Uso de integraciones LLM enriquecidas para potenciar la relevancia y la fiabilidad con Muse Chat


Unity Muse le ayuda a explorar, idear e iterar en experiencias 3D en tiempo real, dotándole de capacidades de IA. Muse Chat es una de las varias herramientas que puede utilizar para acelerar la creación. Llevando el conocimiento de Unity y del Editor a la punta de tus dedos, Muse Chat puede ser tu asistente proporcionando información útil incluyendo consejos de depuración, usando la generación de código para un primer borrador, y más, todo dentro del contexto del Editor de Unity y tu proyecto.
Para mostrarle cómo está diseñado exactamente Muse Chat para proporcionar soluciones útiles, vamos a darle un vistazo bajo el capó de cómo estructuramos el plan para generar una respuesta. También le ofreceremos un avance de nuestras exploraciones actuales y de los próximos desarrollos del LLM.
Muse Chat se construye como un pipeline formado por varios sistemas diferentes e integraciones de Large Language Model (LLM) para la planificación de consultas y el arbitraje de diferentes piezas de información. Para cada solicitud entrante, Chat elabora un plan de acción para esbozar el formato de la próxima respuesta en función de la selección del editor o de la información que haya proporcionado y del problema que intente resolver.
"He creado y programado todo yo mismo utilizando Muse como asistente personal. Por supuesto, conté con el apoyo de mis colegas, pero no creo que hubiera conseguido este resultado en tan poco tiempo si no hubiera tenido a Muse a mi lado".
- Jéssica Souza, cocreadora de Space Purr-suit
A la hora de reunir una respuesta fiable, se plantean dos retos. Por un lado, hay que recuperar la información pertinente para elaborar la respuesta y, por otro, hay que asegurarse de que la información se incluya de forma útil en la respuesta, basándose en el contexto y el historial de la conversación.
Los conocimientos de Muse Chat se reúnen para hacer frente a estos dos retos, con más de 800.000 fragmentos de información, como secciones de documentación o fragmentos de código. Los trozos se procesan y enriquecen con referencias a la información circundante, de modo que cada uno constituye una unidad de información útil y autónoma. Se catalogan tanto por su contenido como por su contexto único, rastreado a través de la documentación. Aporta transparencia e interpretabilidad al sistema, y permite una recuperación eficaz de la información compatible. Consulte el diagrama y la descripción que figuran a continuación para saber cómo está estructurado el resto de nuestro canal actual.
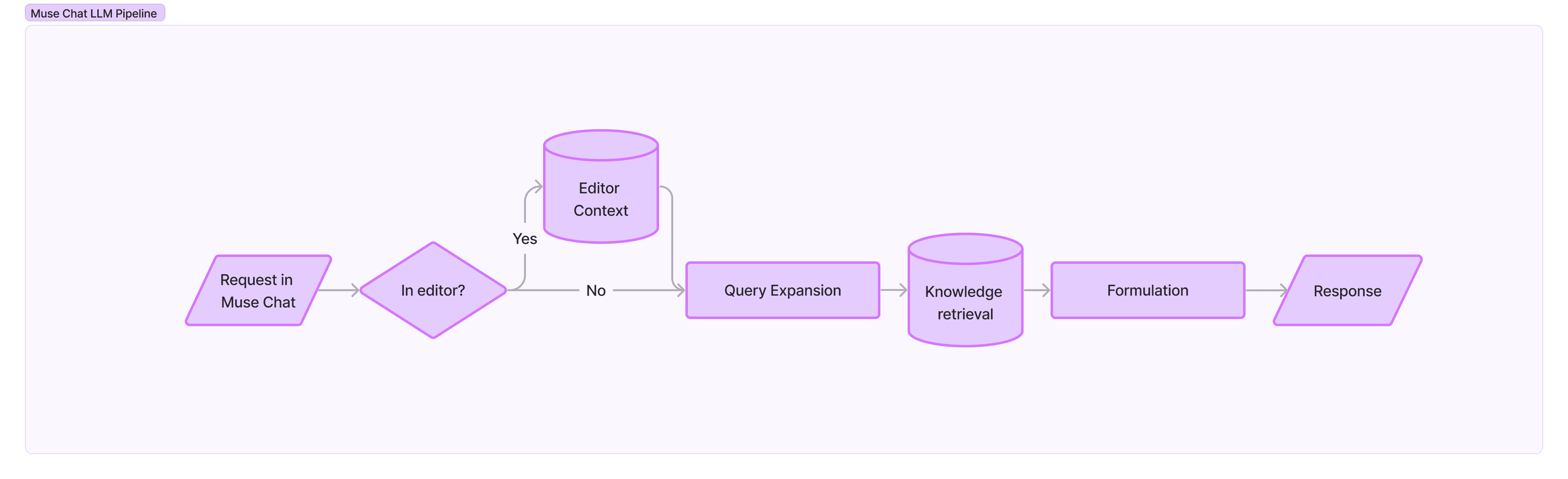
- SOLICITUD: Llega tu solicitud.
- CONTEXTO DEL EDITOR: Si está en el Editor, el contexto relevante se extrae dinámicamente del Editor, junto con la solicitud para dar a Muse la información adecuada.
- AMPLIACIÓN DE LA CONSULTA: El sistema de planificación inicial realiza la expansión de consultas, cuyo objetivo es derivar planes precisos. Instruimos a un LLM para que haga su mejor intento de replicar el formato del catálogo de conocimientos y recree la estructura ideal de un chunk para cada paso. Este enfoque permite al sistema calcular una incrustación que capture el contexto, el contenido y el caso de uso deseados del fragmento que buscamos. Cada uno de estos pasos del plan se utiliza para la recuperación semántica detallada.
- RECUPERACIÓN DE CONOCIMIENTOS: Para encontrar la información relevante, utilizamos la recuperación semántica simétrica y el filtrado de metadatos para recuperar los fragmentos de nuestro catálogo de conocimientos que más se parecen al fragmento estimado ideal, identificado en la etapa de expansión de la consulta.
- FORMULACIÓN: Para generar la respuesta final, utilizamos otro LLM para componer una respuesta, basada en el esquema detallado que contiene tanto los pasos del plan original filtrados como las fuentes necesarias para transmitir la información subyacente relevante.
- RESPUESTA: Muse Chat responde con una respuesta.
Para profundizar en el trabajo realizado para que Muse Chat esté disponible en el editor, hemos introducido el segundo paso del proceso, la extracción del contexto del editor. Al añadir esto al principio de la cadena de producción, analizamos la consulta para identificar qué extraer del editor y lo analizamos para informar a Muse sobre los siguientes pasos. Basándonos en sus comentarios, comenzamos con la configuración del proyecto, los ajustes del proyecto, GameObjects/Prefabs y el acceso a la consola.
Ahora, si se produjera un error de consola con advertencias o mensajes, basta con hacer clic en la(s) fila(s) correspondiente(s) de la consola para añadir el error como parte de la selección. En el siguiente ejemplo, se produce un error por falta de llaves en un script.

Considere un simple ejemplo de respuesta "¿Cómo puedo crear una característica scriptable y añadirla al Renderizador Universal?" en una nueva conversación en el Editor. Esto se convertirá en pasos del plan:
- SOLICITUD: "¿Cómo puedo crear una función scriptable apropiada para mi canal de renderizado?"
- CONTEXTO DEL EDITOR: Muse identifica qué canal de renderizado se utiliza, la versión de Unity que se está ejecutando, qué ajustes del proyecto son relevantes para la pregunta. A continuación, extrae el contexto dinámico, junto con cualquier selección del Editor que pueda tener.
- AMPLIACIÓN DE LA CONSULTA: LLM genera un plan con los siguientes pasos del plan:
Introducir el concepto y el propósito de las características scriptables para URP.
Explicar los pasos para crear una función scriptable en URP.
Proporcionar un ejemplo que muestre cómo añadir la función de scripting al Renderizador Universal.
- RECUPERACIÓN DE CONOCIMIENTOS: En este ejemplo, la solicitud se satisface siguiendo los pasos para recuperar información de la incrustación.
- FORMULACIÓN: LLM media en la respuesta final.
- RESPUESTA: Obtendrá una respuesta, como se ve a continuación, junto con un fragmento de código.
En el ejemplo anterior de URP, el plan de respuesta final se compone de una introducción basada en la sección "¿Qué es una función de renderizador programable?" de la documentación de URP, las instrucciones paso a paso de "Crear una función de renderizador programable y añadirla al renderizador universal" y las instrucciones de la subsección sobre cómo añadir finalmente la función de renderizador personalizada a un recurso del renderizador universal.
De este modo, podemos intercambiar eficazmente información genérica procedente del conocimiento base del LLM con conocimiento específico de la Unidad procedente de fuentes de primera mano relacionadas con enfoques recomendados o detalles de implementación. Aunque la aparición de información a veces imprecisa es algo inevitable cuando se utilizan LLM, nuestro sistema está diseñado para minimizar su frecuencia confiando en el conocimiento de la Unidad.
Estamos trabajando en el desarrollo de un amplio ecosistema compuesto por modelos de tareas específicas. A medida que ampliamos nuestra interoperabilidad con el Editor, queremos permitir un flujo de trabajo acelerado para atender mejor sus necesidades. Creemos que la clave para ello es adoptar y fomentar una cultura en la que podamos adaptarnos rápidamente a los avances de la investigación y la industria para experimentar con rapidez.
Muse Chat sirve de compañero para la creación asistida por IA, directamente en el Editor. Actualmente estamos trabajando para ampliar lo que puede seleccionar como parte de su contexto en el Editor, incluyendo la jerarquía completa y la ventana de proyecto, así como incluir el código asociado para un GameObject. Además, estamos invirtiendo en mejoras generalizadas del sistema, mejorando nuestros puntos de referencia de rendimiento en el conocimiento de Unity y la generación de código, y preparándonos para un futuro con el comportamiento de agente habilitado, para que Muse pueda realizar acciones en su nombre en el Editor.
En la GDC mostramos cómo utilizar las cinco funciones de Muse para personalizar un bucle de juego en la escena del jardín de nuestro proyecto de ejemplo URP. Consulte nuestra sesión "Unity Muse: Aceleración de la creación de prototipos en el Editor de Unity con AI"para aprender cómo puede utilizar todas las capacidades de Muse para personalizar rápidamente una escena de proyecto y el juego. Esta interoperabilidad entre las funciones de Muse no hará sino aumentar a medida que introduzcamos nuevas mejoras en Muse Chat.
Hemos actualizado la experiencia de incorporación a Muse para que resulte más sencillo iniciar una prueba gratuita de Muse y añadir los paquetes de Muse a sus proyectos. Visite la nueva página Muse Explore para empezar y díganos qué le parecen las nuevas funciones y mejoras de Debates.