Using rich LLM integrations to power relevance and reliability with Muse Chat


Unity Muse helps you explore, ideate, and iterate on real-time 3D experiences by empowering you with AI capabilities. Muse Chat is one of several tools that you can use to accelerate creation. Bringing Unity knowledge and Editor awareness to your fingertips, Muse Chat can be your assistant by providing helpful information including debugging advice, using code generation for a first draft, and more, all within the context of the Unity Editor and your project.
To show you how exactly Muse Chat is designed to provide helpful solutions, we’re going to give you a peek under the hood of how we structure the plan to generate a response. We’ll also give you a preview of our current explorations and upcoming developments of the LLM pipeline.
Muse Chat is built as a pipeline consisting of several different systems and Large Language Model (LLM) integrations for query planning and arbitration of different pieces of information. For each incoming request, Chat derives a plan of action to outline the format of the upcoming response based on the Editor selection or information you provided and the problem you are trying to solve.
“I built and coded everything myself using Muse as my personal assistant. Of course, I had the support of my colleagues, but I don’t think I could have achieved this result in such a short time if I didn’t have Muse by my side.”
– Jéssica Souza, cocreator of Space Purr-suit
When assembling a reliable response, there are two challenges. One is retrieving relevant information to build the response, and the other is making sure that the information is usefully embedded in the response, based on the conversation’s context and history.
Muse Chat’s knowledge is assembled to address both of these challenges, with more than 800,000 chunks of information such as sections of documentation or code snippets. The chunks are processed and enriched with references to surrounding information, so that each one provides a useful and self-standing unit of information. They are cataloged both by their content and their unique context, as traced through the documentation. It provides transparency and interpretability of the system, and it enables effective retrieval of compatible information. See the diagram and description below to learn how the rest of our current pipeline is structured.
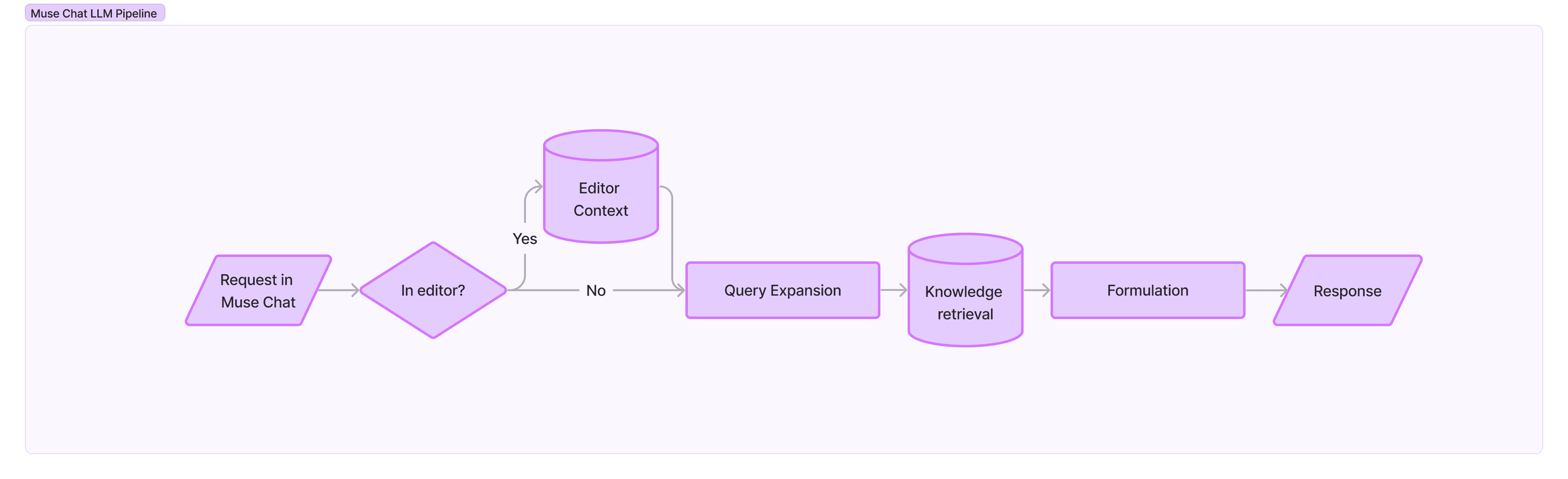
- REQUEST: Your request comes in.
- EDITOR CONTEXT: If you are in the Editor, the relevant context is dynamically extracted from the Editor, along with the request to give Muse the proper information.
- QUERY EXPANSION: The initial planning system performs query expansion, which is intended to derive precise plans. We instruct an LLM to give its best attempt at replicating the knowledge catalog format and recreate the ideal structure of a chunk for each step. This approach allows the system to compute an embedding that captures the desired context, contents, and use case of the chunk we’re looking for. Each of these plan steps are used for fine-grained semantic retrieval.
- KNOWLEDGE RETRIEVAL: To find the relevant information, we use symmetrical semantic retrieval and metadata filtering to retrieve the chunks in our knowledge catalog that most resemble the ideal estimated chunk, identified in the Query Expansion stage.
- FORMULATION: To generate the final response, we use another LLM to compose a response, based on the detailed outline containing both the filtered original plan steps and the sources needed to convey the relevant underlying information.
- RESPONSE: Muse Chat responds with an answer.
To drill into the work behind making Muse Chat available in the Editor, we introduced the second step to the pipeline, Editor context extraction. Adding this to the very beginning of the pipeline, we analyze the query to identify what to extract from the Editor, and parse this to inform Muse on next steps. Based on your feedback, we began with project setup, project settings, GameObjects/Prefabs, and console access.
Now, if you were to experience a console error with warnings or messages, simply click the relevant row(s) in the console to add the error as part of your selection. In the example below, we triggered an error for a missing curly bracket in a script.

Consider a simple example of answering “How can I create a scriptable feature and add it to the Universal Renderer?” in a new conversation in the Editor. This will be converted into plan steps:
- REQUEST: “How can I create a scriptable feature appropriate for my render pipeline?”
- EDITOR CONTEXT: Muse identifies which render pipeline is used, the version of Unity that’s running, which project settings are relevant to the question. It then extracts dynamic context, along with any Editor selection you might have.
- QUERY EXPANSION: LLM generates a plan with the following plan steps:
Introduce the concept and purpose of scriptable features for URP.
Explain the steps to create a scriptable feature in URP.
Provide an example showing how to add the scriptable feature to the Universal Renderer.
- KNOWLEDGE RETRIEVAL: For this example, the request is fulfilled by following the steps to retrieve information from the embedding.
- FORMULATION: LLM mediates the final response.
- RESPONSE: You get an answer, as seen below, along with a code snippet.
In the above example involving URP, the final response plan is composed of an introduction built on top of the “What is a Scriptable Renderer Feature” section on in the URP documentation, the step-by-step directions in “Create a scriptable Renderer Feature and add it to the Universal Renderer,” and the directions in the subsection on finally adding the custom Renderer Feature to a Universal Renderer asset.
This way, we are able to efficiently swap generic information coming from the LLM’s base knowledge with specific Unity knowledge from first-party sources related to recommended approaches or implementation details. While the occurrence of sometimes inaccurate information is somewhat inevitable when using LLMs, our system is built to minimize their frequency by relying on trusted Unity knowledge.
We are working on developing a wide ecosystem consisting of task specific models. As we expand our interoperability with the Editor, we want to enable an accelerated workflow to better serve your needs. We believe that the key to do so is embracing and fostering a culture where we can quickly adapt to research and industry developments for rapid experimentation.
Muse Chat serves as a companion for AI-assisted creation, right in the Editor. We are currently working to extend what you can select as part of your context in the Editor, including the full hierarchy and project window, as well as including the associated code for a GameObject. Furthermore, we’re investing in widespread system improvements, improving on our performance benchmarks on Unity knowledge and code generation, and preparing for a future with agent behavior enabled, so that Muse can perform actions on your behalf in the Editor.
At GDC, we showcased how you could use all five Muse capabilities together to customize a game loop in the garden scene of our URP sample project. Check out our session “Unity Muse: Accelerating prototyping in the Unity Editor with AI”to learn how you can use all of Muse’s abilities to quickly customize a project scene and gameplay. This interoperability between Muse features is only going to increase as we roll out new improvements to Muse Chat.
We’ve updated the Muse onboarding experience to make it easier to start a free trial of Muse and add the Muse packages to your projects. Visit the new Muse Explore page to get started, and let us know what you think of the newest capabilities and improvements in Discussions.