Оптимизация производительности с помощью пользовательской системы растительности для Thrive: Тяжело лежит корона

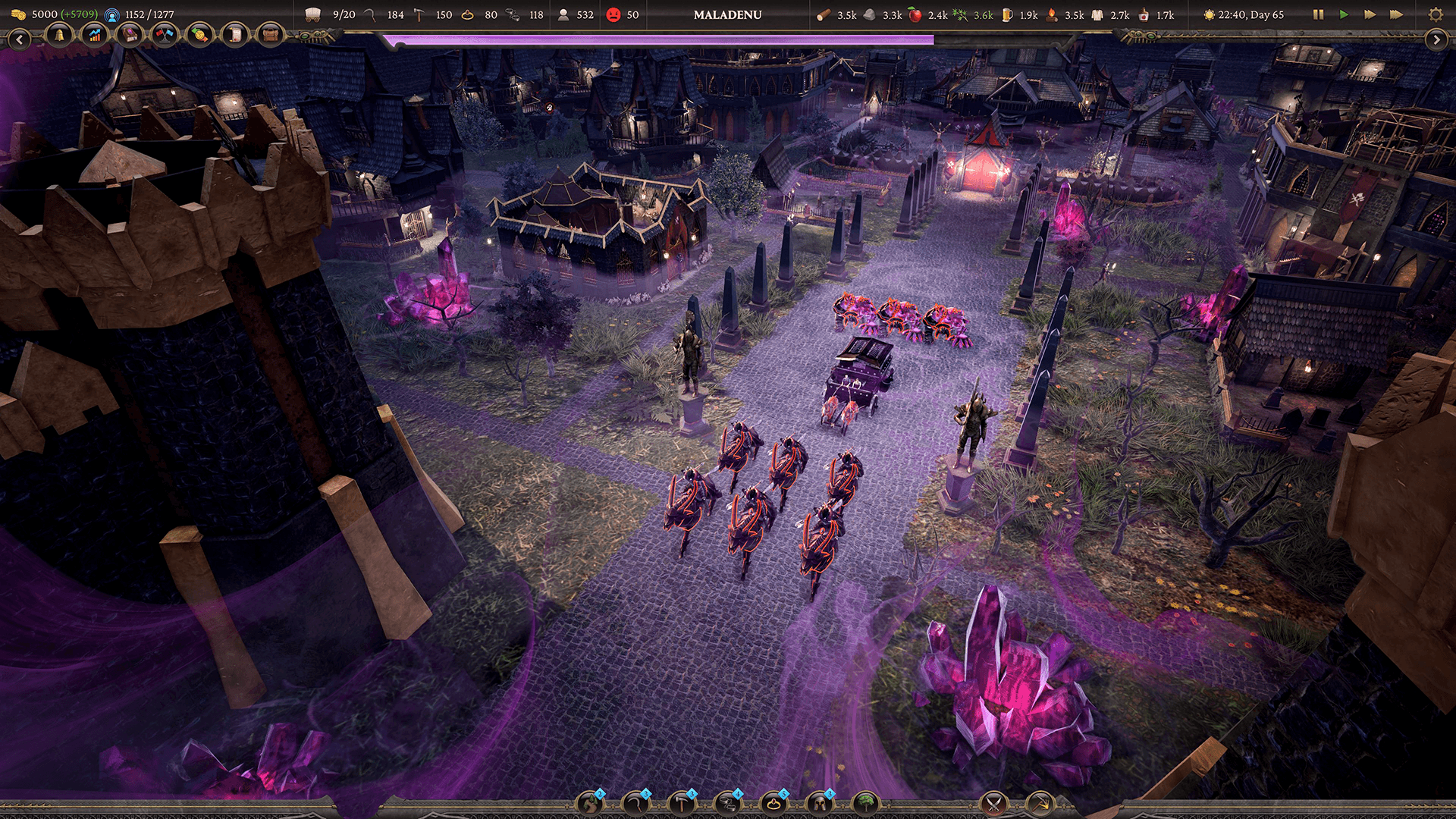
Zugalu Entertainment была основана в 2014 году для создания игр, которые сочетают в себе инновации, ностальгию и коммерческую привлекательность. За последние 11 лет они выпустили такие игры, как Epic Food Fight, Technolites, Chronique des Silencieux и Sovereign Syndicate.
6 ноября 2024 года они выпустили Thrive: Heavy Lies the Crown в раннем доступе, получив отличные отзывы. Игра является средневековым строительством города с элементами стратегии в реальном времени и как одиночным, так и кооперативным мультиплеерным функционалом. Игроки могут стратегически расширять свою территорию и королевство, а затем строить на большой карте. По мере продвижения их путешествий судьба королевства зависит от каждого их решения.
Сегодня команда выпустила 1.0 версию игры. Мы встретились с Гарретом Хау, техническим директором Zugalu Entertainment, и Джеки Ли, ведущим концептуальным художником и техническим художником команды, чтобы обсудить проблемы с производительностью, с которыми они столкнулись, и как создание пользовательской системы растительности было ключом к оптимизации игры.
Создание пользовательской системы растительности
Поскольку игра происходит в дикой природе, там много деревьев, травы, кустов и т.д. В оригинальной реализации трава была очень редкой, но команда хотела создать обширное и пышное поле травы. «Для многих наших различных биомов, таких как биом травянистой местности, мы хотели покрыть землю растительностью», — говорит Хау. Чтобы достичь этого, им нужна была система, которая могла бы обрабатывать большое количество экземпляров растительности.
На протяжении большей части проекта команда использовала стороннее решение, которое работало хорошо, за исключением того, что оно сильно нагружало ЦП, занимая около 3 миллисекунд, и игра была сильно ограничена по ЦП. Поскольку у них были довольно низкие системные требования, они решили перенести большую часть расчетов на графический процессор и нуждались в другом решении.
«Мы решили создать свою собственную систему и одновременно интегрироваться с плиточной природой игры. Оригинальная система имела свой собственный способ работы, и определенные взаимодействия на уровне плитки были слишком затратными», — говорит Хау.
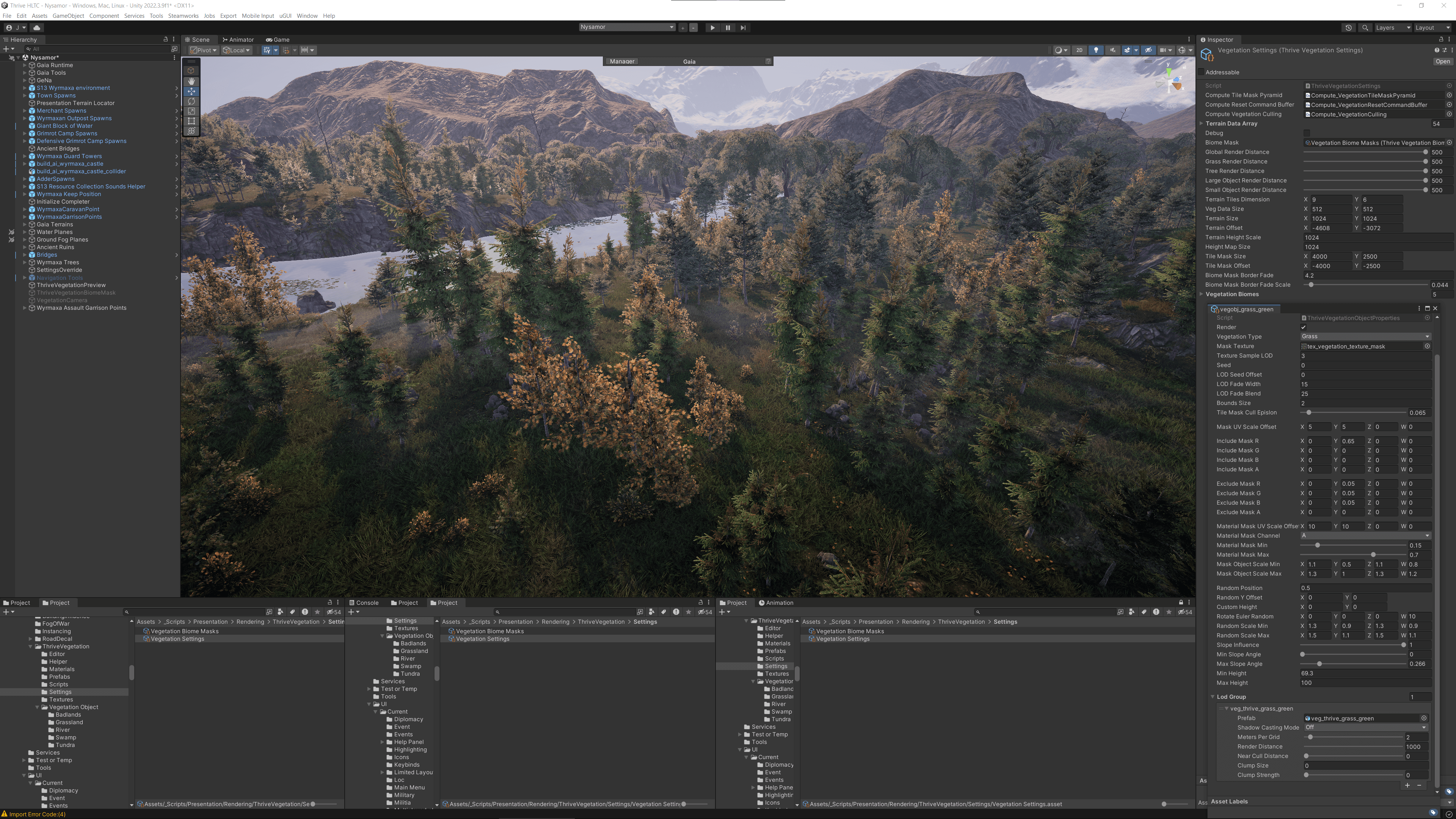
Они хотели это исправить и иметь возможность создавать более плотную растительность. Поскольку они рассчитывали на GPU в своей новой системе, у них было больше производительности и возможность создать цветущий лес.
Еще одной ключевой целью было получение маскирования по плиткам. «Раньше, когда вы укладывали дорогу, ее нельзя было эффективно замаскировать, поэтому растительность просто росла поверх дорог», — говорит Хау. Поскольку первоначальный метод зависел от CPU, каждая дополнительная маска нагружала его, и они хотели, чтобы дороги или что-то еще могли замаскировать траву или растительность, не потребляя много производительности.
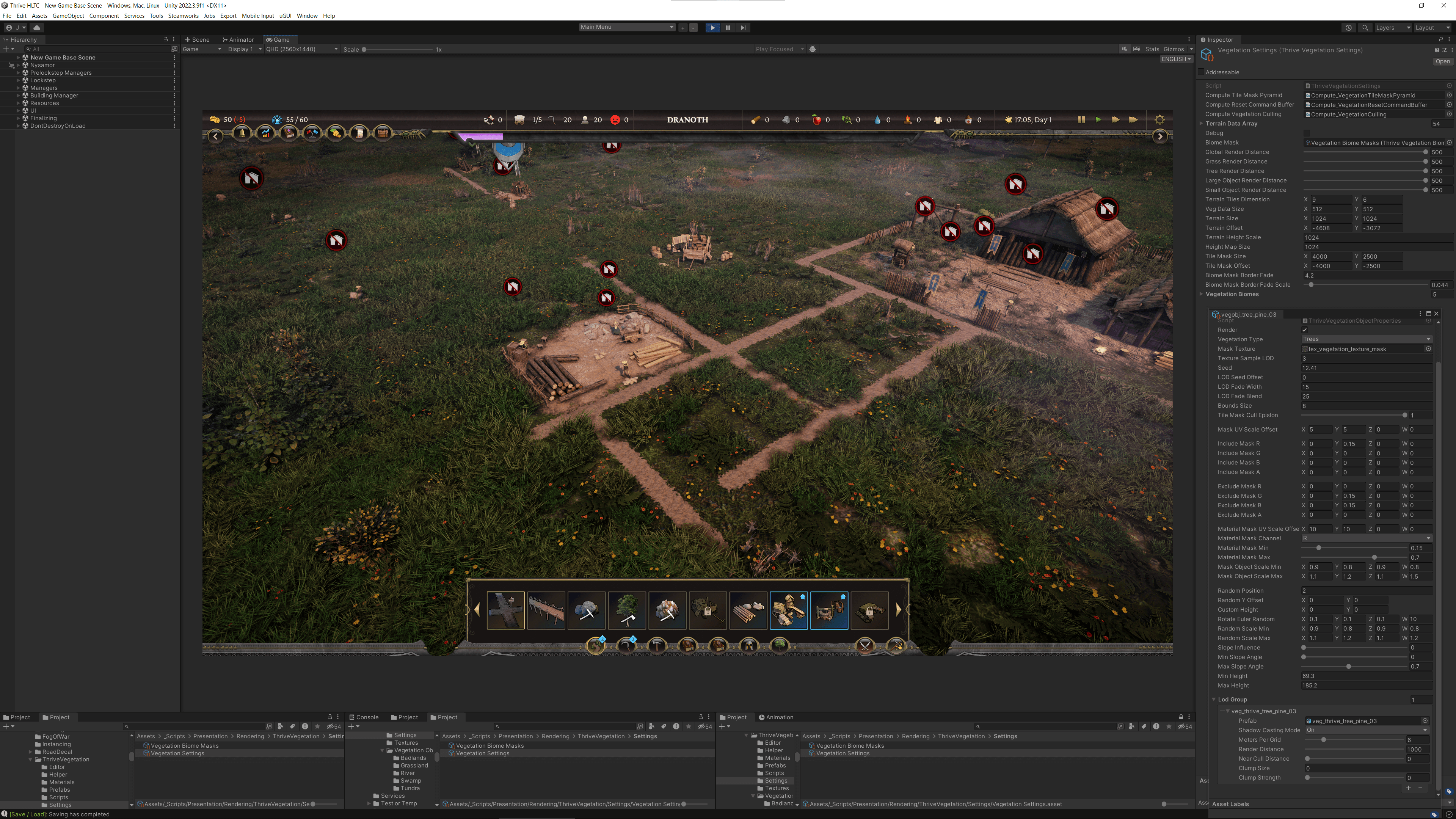
Выполнение с помощью вычислительных шейдеров
Команда также столкнулась с серьезной узкой местом при спавне растительности на своей большой карте. Поскольку в игре много растительности и очень высокая камера, которая может быстро перемещаться по карте, было важно, чтобы растительность спавнилась, не останавливая игрока. Это оказалось очень сложным.
«Когда вы смотрите на растительность, вы видите, что вам нужно спавнить потенциально сотни тысяч экземпляров. Поэтому мы выбрали инстансинг на GPU, который был разработан для этой конкретной цели, позволяя потенциально миллионам экземпляров», — говорит Ли.
Для начала команда подготовила данные для инстансинга на GPU. Им нужно было создать и передать GPU массив всех позиций, на которых они хотели спавнить свою растительность. Растительность на самом деле не взаимодействует с стороной CPU, кроме маскирования плиток, поэтому они выполняли это с помощью вычислительного шейдера. Поскольку вычислительный шейдер выполнялся на GPU до выполнения их рендер-шейдеров, они подготовили данные в своем вычислительном шейдере, а затем передали полученные данные для инстансинга. Это также известно как косвенный экземпляр.

Следующим шагом было выяснить, как использовать вычислительные шейдеры, что оказалось относительно простым. Ли объясняет, что «вычислительный шейдер — это просто многопоточная операция на GPU.» В нашем случае данные каждого экземпляра могут быть индивидуально рассчитаны в каждом потоке. Думайте об этом как о системе заданий Unity, но на GPU.»
При работе в многопоточной среде нагрузка каждого потока должна быть спроектирована так, чтобы они не зависели от выполнения в других потоках для максимизации производительности.
Ли говорит: «Например, при добавлении случайности мы бы использовали такие вещи, как шум Перлина, шум Simplex или хеш-функции. Текущая оцениваемая поверхность также делится на равномерную сетку, при этом каждый поток работает в каждой точке сетки, чтобы нам не пришлось беспокоиться о появлении нескольких дублирующих растений друг на друге.»
Поскольку местность не была деформируемой во время выполнения, они получили эти данные в начале разработки и передали их на GPU. Это позволило предварительно обработать данные высоты, в частности для расчета наклона на каждой высоте, чтобы растения могли быть настроены в соответствии с контуром местности.
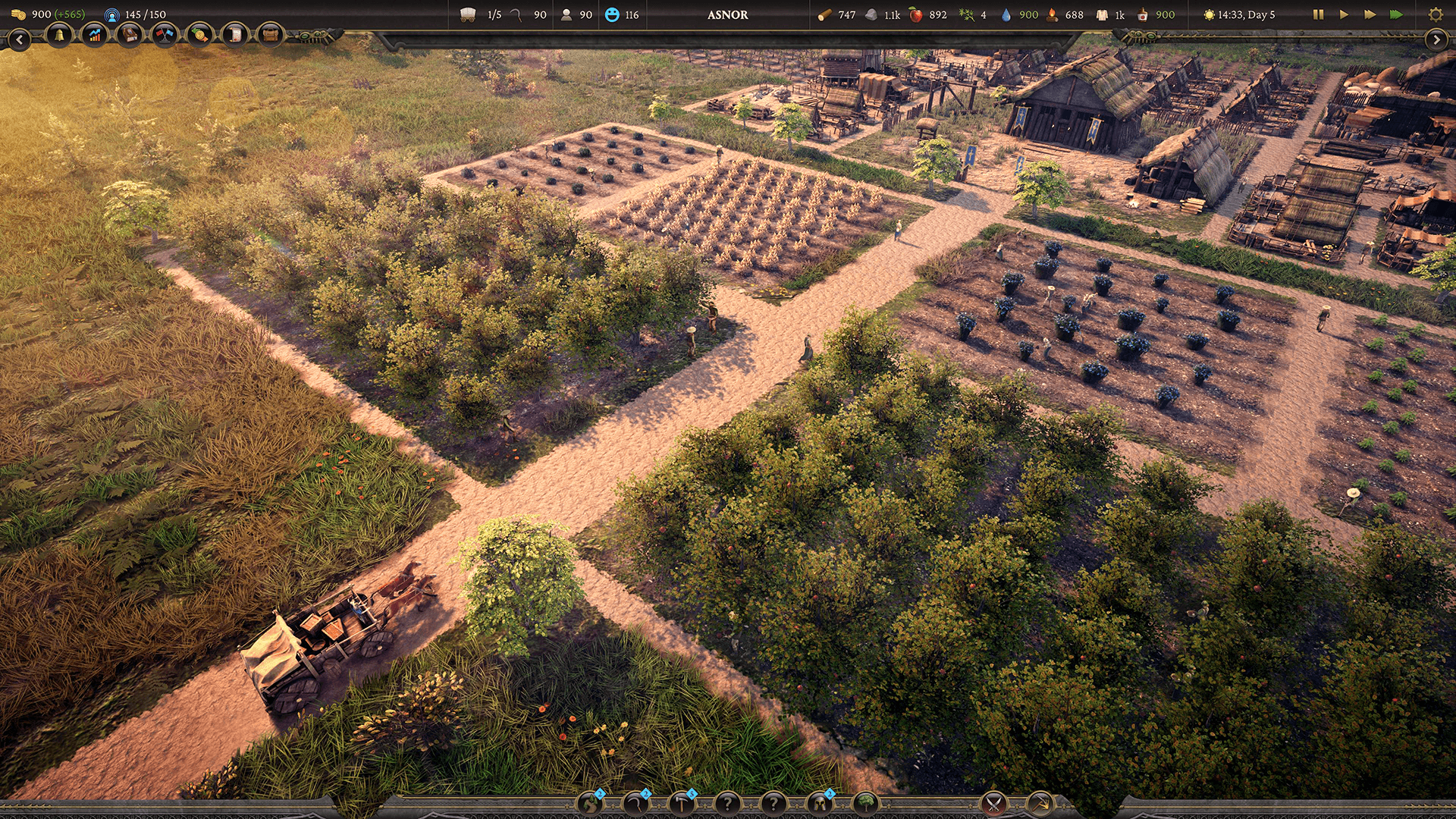
Консолидация вычислительных шейдеров
Хотя команда использовала вычислительные шейдеры, им пришлось выполнить много из них, чтобы получить нужные данные. Аналогично вызовам отрисовки, меньше — лучше. Они стремились сократить количество команд GPU, устранив половину вызовов диспетчера, а затем объединив передачу данных CPU на GPU в один вызов API.
«Наша система растительности состоит из многих различных типов растительности, каждый тип растительности требует вычислительного диспетча», — объясняет Ли. «С 50 растениями это будет 50 диспетчей, каждый с n-количеством потоков.»
Цель каждого потока заключалась в том, чтобы рассчитать позицию экземпляра, а также некоторые другие данные, но также было очень вероятно, что поток рассчитал отфильтрованную позицию, либо будучи замаскированной позицией, либо находясь за пределами фрустрации камеры, в этом случае данные не добавляются в массив экземпляров, который затем используется для отрисовки растительности.
Поскольку поток может добавлять или не добавлять в массив, мы использовали какую-то форму потокобезопасной структуры данных, где мы добавляли допустимое значение в список. HLSL удобно предоставляет эту функцию в виде буфера добавления. «Использование буфера добавления имеет небольшой недостаток», говорит Ли. «Мне пришлось выполнять дополнительные команды GPU, чтобы получить количество добавленных элементов и также очистить это количество, чтобы буфер добавления мог быть повторно использован.»
Тем не менее, вычислительный шейдер предоставил удобную переменную, известную как групповая память, которая позволяла осуществлять связь между потоками. И это, в сочетании с функцией Interlocked , позволяло каждому вызову отслеживать глобальный индексный счетчик, позволяя допустимым данным экземпляра быть плотно упакованными, а команды косвенного рисования обновляться в рамках одного и того же вызова, который вычислял позицию экземпляра.
При отправке данных CPU команда изначально столкнулась с потерей производительности. Им пришлось обновлять свойства шейдера для различных типов растительности, которые менялись от кадра к кадру.
«Изначально я отправлял данные отдельно, что приводило к 50 командам SetData()», говорит Ли. «Однако, поскольку основной тип данных был одинаковым, мы консолидировали все данные в один буфер, а затем предоставили каждому типу растительности смещение в этом буфере. Это позволило использовать всего одну команду SetData().»
Команда осторожно оценивает, что они сэкономили 0,1 миллисекунды времени CPU, что составляет 20% от общего времени 0,5 миллисекунды.
Отправка данных тайлов с CPU на GPU
Поскольку карта была очень большой, примерно 10 миллионов тайлов, команде было трудно захватить данные тайлов с CPU на GPU. «Попытка отправить миллионы тайлов за кадр на GPU будет очень затратной, потому что это много данных для отправки. Нам нужно было иметь возможность отправить подмножество достаточно данных, чтобы занять экран», говорит Хау.
Они использовали систему заданий Unity, чтобы достичь этого. Это помогло им на стороне CPU и предоставило многопоточный способ захвата данных и отправки их на GPU. Хау объясняет, что «Когда дело доходит до извлечения данных из массива, это идеальная нагрузка, которую можно ускорить с помощью системы заданий.»
Каждый поток может быть выполнен для извлечения сегмента данных, который затем копируется в массив назначения. В то же время они преобразовали оригинальные 16-битные данные в упакованные 32-битные данные, используемые в вычислительном шейдере.
Команда также применяла компилятор Burst к данным системы заданий для создания оптимизированного кода. «Компилятор Burst значительно улучшил многопоточную производительность. Как только я добавил атрибут, время выполнения быстро сократилось с более одной миллисекунды до менее 0,3 миллисекунды. Это было очень впечатляюще, учитывая, что я добавил всего одну строку кода», — говорит Хау.
Хотя команда испытала большие выигрыши в оптимизации, они также осознают, что производительность рендеринга всей растительности — это то, на что стоит обратить внимание.
«Хотя мы в восторге от экономии производительности, перерасход все еще является проблемой, которую моя система не решает», — объясняет Ли. «Нам нужно держать это в уме. Тем не менее, мы более чем довольны тем, как получилась игра.»
Чтобы узнать больше о проектах, сделанных с помощью Unity, посетите страницу Ресурсы.