Optimisation des performances avec un système de végétation personnalisé pour Thrive : Heavy Lies the Crown

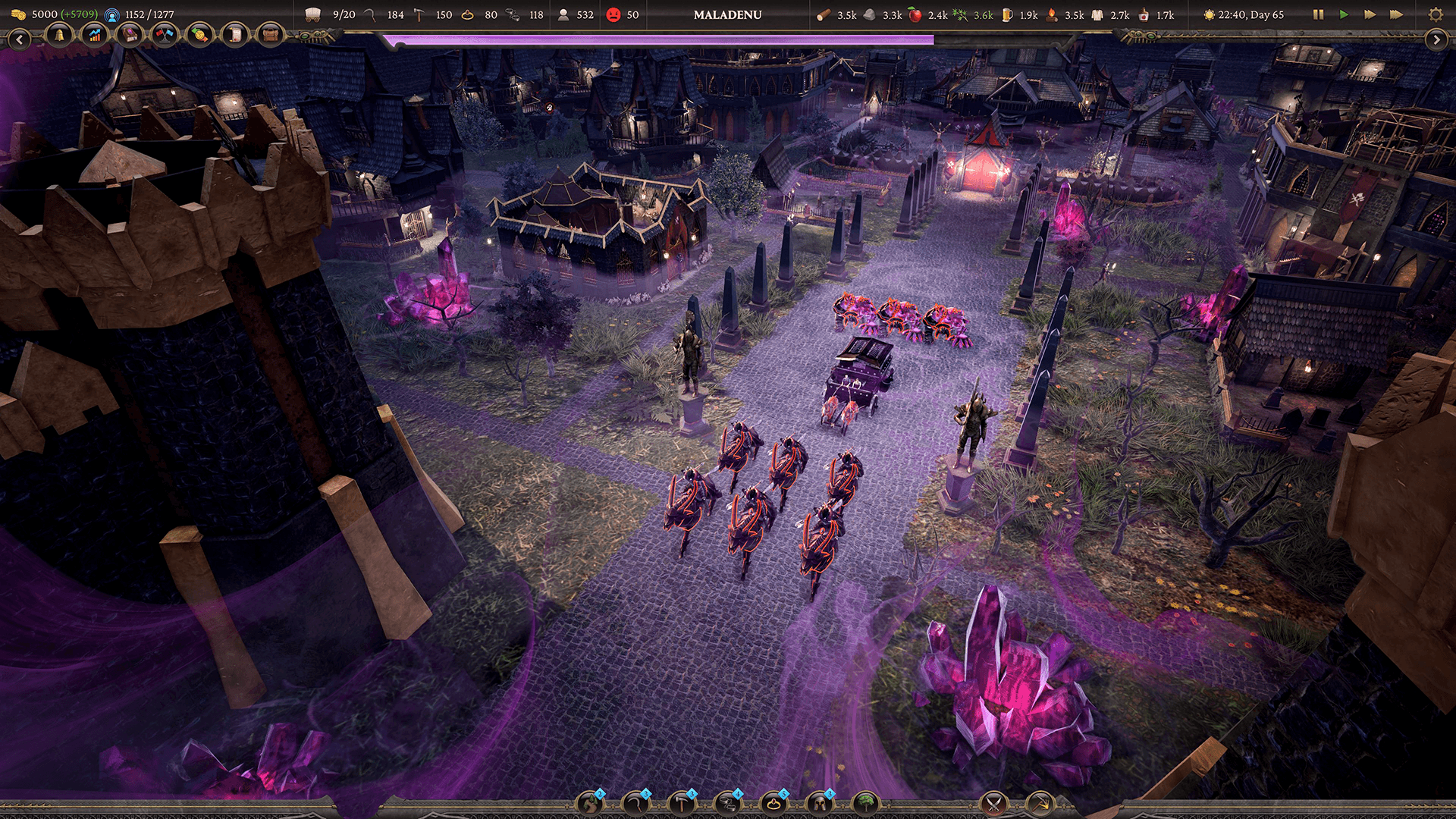
Zugalu Entertainment a été fondé en 2014 pour créer des jeux qui allient innovation, nostalgie et attrait commercial. Au cours des 11 dernières années, ils ont publié des titres tels que Epic Food Fight, Technolites, Chronique des Silencieux et Sovereign Syndicate.
Le 6 novembre 2024, ils ont publié Thrive: Heavy Lies the Crown en accès anticipé, avec de superbes critiques. Il s'agit d'un bâtisseur de ville médiévale avec des éléments de stratégie en temps réel et une fonctionnalité Multiplayer solo et coopérative. Les joueurs peuvent étendre stratégiquement leur territoire et leur royaume, puis construire le long d'une grande carte. Au fur et à mesure de leurs périples, le sort du royaume dépend de chaque décision qu'ils prendront.
Aujourd'hui, l'équipe a lancé la version 1.0 du jeu. Nous nous sommes entretenus avec Garrett Hau, directeur technique chez Zugalu Entertainment, et Jackie Li, concept artist en chef de l'équipe et infographiste technique, pour discuter des problèmes de performance rencontrés et de la façon dont la création d'un système de végétation personnalisé était essentielle à l'optimisation du jeu.
Conception d'un système de végétation personnalisé
Comme le jeu se déroule en pleine nature, il y a beaucoup d'arbres, d'herbe, de buissons, etc. Dans l'implémentation originale, l'herbe était très clairsemée, mais l'équipe souhaitait créer un vaste champ d'herbe luxuriant. « Pour plusieurs de nos biomes, comme celui des prairies, nous voulions couvrir le sol de végétation », explique-t-il. Pour cela, ils avaient besoin d'un système capable de gérer un grand nombre d'occurrences de végétation.
Pendant la majeure partie du projet, l'équipe a utilisé une solution tierce, qui a bien fonctionné, sauf qu'elle était fortement côté processeur, coûtait environ 3 millisecondes et le jeu était très goulot d'étranglement du processeur. Étant donné qu'ils avaient une configuration système assez faible, ils ont décidé de transférer la plupart des calculs sur le GPU et avaient besoin d'un autre type de solution.
« Nous avons décidé de créer notre propre système, tout en intégrant la nature du jeu basée sur des tuiles. Le système d'origine avait sa propre méthode de travail et certaines interactions au niveau des tuiles étaient trop coûteuses », explique-t-il.
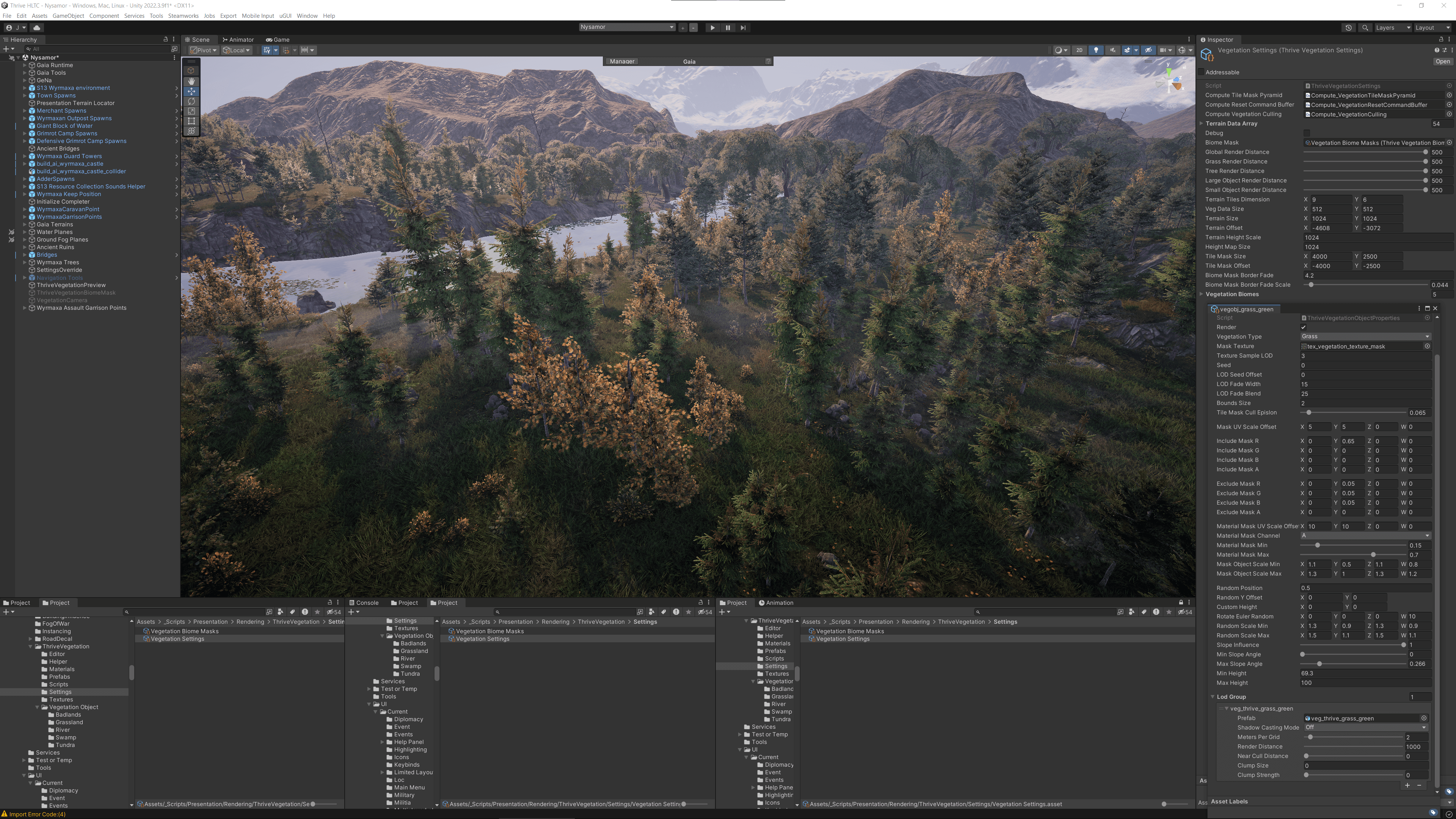
Ils voulaient corriger cela et pouvoir avoir une végétation plus dense. Comme ils calculaient sur le GPU dans leur nouveau système, ils avaient plus de marge de manœuvre pour les performances et la possibilité de créer une forêt florissante.
Un autre objectif clé était d'obtenir un masque par tuile. « Avant, quand on plaçait une route, on ne pouvait pas la masquer efficacement, de sorte que la végétation se développait juste au-dessus des routes », explique-t-il. Comme la méthode initiale reposait sur le processeur, chaque masque supplémentaire l'alourdissait, et ils voulaient que les routes, ou quoi que ce soit de réel, masquent l'herbe ou la végétation sans manger beaucoup de performances.
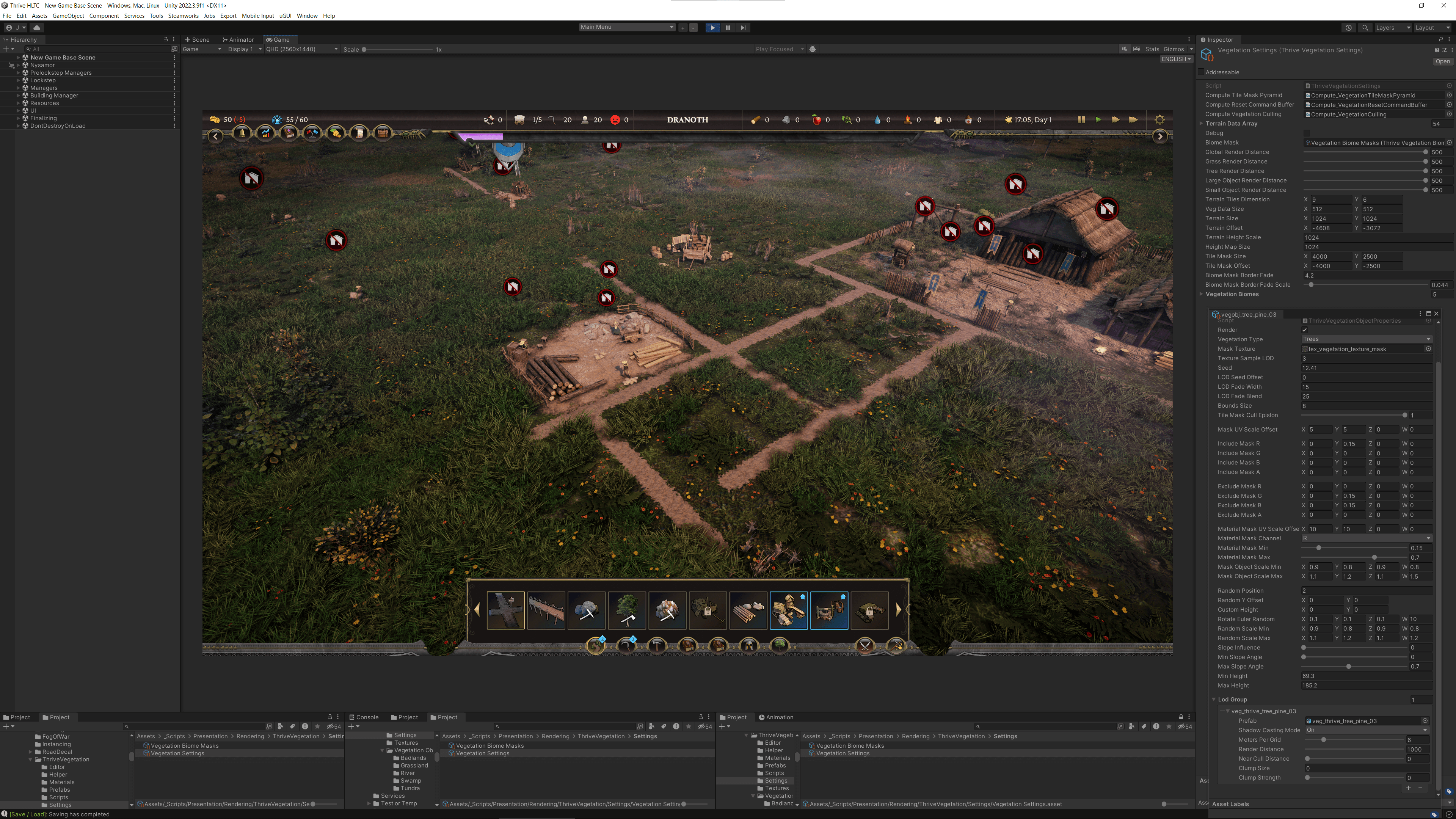
Exécution avec des compute shaders
L'équipe a également fait face à un goulot d'étranglement majeur lorsqu'il a fallu frayer la végétation sur sa grande carte. Étant donné que le jeu a une végétation abondante et une caméra très haute qui peut se déplacer rapidement sur la carte, il était important que la végétation fraye sans arrêter le joueur. Cela s'est avéré très difficile.
« Quand on regarde la végétation, on voit qu'on a besoin de frayer potentiellement des centaines de milliers d'instances. Nous avons donc choisi l'instanciation du GPU, qui a été conçue pour cet objectif précis, permettant potentiellement des millions d'instances », explique Li.
Pour commencer, l'équipe a préparé les données pour l'encodage du GPU. Ils avaient besoin de construire et d'alimenter le GPU en un ensemble de positions où ils souhaitaient faire naître leur végétation. La végétation n'interagit pas vraiment avec le côté processeur en dehors du masquage des tuiles, ils ont donc exécuté cela avec un compute shader. Comme le compute shader fonctionnait sur le GPU avant l'exécution de leurs shaders de rendu, ils préparaient les données dans leur compute shader, puis alimentaient les données résultantes pour l'instanciation. Ceci est également connu sous le nom d'instance indirecte.

L'étape suivante consistait à trouver comment utiliser les compute shaders, ce qui s'est avéré relativement facile. Li explique : « Un compute shader n'est qu'une opération multithread sur le GPU. Dans notre cas, chaque donnée d'instance peut être calculée individuellement sur chaque thread. Considérez-le comme le système de tâches Unity, mais sur le GPU. »
Lorsque vous travaillez dans un environnement multithread, la charge de travail de chaque thread doit être conçue de manière à ne pas dépendre des exécutions dans d'autres threads pour maximiser les performances.
Li explique : « Par exemple, lorsque nous ajoutons des éléments aléatoires, nous utilisons des éléments comme le bruit de Perlin, le bruit de simplex ou les fonctions de hachage. La surface évaluée actuelle est également divisée en une grille uniforme, chaque fil fonctionnant à l'intérieur de chaque point de grille afin que nous n'ayons pas à nous inquiéter de la reproduction de plusieurs duplicatas de végétation les uns sur les autres. »
Le terrain n'étant pas déformable à l'exécution, ils récupéraient ces données au début du développement et les passaient au GPU. Cela a permis de prétraiter les données de hauteur, notamment pour calculer la pente à chaque position de hauteur, afin que la végétation puisse être personnalisée pour suivre le contour du terrain.
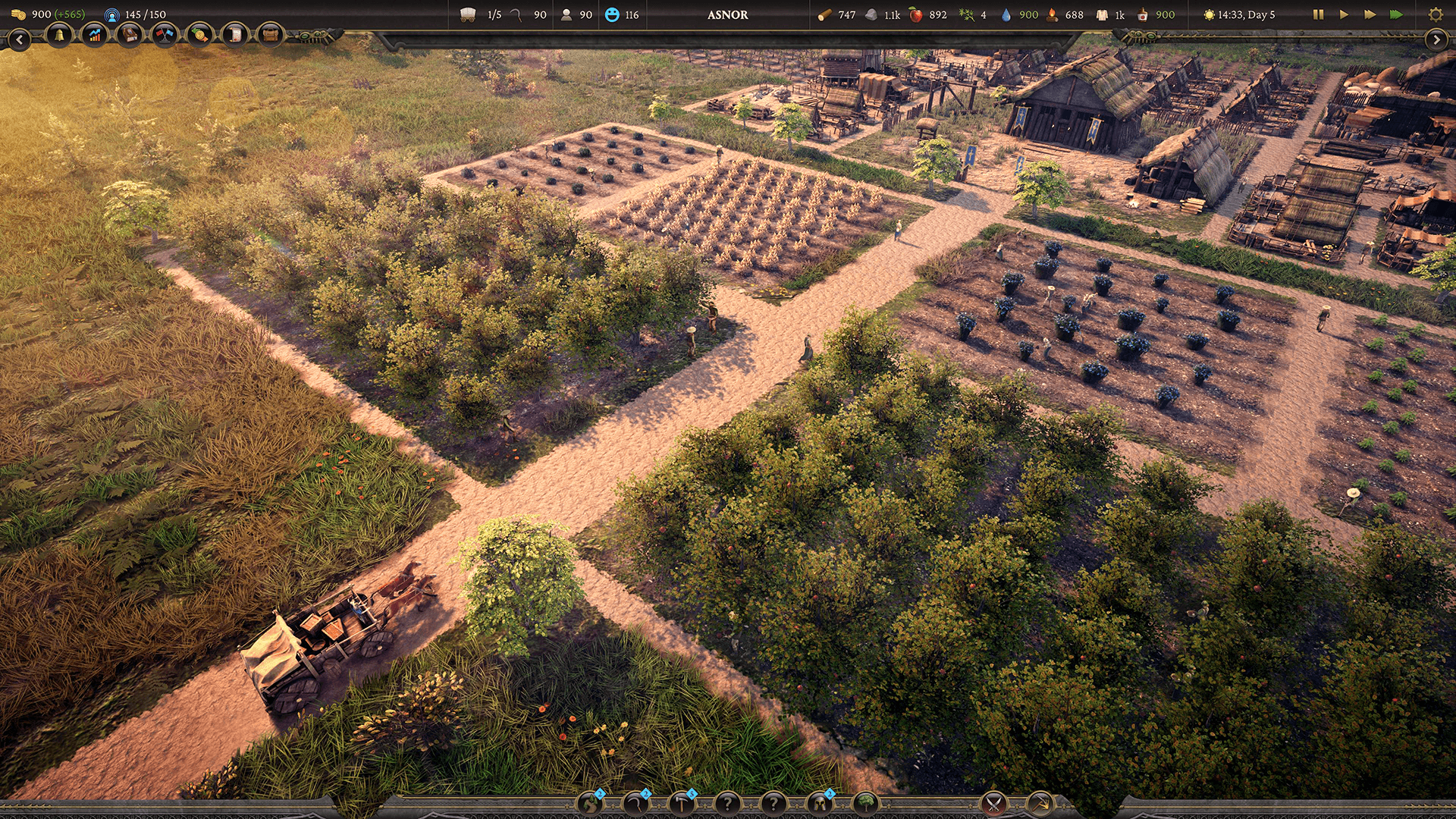
Consolidation des compute shaders
Bien que l'équipe utilisait des compute shaders, elle a dû en exécuter beaucoup pour obtenir les données qu'elle souhaitait. Comme pour les requêtes, moins c'est mieux. Ils cherchaient à réduire le nombre de commandes du GPU en éliminant la moitié des appels de répartition, puis en combinant le transfert de données du processeur au GPU en un seul appel API.
« Notre système de végétation est composé de nombreux types de végétation différents, chaque type de végétation nécessitant une répartition informatique », explique Li. « Avec 50 végétations, cela ferait 50 expéditions, chacune avec n-nombre de fils. »
L'objectif de chaque thread était de calculer une position d'instance, avec d'autres données, mais il était également très possible qu'un thread calcule une position gommée, soit en étant une position masquée, soit en dehors du tronc de caméra, auquel cas les données ne sont pas ajoutées à la gamme d'instances qui est ensuite utilisée pour dessiner la végétation.
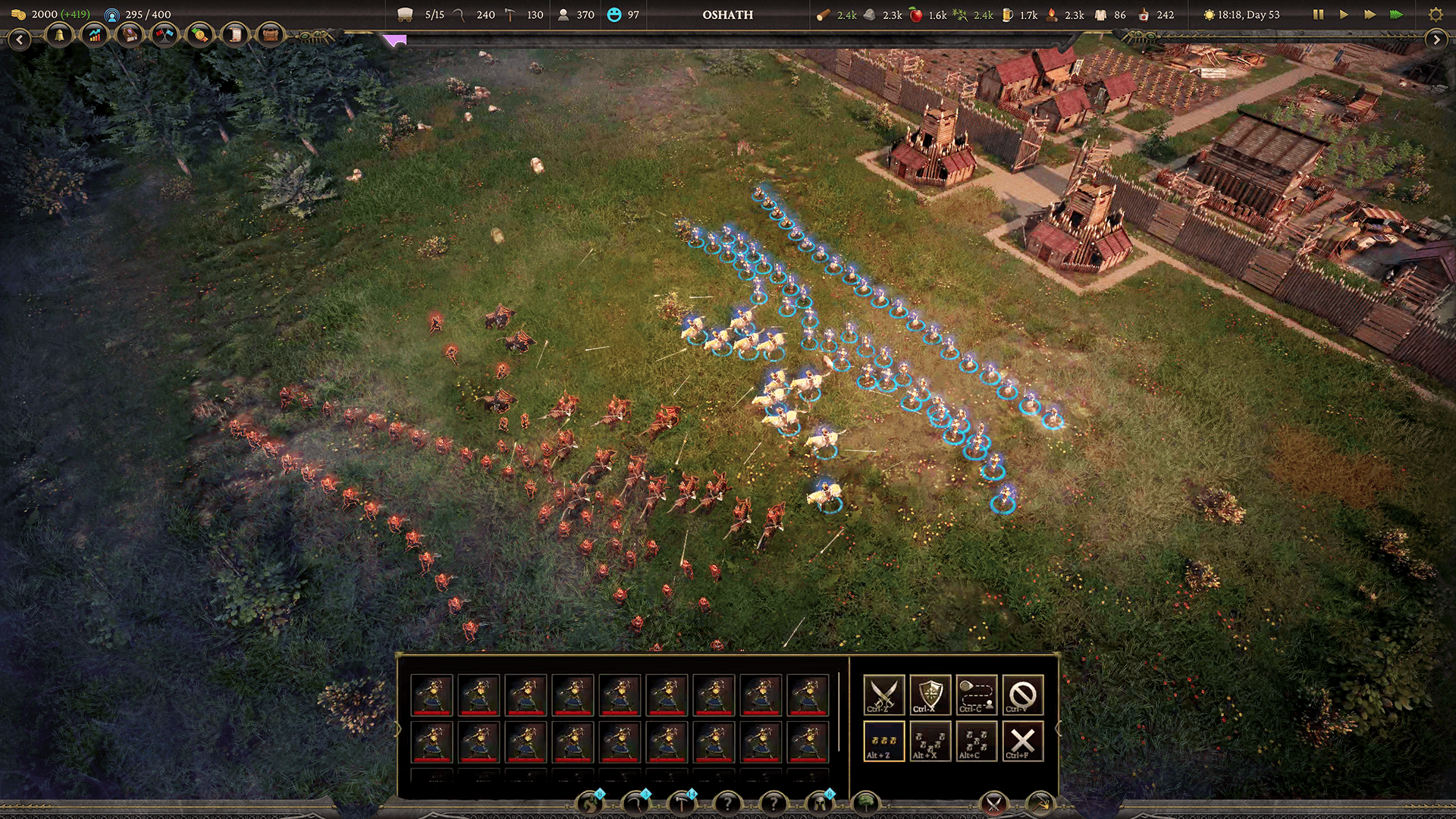
Puisqu'un thread peut s'ajouter ou non au tableau, nous avons utilisé une forme de liste sécurisée par thread, comme la structure de données, où nous avons ajouté la valeur valide à la liste. Le HLSL fournit cette fonctionnalité sous la forme d'un tampon d'ajout. « L'utilisation d'un tampon d'ajout a un petit inconvénient », explique Li. « J'ai dû exécuter des commandes gpu supplémentaires pour obtenir le nombre d'éléments ajoutés et aussi pour effacer ce nombre afin que le tampon d'ajout puisse être réutilisé. »
Cependant, le compute shader fournissait une variable pratique appelée groupshared, qui permettait une communication de thread à thread. Combinée à la fonction Interlocked, elle permettait à chaque envoi de garder une trace d'un compteur d'index global, ce qui permettait d'emballer étroitement les données d'instance valides et de mettre à jour les commandes de tirage indirect dans le même appel d'envoi qui calculait la position de l'instance.
Lors de l'envoi des données du processeur, l'équipe s'exposait initialement à une pénalité de performance. Ils ont dû mettre à jour les propriétés des shaders pour les différents types de végétation, qui changeaient d'image à image.
« À l'origine, j'envoyais les données séparément, ce qui donnait lieu à 50 commandes SetData() », explique Li. « Cependant, comme le type de données sous-jacent était le même, nous avons regroupé toutes les données dans un tampon, puis fourni à chaque type de végétation un indice de décalage dans ce tampon. Cela ne permettait qu'une seule commande SetData(). »
L'équipe estime de manière prudente qu'elle a économisé 0,1 milliseconde de temps processeur, ce qui représente 20 % du total de 0,5 milliseconde.
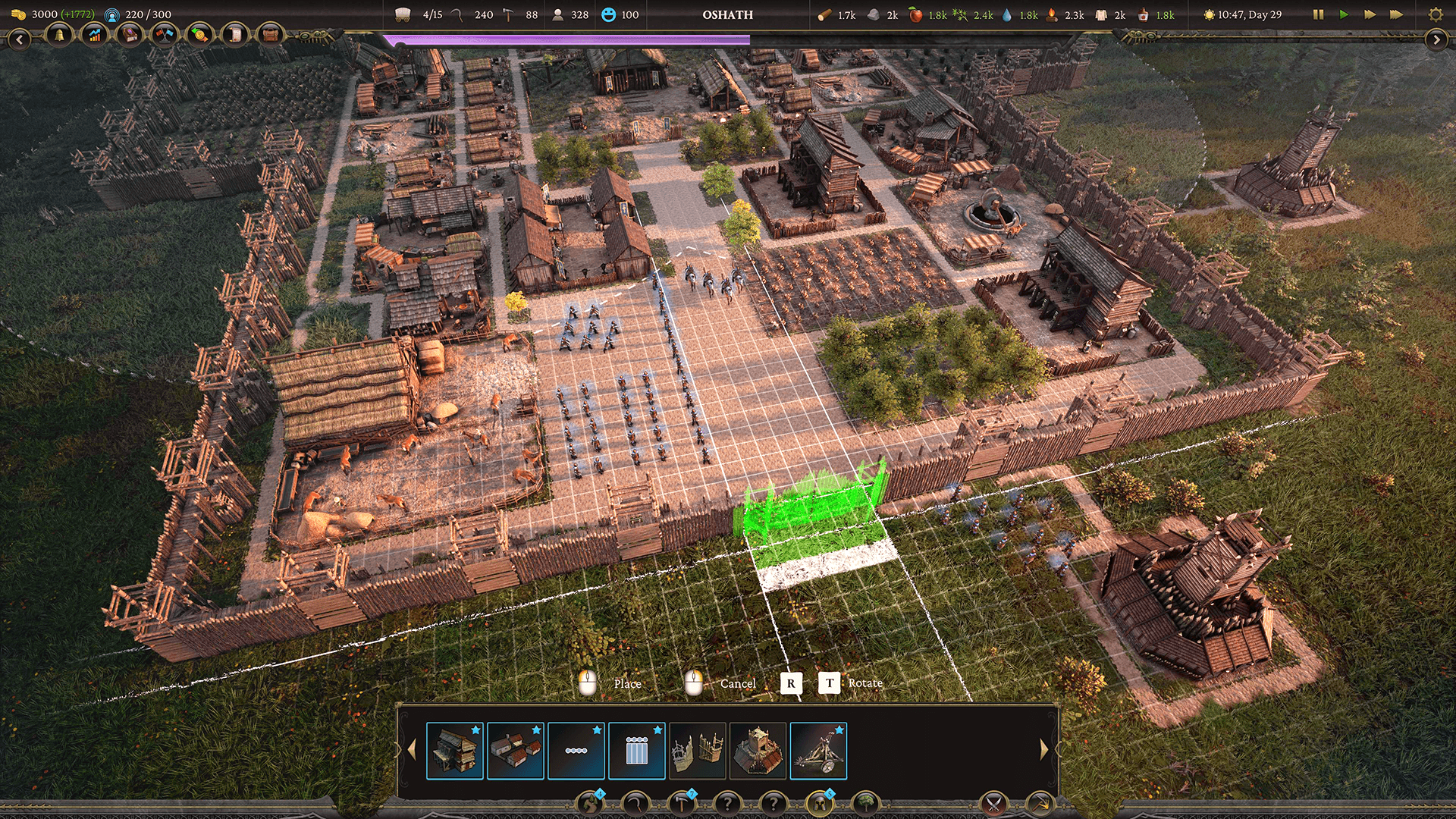
Envoi de données de tuiles du processeur vers le GPU
Comme la carte était très grande, environ 10 millions de tuiles, l'équipe a eu du mal à saisir les données des tuiles du processeur vers le GPU. « Essayer d'envoyer des millions de tuiles par image au GPU allait être très coûteux, car cela représente beaucoup de données à envoyer. Nous devions être en mesure d'envoyer un sous-ensemble de données juste assez pour occuper l'écran », explique Hau.
Ils ont utilisé le système de tâches de Unity pour cela. Cela les a aidés pour le CPU et a fourni un moyen multithread de capturer les données et de les envoyer vers le GPU. Hau explique que : « Lorsqu'il s'agit de sortir des données d'une gamme, c'est une charge de travail parfaite qui peut être accélérée par le système de tâches. »
Chaque thread peut être exécuté pour saisir un segment de données, qui est ensuite copié vers un tableau de destination. En même temps, ils ont converti les données 16 bits originales en données 32 bits emballées utilisées dans le shader de calcul.
L'équipe a également appliqué le compilateur Burst aux données du système de tâches pour créer un code optimisé. « Le compilateur Burst améliore considérablement les performances multithread. Une fois l'attribut activé, il est rapidement passé de plus d'une milliseconde à moins de 0,3 milliseconde. C'était très impressionnant d'ajouter une seule ligne de code », déclare Hau.
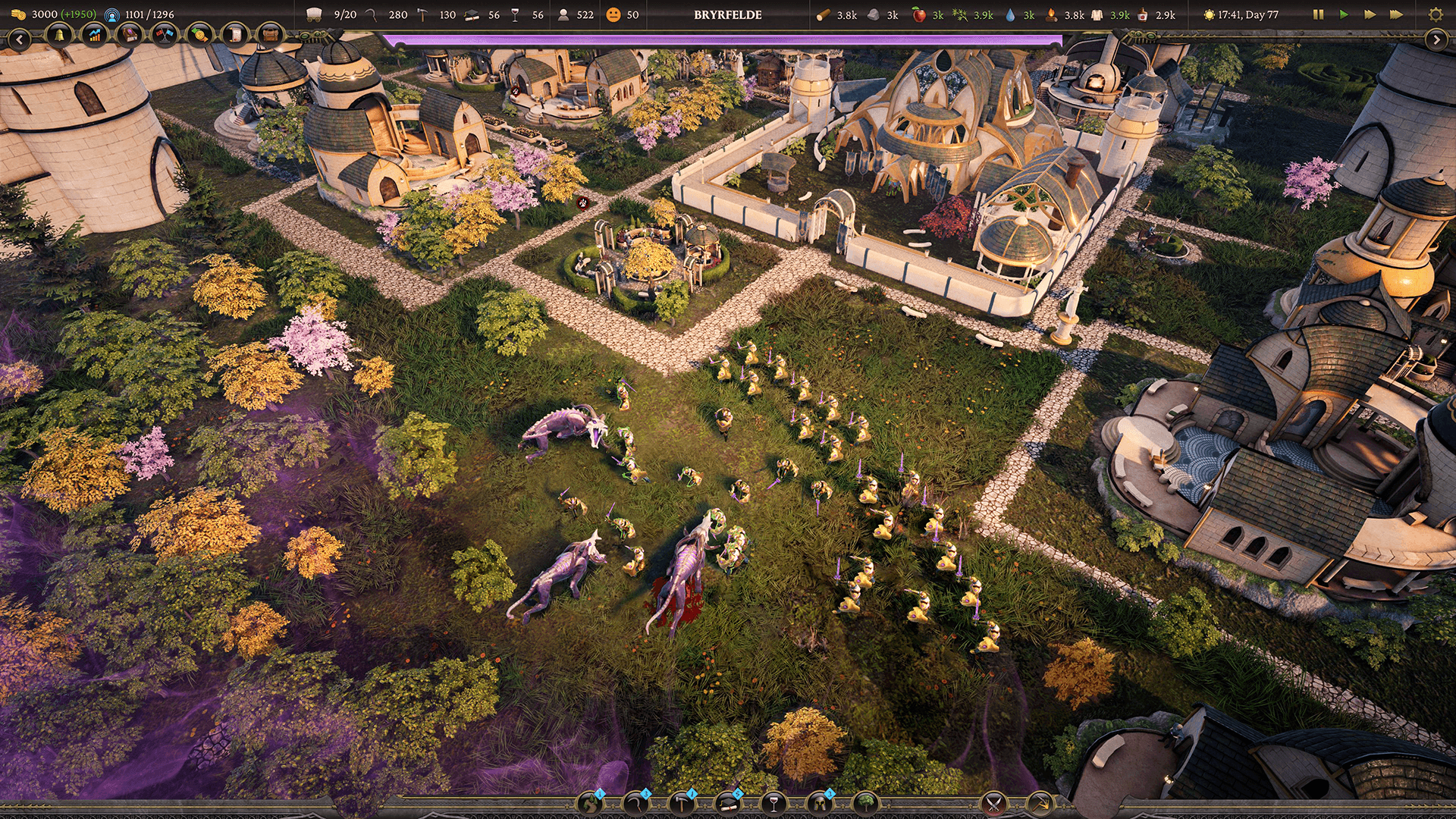
Bien que l'équipe ait constaté d'importantes victoires en matière d'optimisation, elle est également consciente que la performance du rendu de toute la végétation est à surveiller.
« Bien que nous soyons ravis de la réduction des performances, l'overdraw reste un problème que mon système ne résout pas », explique Li. « Nous devons garder cela à l'esprit. Néanmoins, nous sommes plus que satisfaits de la façon dont le jeu s'est déroulé. »
Pour en savoir plus sur les projets Made with Unity, consultez la page Ressources.