Otimizando o desempenho com um sistema de vegetação personalizado para Thrive: Pesada é a Coroa

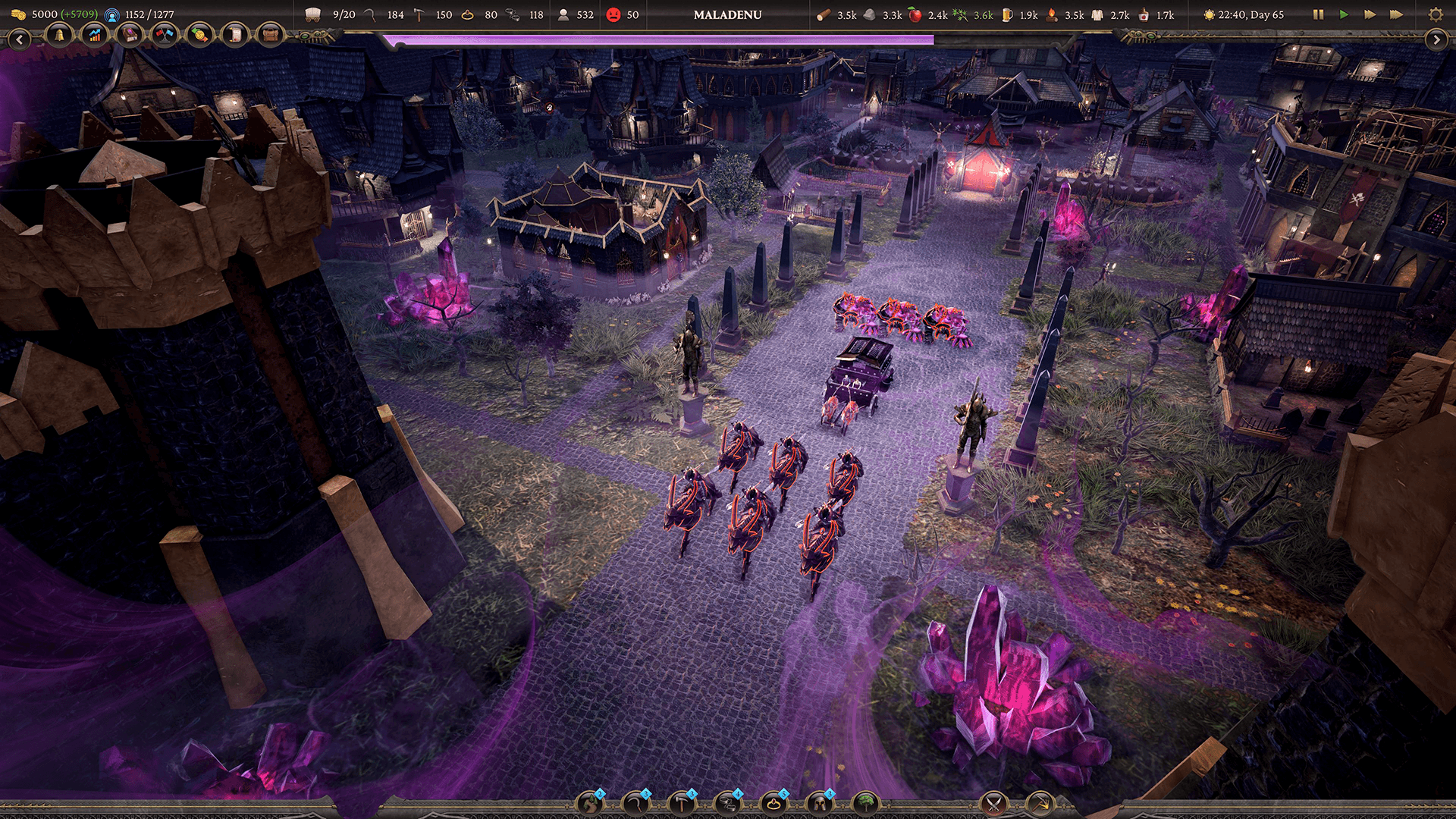
A Zugalu Entertainment foi fundada em 2014 para criar jogos que misturam inovação, nostalgia e apelo comercial. Nos últimos 11 anos, eles lançaram títulos incluindo Epic Food Fight, Technolites, Chronique des Silencieux e Sovereign Syndicate.
Em 6 de novembro de 2024, eles lançaram Thrive: Heavy Lies the Crown em Acesso Antecipado, com ótimas críticas. O jogo é um construtor de cidades medievais com elementos de estratégia em tempo real e funcionalidade multiplayer tanto para um jogador quanto cooperativa. Os jogadores podem expandir estrategicamente seu território e seu reino, e então construir ao longo de um grande mapa. À medida que suas jornadas progridem, o destino do reino depende de cada decisão que tomam.
Hoje, a equipe lançou a versão 1.0 do jogo. Nós nos sentamos com Garrett Hau, CTO da Zugalu Entertainment, e Jackie Li, a artista conceitual e técnica líder da equipe, para discutir os desafios de desempenho que encontraram e como construir um sistema de vegetação personalizado foi fundamental para a otimização do jogo.
Construindo um sistema de vegetação personalizado
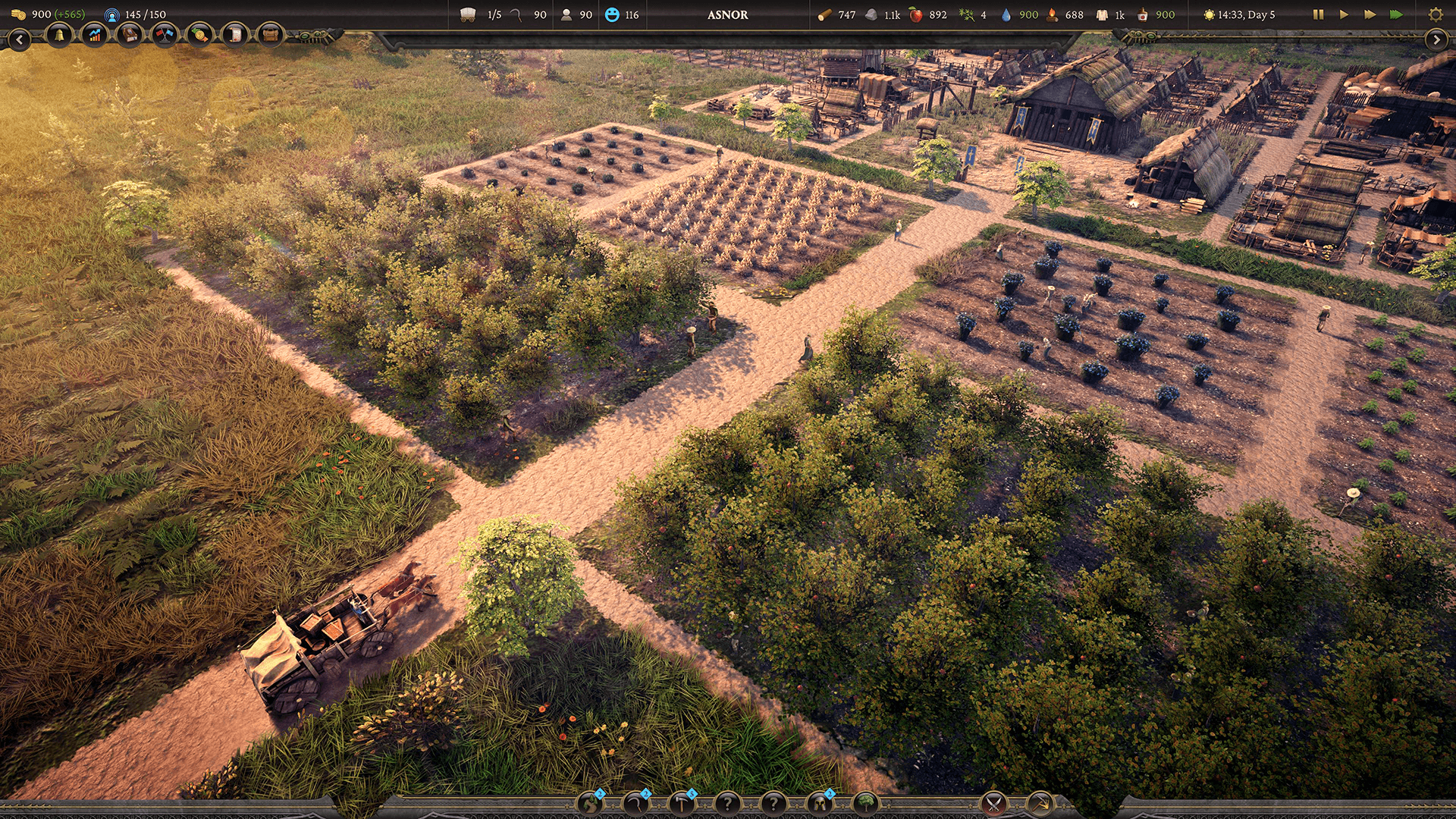
Como o jogo se passa na natureza, há muitas árvores, grama, arbustos, etc. Na implementação original, a grama era muito escassa, mas a equipe queria criar um campo expansivo e exuberante de grama. “Para muitos de nossos diferentes biomas, como o bioma de pastagem, queríamos cobrir o chão cheio de vegetação,” diz Hau. Para alcançar isso, eles precisavam de um sistema que pudesse lidar com um alto número de instâncias de vegetação.
Durante a maior parte do projeto, a equipe estava usando uma solução de terceiros, que funcionava bem, exceto que era muito dependente da CPU, custava cerca de 3 milissegundos e o jogo estava muito limitado pela CPU. Como eles tinham um requisito de sistema bastante baixo, decidiram transferir a maioria dos cálculos para a GPU e precisavam de um tipo diferente de solução.
“Decidimos fazer nosso próprio sistema e, ao mesmo tempo, integrar com a natureza baseada em tiles do jogo. O sistema original tinha sua própria forma de funcionar, e certas interações no nível de cada tile eram muito custosas,” diz Hau.
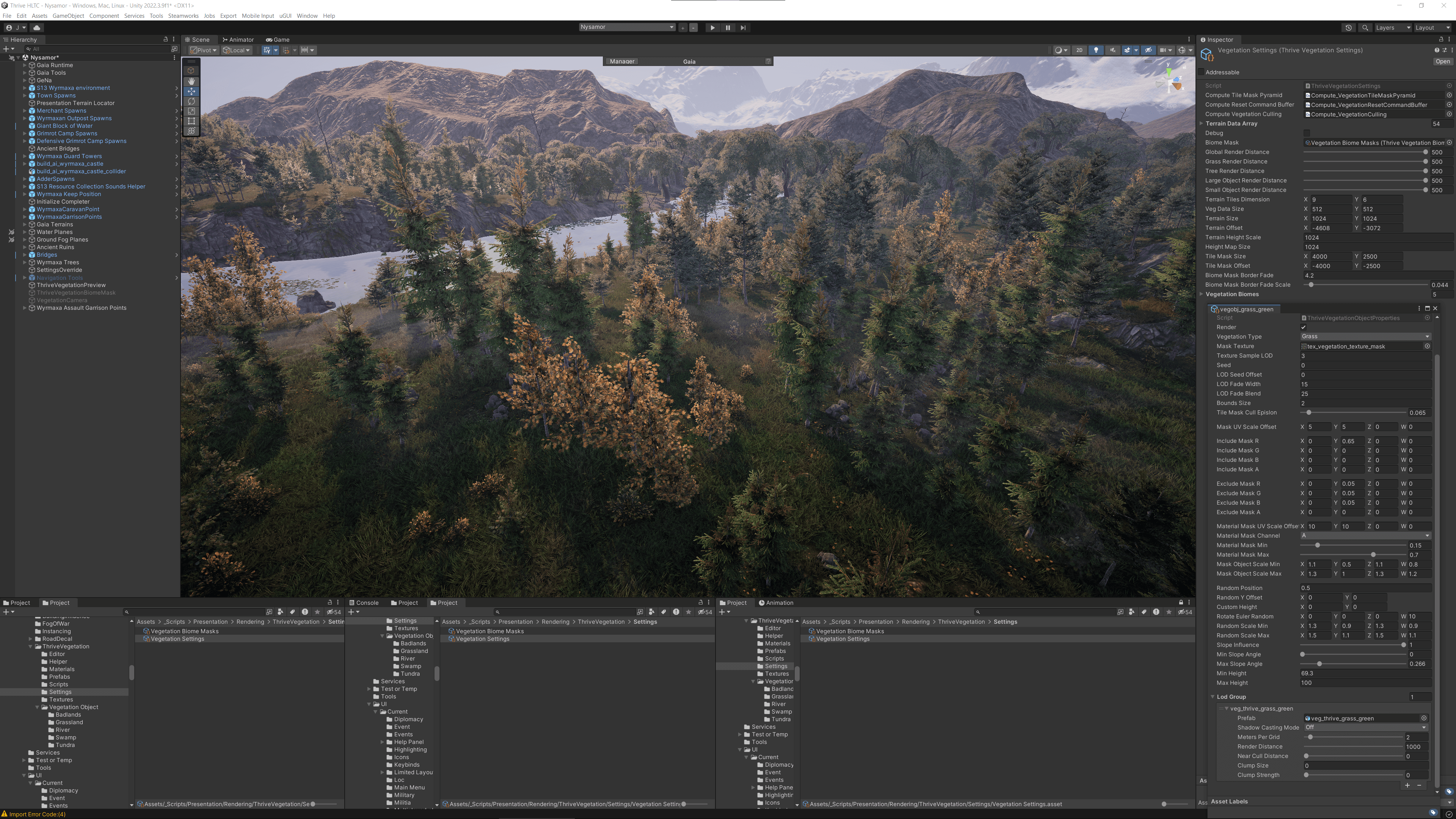
Eles queriam corrigir isso e conseguir ter vegetação de maior densidade. Como estavam calculando na GPU em seu novo sistema, tinham mais espaço de desempenho e a oportunidade de criar uma floresta exuberante.
Outro objetivo chave era obter mascaramento por tile. “Antes, quando você colocava uma estrada, não podia ser mascarada de forma eficiente, então a vegetação simplesmente crescia em cima das estradas,” diz Hau. Como o método inicial dependia da CPU, cada máscara adicional a sobrecarregava, e eles queriam que as estradas, ou qualquer coisa na verdade, mascarassem a grama ou vegetação sem consumir muito desempenho.
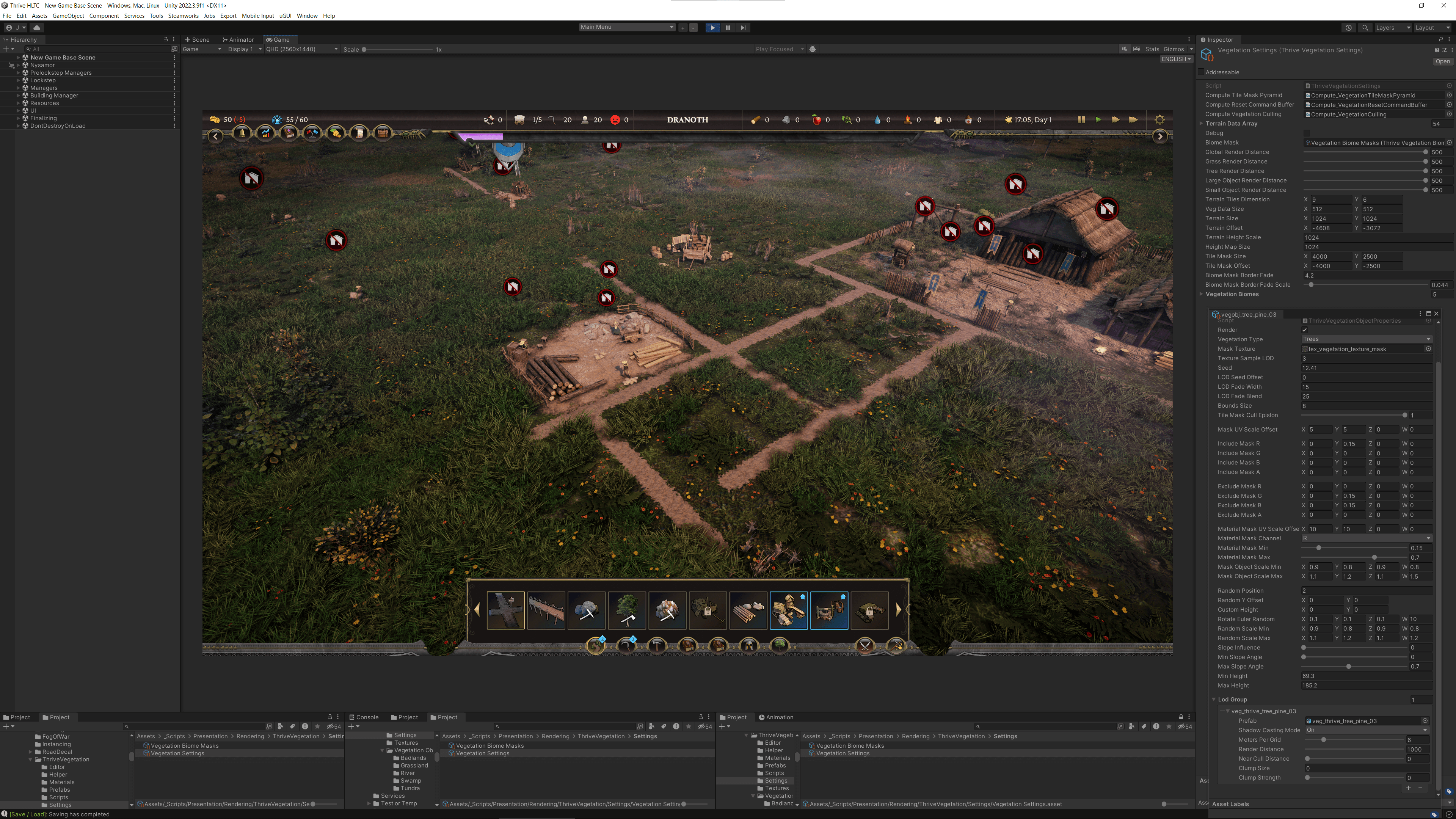
Executando com shaders de computação
A equipe também enfrentou um grande gargalo ao tentar gerar a vegetação em seu grande mapa. Como o jogo tem uma abundância de vegetação e uma câmera realmente alta que pode se mover rapidamente pelo mapa, era importante que a vegetação surgisse sem interromper o jogador. Isso se mostrou muito difícil.
“Quando você olha para a vegetação, vê que precisa gerar potencialmente centenas de milhares de instâncias. Então escolhemos a instância de GPU, que foi projetada para esse propósito exato, permitindo potencialmente milhões de instâncias,” diz Li.
Para começar, a equipe preparou os dados para a instância de GPU. Eles precisavam construir e fornecer à GPU um array de todas as posições onde queriam gerar sua vegetação. A vegetação não interage realmente com o lado da CPU fora do mascaramento por tile, então eles executaram isso com um shader de computação. Como o shader de computação rodava na GPU antes que seus shaders de renderização fossem executados, eles prepararam os dados em seu shader de computação e, em seguida, forneceram os dados resultantes para a instância. Isso também é conhecido como instância indireta.

O próximo passo foi descobrir como usar os shaders de computação, o que se mostrou relativamente fácil. Li explica que, “Um shader de computação é apenas uma operação multithreaded na GPU. No nosso caso, cada dado de instância pode ser calculado individualmente em cada thread. Pense nisso como o Sistema de Trabalho do Unity, mas na GPU.”
Ao trabalhar em um ambiente multithreaded, a carga de trabalho de cada thread deve ser elaborada de forma que não dependa de execuções em outras threads para maximizar o desempenho.
Li diz: “Por exemplo, ao adicionar aleatoriedade, usaríamos coisas como ruído de Perlin, ruído Simplex ou funções hash. A superfície avaliada atual também é dividida em uma grade uniforme, com cada thread operando dentro de cada ponto da grade para que não precisemos nos preocupar em gerar vegetação duplicada uma em cima da outra.”
Como o terreno não era deformável em tempo de execução, eles recuperaram esses dados no início do desenvolvimento e os passaram para a GPU. Isso permitiu o pré-processamento dos dados de altura, notavelmente para calcular a inclinação em cada posição de altura, para que a vegetação pudesse ser personalizada para seguir o contorno do terreno.
Consolidando shaders de computação
Embora a equipe estivesse usando shaders de computação, eles tiveram que executar muitos deles para obter os dados que desejavam. Semelhante às chamadas de desenho, menos é melhor. Eles estavam procurando reduzir o número de comandos da GPU eliminando metade das chamadas de despacho e, em seguida, combinando a transferência de dados da CPU para a GPU em uma única chamada de API.
“Nosso sistema de vegetação é composto por muitos tipos diferentes de vegetação, cada tipo de vegetação requerendo um despacho de computação,” explica Li. “Com 50 vegetações, isso seria 50 despachos, cada um com n-número de threads.”
O objetivo de cada thread era calcular uma posição de instância, junto com alguns outros dados, mas também era altamente possível que uma thread calculasse uma posição eliminada, seja por ser uma posição mascarada ou fora do frustum da câmera, caso em que os dados não são adicionados ao array de instâncias que é então usado para desenhar a vegetação.
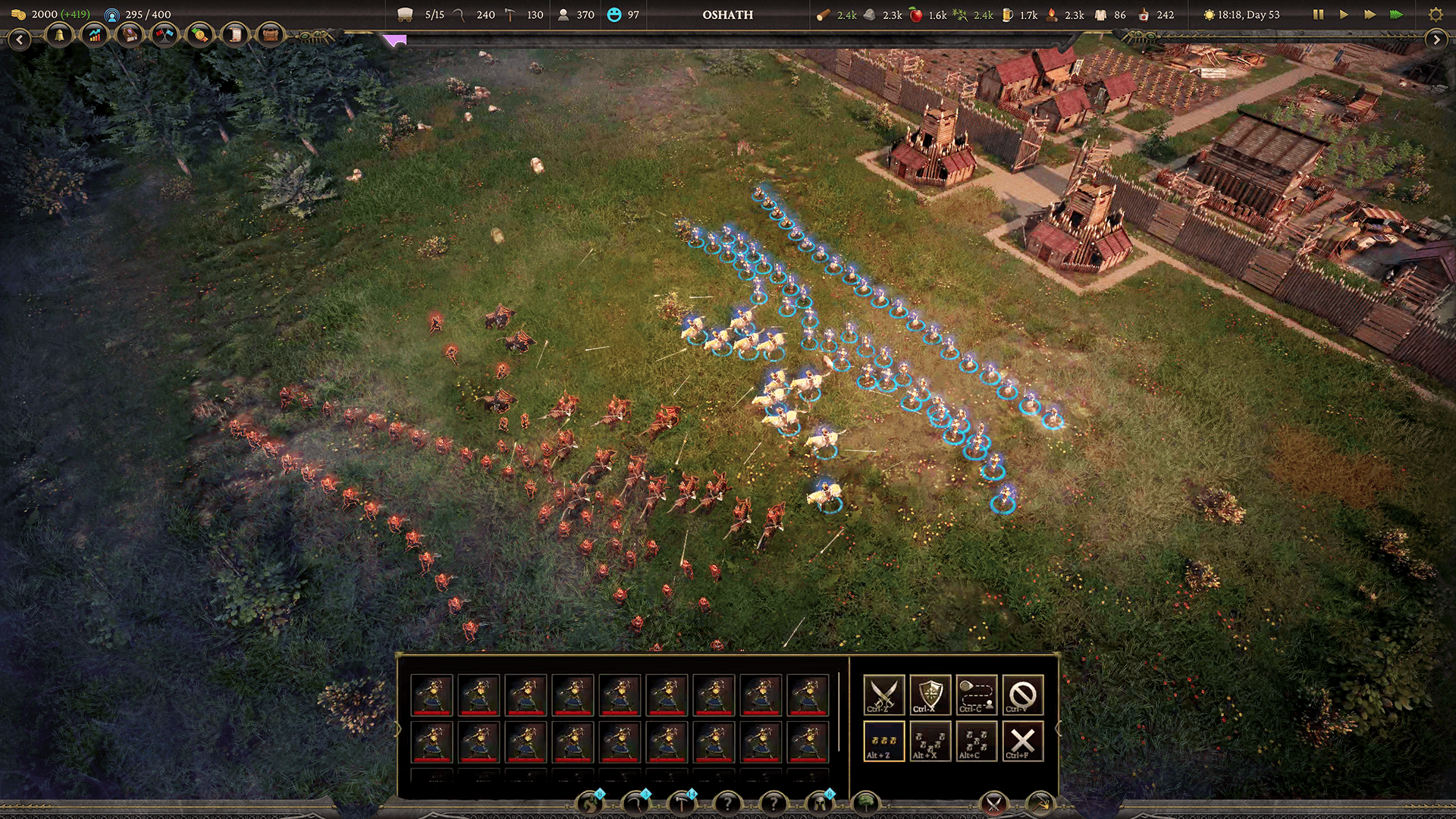
Como uma thread pode ou não adicionar ao array, usamos alguma forma de estrutura de dados de lista segura para threads, onde anexamos o valor válido à lista. HLSL convenientemente fornece esse recurso na forma de um buffer de anexação. “Usar um buffer de anexação tem uma pequena desvantagem”, diz Li. “Eu tive que executar comandos extras da GPU para pegar a contagem de itens adicionados e também para limpar essa contagem para que o buffer de anexação pudesse ser reutilizado.”
No entanto, o shader de computação forneceu uma variável conveniente conhecida como grupos compartilhados, que permitiu a comunicação de thread para thread. E isso, em combinação com a função Interlocked , permitiu que cada despacho mantivesse o controle de um contador de índice global, permitindo que os dados de instância válidos fossem compactados de forma eficiente, e comandos de desenho indiretos fossem atualizados tudo dentro da mesma chamada de despacho que estava calculando a posição da instância.
Ao enviar os dados da CPU, a equipe inicialmente enfrentou uma penalidade de desempenho. Eles tiveram que atualizar as propriedades do shader para os diferentes tipos de vegetação, que mudavam de quadro para quadro.
“Originalmente, eu estava enviando os dados separadamente, resultando em 50 comandos SetData()”, diz Li. “No entanto, como o tipo de dado subjacente era o mesmo, consolidamos todos os dados em um único buffer e, em seguida, fornecemos a cada tipo de vegetação um índice de deslocamento nesse buffer. Isso permitiu apenas um comando SetData().”
A equipe estima conservadoramente que economizou 0,1 milissegundos de tempo de CPU, representando 20% do total de 0,5 milissegundos.
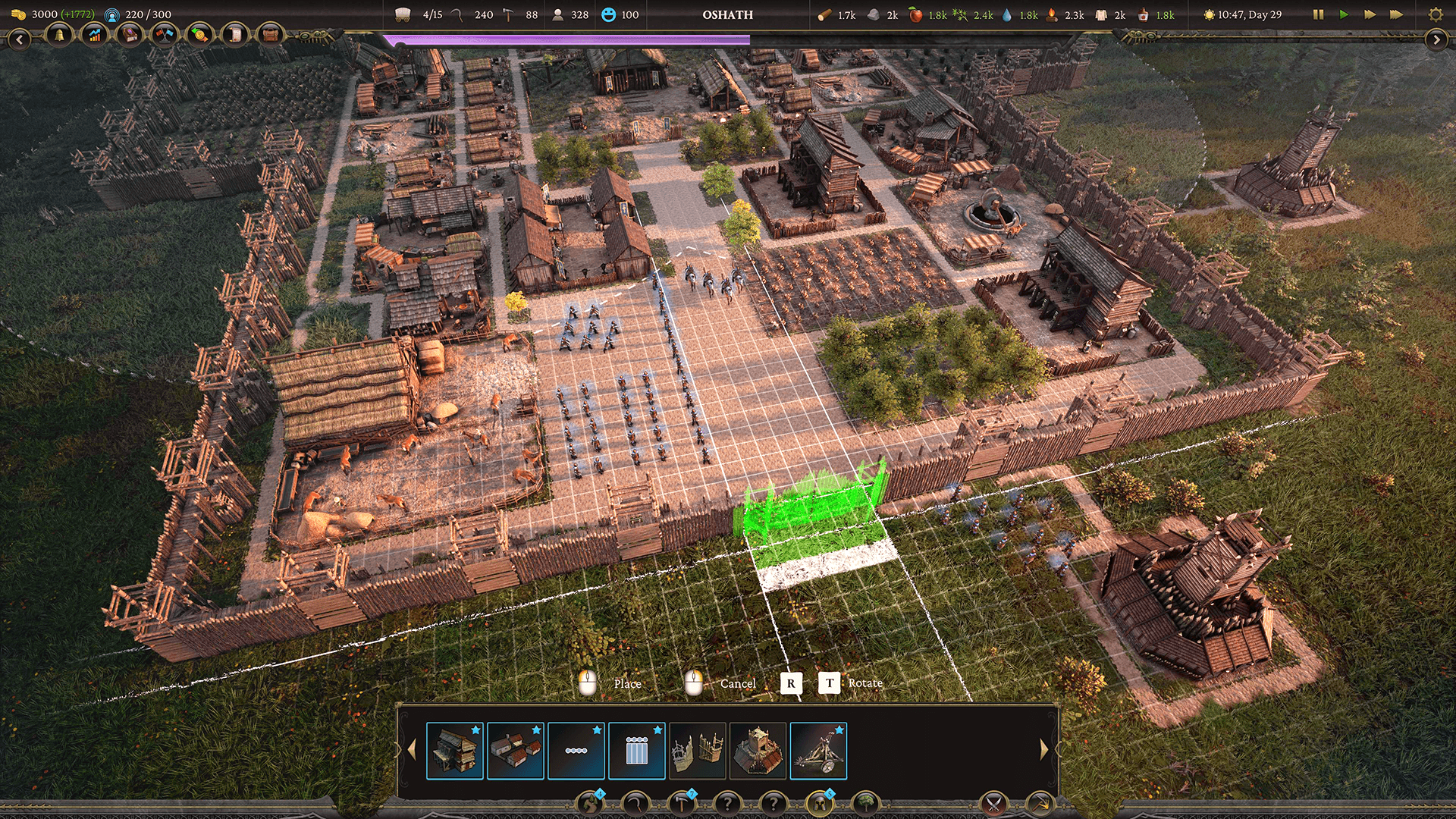
Enviando dados de tile da CPU para a GPU
Como o mapa era muito grande, aproximadamente 10 milhões de tiles, a equipe teve dificuldades para pegar os dados de tile da CPU para a GPU. “Tentar enviar milhões de tiles por quadro para a GPU seria muito custoso porque é uma grande quantidade de dados para enviar. Precisávamos ser capazes de enviar um subconjunto de dados suficientes para ocupar a tela,” diz Hau.
Eles usaram o Sistema de Trabalho da Unity para conseguir isso. Isso os ajudou no lado da CPU e forneceu uma maneira multithreaded de pegar os dados e enviá-los para a GPU. Hau explica que, "Quando se trata de extrair dados de um array, é uma carga de trabalho perfeita que pode ser acelerada pelo Sistema de Tarefas."
Cada thread pode ser executada para pegar um segmento de dados, que é então copiado para um array de destino. Ao mesmo tempo, eles converteram os dados originais de 16 bits em dados compactados de 32 bits usados no shader de computação.
A equipe também aplicou o Compilador Burst aos dados do Sistema de Tarefas para criar código otimizado. "O Compilador Burst melhorou significativamente o desempenho multithreaded. Uma vez que coloquei o atributo lá, rapidamente passou de mais de um milissegundo para menos de 0,3 milissegundo. Foi muito impressionante por apenas adicionar uma linha de código," diz Hau.
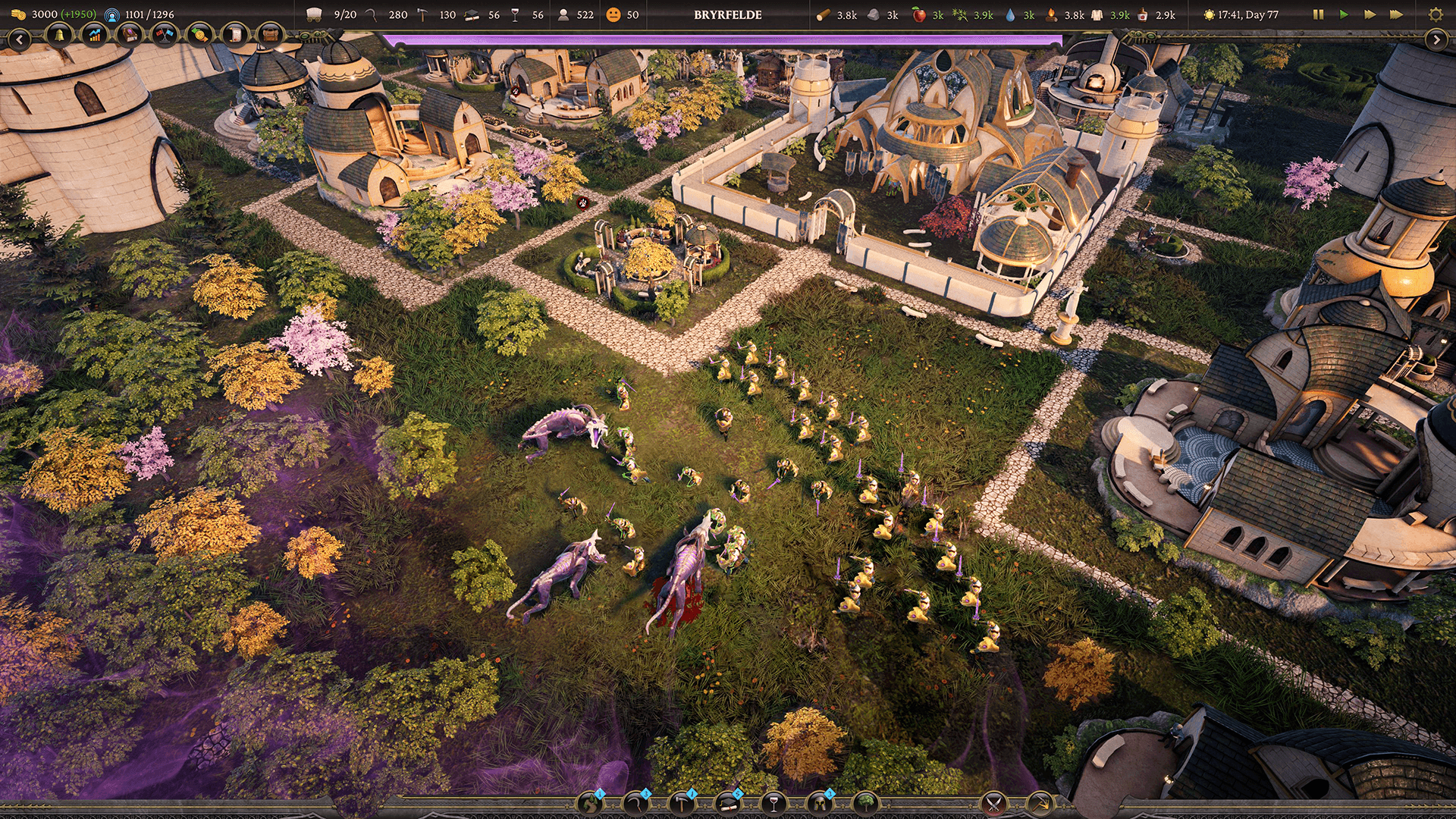
Enquanto a equipe experimentou grandes ganhos de otimização, eles também estão cientes de que o desempenho de renderizar toda a vegetação é algo a se observar.
"Embora estejamos empolgados com a economia de desempenho, o overdraw ainda é um problema que meu sistema não resolve," explica Li. "Precisamos manter isso em mente. No entanto, estamos além de felizes com o resultado do jogo."
Para ler mais sobre projetos feitos com Unity, visite a Página de Recursos.