcleo de CPU libre para que el hilo principal siga funcionando. En la práctica, en plataformas en las que un núcleo no está reservado para procesos ajenos al juego, puede ser mejor reducir la cantidad de hilos de trabajo para que el cálculo realizado por los hilos del sistema operativo o del controlador no compita con los hilos de trabajo principales o de trabajo del juego.
Dado que el hilo principal es el lugar principal desde el que se programan los trabajos, es muy importante no retrasar el hilo principal. Hacerlo afecta directamente a cuántos trabajos entran en el sistema de trabajos y, por tanto, a cuánto paralelismo puede producirse dentro de un marco.
Con el hilo principal programando teóricamente muchos trabajos y el resto de los núcleos de la CPU ejecutando esos trabajos, deberíamos ser capaces de maximizar la cantidad de trabajo paralelo que se puede realizar en la CPU y permitir que el rendimiento escale a medida que cambia el hardware. Si tuviéramos más hilos trabajadores que núcleos, el sistema operativo podría cambiar de contexto el hilo principal y pasar a un hilo trabajador. Tener un hilo de trabajo adicional en ejecución podría ayudar a vaciar su cola de trabajos más rápidamente, pero sin duda impediría que nuevos trabajos entraran en la cola, lo que en última instancia tiene un mayor efecto negativo en el rendimiento.
Hay un par de problemas potenciales con el enfoque anterior del programador de trabajos que pueden provocar una sobrecarga del sistema de trabajos. Veamos algunos ejemplos.
El hilo principal programa un IJob (trabajo no paralelo) sin dependencias:
- Se añade un trabajo a la cola y se indica a un hilo trabajador que se despierte
- Un hilo trabajador se despierta
- El trabajador ejecuta el trabajo
- El trabajador comprueba si hay más trabajos por ejecutar
- El trabajador se va a dormir ya que no hay más trabajo
Una vez que el hilo principal emite una señal utilizando el semáforo del programador de trabajos, uno de los hilos trabajadores durmientes (no necesariamente el trabajador 0) se despertará. Despertar y cambiar de contexto lleva algún tiempo en el núcleo trabajador. Esto se debe a que, mientras el hilo trabajador está dormido, el núcleo de la CPU en el que el hilo trabajador terminará ejecutándose probablemente estaba haciendo algo - tal vez ejecutando otro hilo generado por el juego o algún otro proceso en la máquina que estaba utilizando el hilo.
Para que los hilos puedan pausarse y reanudarse más tarde, es necesario guardar el estado de los registros de un hilo, purgar las canalizaciones de instrucciones y restaurar el estado del hilo conmutado. Incluso la señalización del hilo lleva tiempo en el núcleo del hilo principal, ya que la notificación de qué hilo despertar es gestionada por el sistema operativo. En última instancia, todo esto significa que en el núcleo del hilo principal y en el núcleo del hilo trabajador se está realizando un trabajo que no nos corresponde y que, por tanto, es una sobrecarga que queremos reducir.

La rapidez con la que se puede avisar a los trabajadores y el tiempo que tarda en ejecutarse un trabajo individual también pueden influir en el sistema. Por ejemplo, si toma el caso de uso anterior pero programa dos trabajos en lugar de uno:
- Se añade un trabajo a la cola y se indica a un hilo trabajador que se despierte
- El segundo trabajo se añade a la cola, y se indica a un hilo trabajador que despierte
- En cierto orden, pero dos veces:
- Un hilo trabajador se despierta
- Un trabajador ejecuta el trabajo
- El trabajador comprueba si hay más trabajos por ejecutar
- El trabajador se va a dormir ya que no hay más trabajo
Si la sincronización funciona, tendrá a dos trabajadores trabajando en paralelo en la obra.

Sin embargo, si uno de los trabajos es demasiado pequeño y/o se tarda demasiado en señalizar y despertar a ambos trabajadores, un trabajador podría robar todo el trabajo de la cola y, como resultado, habremos señalizado a un trabajador sin motivo.

Este tipo de inanición de trabajos y ciclo despertar <-> dormir puede acabar siendo bastante caro y limitar la cantidad de paralelismo que ofrece el sistema de trabajos.
Puede que esté pensando: "¿No es la sobrecarga de los hilos de señalización y el cambio de contexto un coste de hacer negocios cuando se trata de hilos en primer lugar?". Desde luego, no se equivoca. Pero, aunque no tenga un control directo sobre lo costoso que resulta señalar o despertar hilos, sí puede controlar la frecuencia con la que se producen esas operaciones.
Una solución para evitar despertar a los trabajadores sin motivo es despertarlos sólo cuando sospeche que hay muchos elementos de trabajo en la cola para que los trabajadores los tomen justificando el coste del despertar. Esto puede hacerse por lotes: En lugar de avisar a los trabajadores tan pronto como programe un trabajo, añada el trabajo a una lista y, a horas específicas, introduzca ese lote de trabajos en el sistema de trabajos, despertando al mismo tiempo a una cantidad adecuada de trabajadores.
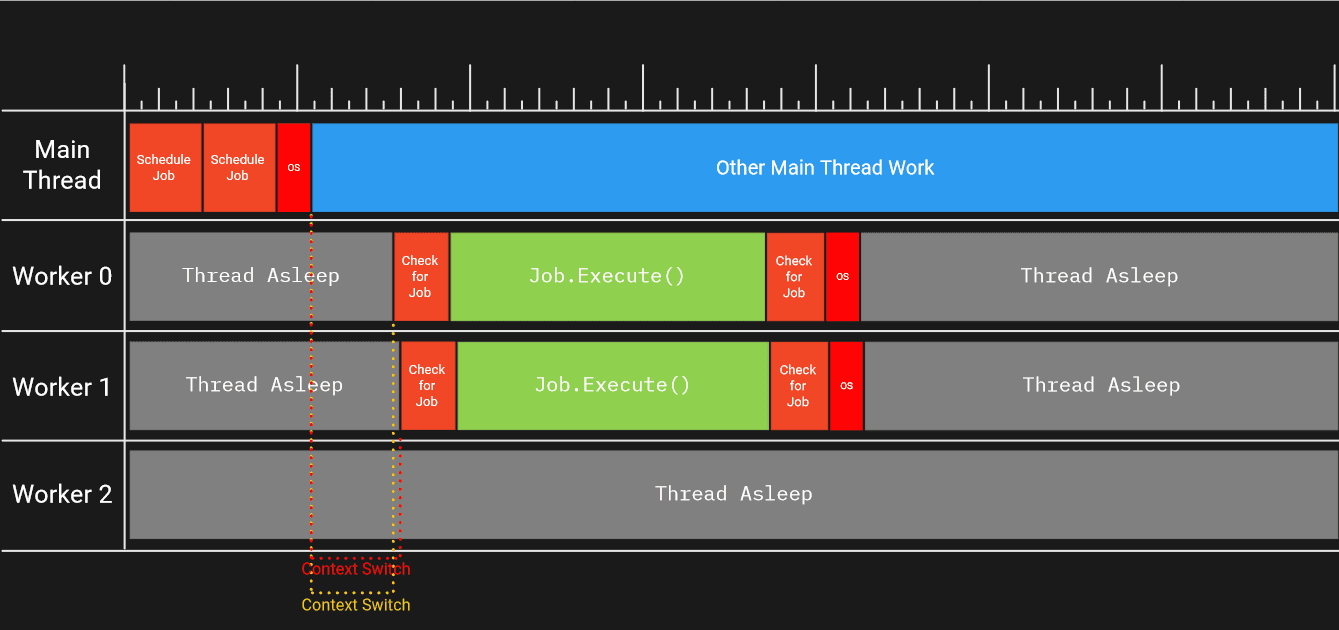
Sigue existiendo el riesgo de que el despertar real tarde demasiado tiempo, que los trabajos por lotes sean muy pequeños o que el número de trabajos en un lote no sea muy elevado. En general, cuantos más trabajos incluya en el lote, más posibilidades tendrá de evitar la sobrecarga que supone despertar hilos sin motivo. Unity mantiene un lote global que se vacía cada vez que se llama a JobHandle.Complete(). Por lo tanto, si necesita esperar explícitamente a que finalice un trabajo, intente hacerlo lo más tarde y con la menor frecuencia posible, y en general prefiera programar los trabajos con dependencias de trabajo para controlar mejor el acceso seguro a los datos.
Puede que también se esté preguntando: "Si señalizar hilos y esperar a que se despierten/se duerman es pura sobrecarga, ¿por qué no mantenemos nuestros hilos despiertos todo el tiempo buscando trabajo?". Cuando hay muchos trabajos en la cola, esto puede ocurrir de forma natural. A menos que el sistema operativo considere que el hilo trabajador es menos prioritario que algún otro trabajo (o que esté explícitamente rebanado en el tiempo y deba ser intercambiado para dar a otros hilos su parte justa de tiempo de CPU - depende de su plataforma), los hilos trabajadores seguirán trabajando alegremente.
Sin embargo, al igual que con las funciones PartialUpdateA y PartialUpdateB que vimos en la primera parte, no todos los trabajos son paralelizables y están libres de dependencias de datos. Por ello, normalmente tendrá que esperar a que se complete algún subconjunto de trabajos antes de poder ejecutar otros. Como resultado, vemos cuellos de botella en el paralelismo de un grafo de trabajos cuando hay menos trabajos ejecutables (trabajos sin dependencias pendientes) que hilos de trabajadores, lo que provoca que algunos trabajadores no tengan nada productivo que hacer.
Si no deja dormir nunca los hilos trabajadores, puede encontrarse con un puñado de problemas. Cuando los subprocesos de trabajadores comprueban constantemente si hay nuevos trabajos y no encuentran ninguno, esto se considera "espera ocupada", o trabajo que es un desperdicio y no hace progresar el programa. Mantener todos los núcleos funcionando con el máximo paralelismo, pero sin que progrese el juego, es un drenaje de la vida de la batería. No sólo eso, si un núcleo no tiene tiempo de inactividad, sin una refrigeración suficiente la temperatura de la CPU aumentará, lo que conducirá al downclocking , es decir, a funcionar más despacio para evitar daños por sobrecalentamiento. De hecho, en las plataformas móviles, no es raro que núcleos enteros de la CPU se desactiven temporalmente si se calientan demasiado. Para un sistema de trabajo, poder utilizar los núcleos de forma eficiente es muy importante, por lo que existe un equilibrio entre dormir a los trabajadores y tenerlos constantemente en bucle buscando nuevos trabajos, con la esperanza de que tengan suerte.
Otra área que puede generar sobrecarga en el diseño anterior es la cola y la pila sin bloqueos. No entraremos en todos los matices de la implementación de estas estructuras de datos, pero un rasgo común de las implementaciones sin bloqueo es el uso de un bucle de comparación e intercambio (CAS). Los algoritmos sin bloqueo no utilizan primitivas de sincronización de bloqueo para proporcionar un acceso seguro al estado compartido, sino que utilizan instrucciones atómicas para crear cuidadosamente operaciones atómicas de orden superior, como insertar un elemento en una cola de forma segura para los hilos. Sin embargo, quizá de forma poco intuitiva, los algoritmos sin bloqueo pueden seguir impidiendo que un hilo avance hasta que otro haya terminado. También pueden tener efectos secundarios en los pipelines de instrucción y memoria de la CPU, perjudicando el escalado del rendimiento. (Los algoritmos "sin esperas" permitirían que todos los hilos progresaran siempre, pero eso no siempre proporciona el mejor rendimiento global en la práctica).
He aquí un ejemplo artificioso de adición de un número a una variable miembro, m_Suma, con un bucle CAS:
int Add(int val)
{
int newSum;
do
{
// Load the current value we want to update
var oldSum = m_Sum;
// Compute new value we want to store
newSum = oldSum + val;
// Attempt to write the new value. CompareExchange returns
// the value seen inside m_Sum when writing newSum to m_Sum.
// If newSum doesn't match oldSum, we will retry the loop
// since it means another thread wrote to the memory before us.
// If we wrote our value without this check, we might
// write an incorrect value
}while (oldSum != Interlocked.CompareExchange(ref m_Sum, newSum, oldSum));
return newSum ;
}Los bucles CAS se basan en la instrucción compare-and-swap (aquí utilizamos la biblioteca C# Interlocked que abstrae los detalles de la plataforma), que "compara dos valores para comprobar su igualdad y, si son iguales, sustituye el primer valor". Como queremos que los usuarios de la función Add() no se preocupen de que esta función pueda fallar, se utiliza un bucle para volver a intentarlo si falla porque algún otro hilo se nos ha adelantado en la actualización de m_Sum.
Este bucle de reintento es, en esencia, un bucle de "ocupado-espera". Esto tiene una implicación desagradable para el escalado del rendimiento: Si varios hilos entran en el bucle CAS al mismo tiempo, sólo saldrá uno a la vez, serializando las operaciones que cada hilo está realizando. Afortunadamente, los bucles CAS suelen realizar una cantidad de trabajo intencionadamente pequeña, pero aún así pueden tener un gran impacto negativo en el rendimiento. A medida que más núcleos ejecuten el bucle en paralelo, cada hilo tardará más en completar el bucle mientras los hilos estén en contención.
Además, como los bucles CAS se basan en lecturas y escrituras atómicas en la memoria compartida, cada hilo requiere generalmente que sus líneas de caché se invaliden en cada iteración, lo que provoca una sobrecarga adicional. Esta sobrecarga puede ser muy cara en comparación con el coste de rehacer los cálculos dentro del bucle CAS (en el caso anterior, rehacer el trabajo de sumar dos números). Por lo tanto, lo elevado del coste puede no ser evidente a primera vista.
Con el programador de trabajos 2017.3, cuando los subprocesos de los trabajadores no estaban ejecutando trabajos, buscaban trabajo en una pila o cola compartida y sin bloqueos. Ambas estructuras de datos utilizaban al menos un bucle CAS para eliminar trabajo de la estructura de datos. Así, a medida que se disponía de más núcleos, el coste de tomar trabajo de la pila o de la cola aumentaba cuando las estructuras de datos tenían contención. En particular, cuando los trabajos eran pequeños, los subprocesos de los trabajadores dedicaban proporcionalmente más tiempo a buscar trabajo en la cola o la pila.
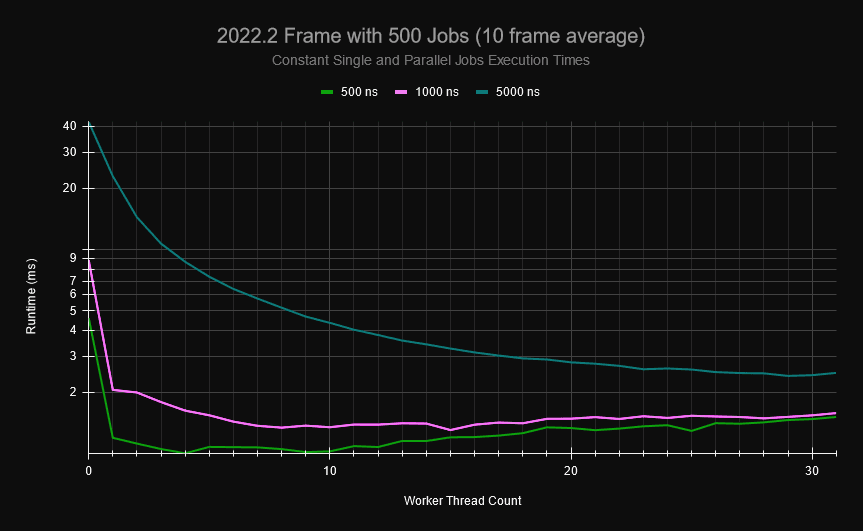
En un pequeño proyecto, he generado gráficos de trabajo deterministas que un juego típico puede tener para su actualización de fotogramas. El gráfico siguiente se compone de trabajos individuales y trabajos paralelos (cada uno de los cuales se paraleliza en 1-100 trabajos paralelos), donde cada trabajo puede tener de 0 a 10 dependencias de trabajos y el hilo principal tiene ocasionalmente puntos de sincronización explícitos en los que debe esperar a que terminen ciertos trabajos antes de programar más. Si genero 500 trabajos en el gráfico de trabajos, y hago que cada uno tarde una cantidad fija de tiempo en ejecutarse (cada porción de un trabajo paralelo también tarda este tiempo), puede ver que, a medida que se utilizan más núcleos, aumenta la sobrecarga en el sistema de trabajos.

Para los trabajos que tardan 0,5μs, una vez que hay 20 trabajadores, el cuadro se actualiza tan rápido como si no utilizara el sistema de trabajos en absoluto, y funciona casi el doble de lento cuando se utilizan todos los núcleos de mi máquina. Por defecto, en Unity se utilizan todos los núcleos, por lo que con trabajos de 1μs, casi no hay mejora en el rendimiento a pesar de utilizar 31 hilos de trabajador. Esto es un resultado directo de la alta contención en la cola libre de bloqueos y en la pila. Por suerte, los trabajos de usuario suelen ser de mayor tamaño y pueden ocultar esta sobrecarga. Sin embargo, el problema del escalado está ahí, y los trabajos pequeños siguen siendo bastante comunes (especialmente para los trabajos paralelos). Incluso cuando se utilizan trabajos de mayor tamaño, sus patrones de programación y los tiempos de los trabajadores pueden causar grandes cantidades de sobrecarga debido a la contención con la pila y la cola globales y sin bloqueos del programador de trabajos.
A estas alturas, puede ver que hay algunas áreas que nuestro equipo necesitaba abordar para reducir la sobrecarga en el sistema de trabajos, tanto por parte de Unity como por parte del creador del juego:
- Evitar atascos en el hilo principal:
- La señalización para despertar hilos trabajadores es costosa - manténgala al mínimo.
- Modificar el estado en el subproceso principal compartido con los subprocesos de los trabajadores es probable que provoque invalidaciones de la caché y una posible espera ocupada.
- El hilo principal debe programar los trabajos con frecuencia - evite esperar explícitamente a que los trabajos .Completen(). Prefiera enviar trabajos con dependencias en su lugar.
- Evitar las paradas en los subprocesos de los trabajadores:
- La eficiencia de los hilos de trabajo repercute directamente en el paralelismo. Evite, en la medida de lo posible, competir por los recursos compartidos.
- Las esperas ocupadas en los subprocesos de los trabajadores agotarán la vida de la batería y pueden provocar un downclocking debido al aumento de la temperatura.
Aunque Unity no puede cambiar el número de trabajos que los usuarios envían en sus juegos, hay un número decente de problemas que nuestros ingenieros pueden abordar con un enfoque diferente del programador de trabajos. En la versión 2022.2, el programador de trabajos, a alto nivel, se divide en unos pocos componentes básicos:
- Matriz de hilos trabajadores
- Conjunto de colas de trabajos
- Matriz de semáforos
Esto es muy similar al programador de trabajos anterior. Sin embargo, la principal diferencia es la eliminación del estado compartido entre el hilo principal y los hilos trabajadores. En su lugar, hacemos que las colas y los semáforos (o futex en las plataformas que lo soportan) sean locales para cada hilo trabajador. Ahora, cuando el subproceso principal programa un trabajo, éste se encola en la cola del subproceso principal en lugar de en una cola global.
Del mismo modo, si un hilo trabajador necesita programar un trabajo (por ejemplo, un trabajo programa un trabajo en su Ejecutar), ese trabajo se programa en la cola propia del trabajador en lugar de en la cola del hilo principal. Esto reduce el tráfico de memoria, ya que los trabajadores reducen la frecuencia de invalidación de las líneas de caché cuando escriben en una cola. Por ello, los trabajadores no leen/escriben en todas las colas diferentes con la misma frecuencia.
El bucle de trabajador también ha cambiado, ahora que hay más colas con las que trabajar:
while(!scheduler.isQuitting)
{
// Take a job from our worker thread’s local queue
Job* pJob = m_worker_queue[m_workerId].dequeue();
// If our queue is empty try to steal work from someone
// else's queue to help them out.
if(pJob == nullptr) {
pJob = StealFromOtherQueues()
}
if(pJob) {
// If we found work, there may be more conditionally
// wake up other workers as necessary
WakeWorkers();
ExecuteJob(pJob);
}
// Conditionally go to sleep (perhaps we were told there is a
// parallel job we can help with)
else if(ShouldSleep())
{
// Put the thread to sleep until more jobs are scheduled
m_semaphores[m_workerId].Wait(1);
}
}Los trabajadores buscan trabajo en su propia cola y sólo miran las colas de los demás trabajadores cuando la suya está vacía. Dado que los trabajadores prefieren sus propias colas para retirar y poner en cola el trabajo, se reduce la cantidad de contención en cualquier cola.
Otra diferencia es cómo se señaliza a los hilos que se despierten. Los hilos trabajadores son ahora responsables de despertar a otros hilos trabajadores, y el hilo principal es responsable de garantizar que al menos un hilo trabajador esté despierto cuando programe un trabajo.
Este cambio en la responsabilidad permite al hilo principal eliminar una sobrecarga excesiva, puesto que ya no necesita ser el único responsable de despertar hilos cuando se envían trabajos paralelos. En su lugar, el sistema de trabajo realiza un seguimiento para saber si necesita despertar a algún trabajador. El hilo principal puede asegurarse de que un trabajador esté siempre despierto para avanzar en los trabajos y cuando los trabajadores se despiertan y encuentran un trabajo en su propia cola o en la de otro, los trabajadores pueden indicar a otros trabajadores que se despierten y ayuden a vaciar la cola si es necesario.

La separación de colas para los trabajadores también proporciona un margen interesante para la configuración y las optimizaciones, que nuestro equipo sigue ampliando y mejorando. En 2022.2, los usuarios deberían ver reducido el coste del hilo principal para despertar los hilos de los trabajadores y mejorado el rendimiento de los trabajos en los hilos de los trabajadores, independientemente del número de núcleos que tenga su plataforma. Además, aunque Unity no ha retroportado la separación de colas a 2021.3 LTS, hemos recuperado el cambio de diseño para que sean los hilos trabajadores los responsables de señalizarse entre sí en lugar del hilo principal exclusivamente. La elevada sobrecarga del sistema de trabajo en el hilo principal debido a la señalización del semáforo global ya no debería ser un problema a partir de 2021.3.14f1.
Si tiene preguntas o quiere saber más, visítenos en el foro del sistema de empleo C#. También puede conectar conmigo directamente a través del Discord de Unity en el nombre de usuario @Antifreeze#2763. Asegúrese de estar atento a los nuevos blogs técnicos de otros desarrolladores de Unity como parte de la serie en curso Tech from the Trenches.