Optimizando el rendimiento con un sistema de vegetación personalizado para Thrive: Pesada es la corona

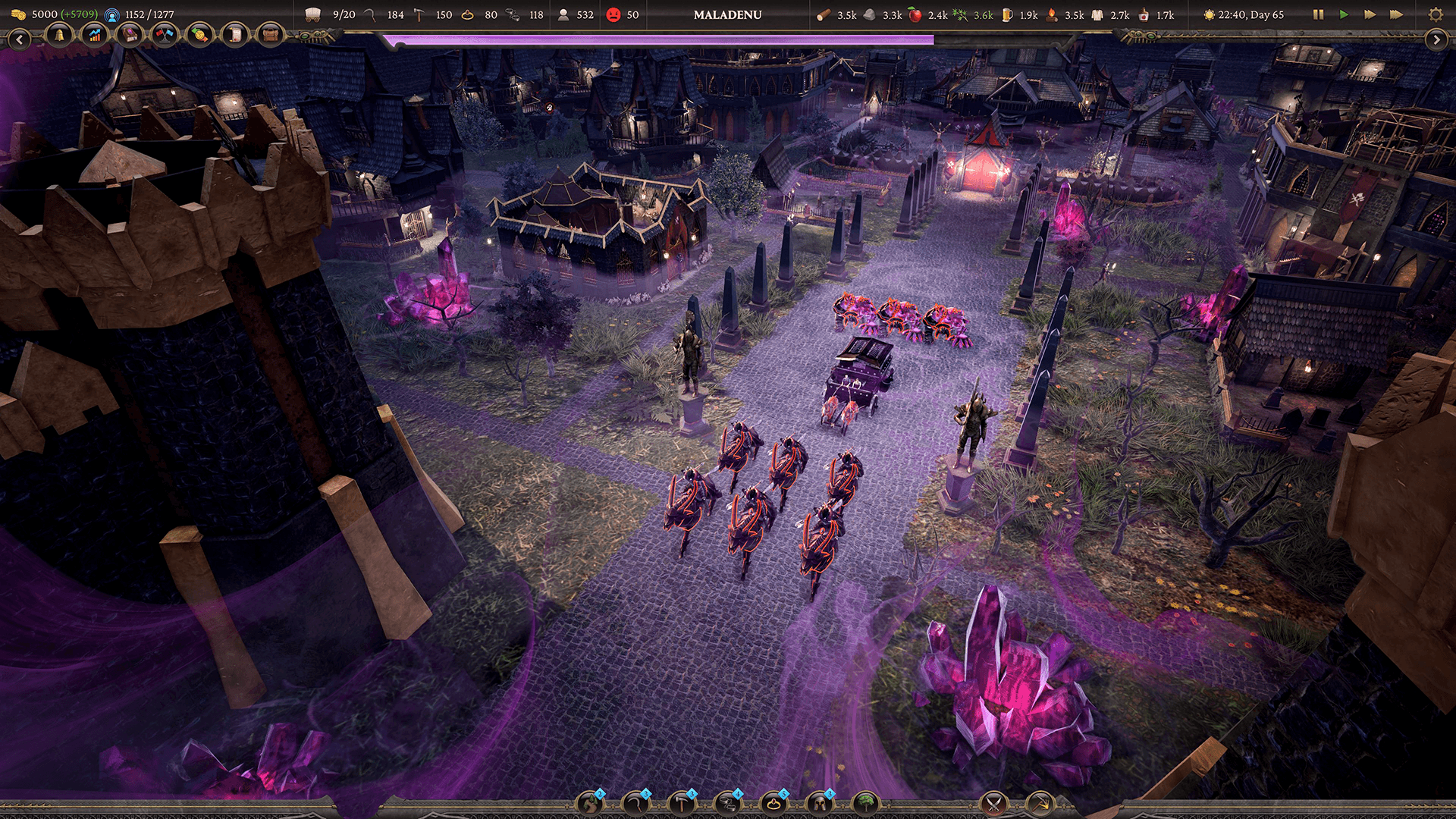
Zugalu Entertainment fue fundada en 2014 para crear juegos que combinan innovación, nostalgia y atractivo comercial. En los últimos 11 años, han lanzado títulos como Epic Food Fight, Technolites, Chronique des Silencieux y Sovereign Syndicate.
El 6 de noviembre de 2024, lanzaron Thrive: Heavy Lies the Crown en Acceso Anticipado, con excelentes críticas. El juego es un constructor de ciudades medievales con elementos de estrategia en tiempo real y funcionalidad multijugador cooperativo tanto para un jugador como para varios. Los jugadores pueden expandir estratégicamente su territorio y su reino, y luego construir a lo largo de un gran mapa. A medida que avanzan en sus viajes, el destino del reino depende de cada decisión que tomen.
Hoy, el equipo lanzó la versión 1.0 del juego. Nos sentamos con Garrett Hau, CTO de Zugalu Entertainment, y Jackie Li, la artista conceptual principal y artista técnica del equipo, para discutir los desafíos de rendimiento que encontraron y cómo construir un sistema de vegetación personalizado fue clave para la optimización del juego.
Construyendo un sistema de vegetación personalizado
Dado que el juego está ambientado en la naturaleza, hay muchos árboles, hierba, arbustos, etc. En la implementación original, la hierba era muy escasa, pero el equipo quería crear un campo expansivo y exuberante de hierba. “Para muchos de nuestros diferentes biomas, como el bioma de pradera, queríamos cubrir el suelo lleno de vegetación”, dice Hau. Para lograr eso, necesitaban un sistema que pudiera manejar un alto número de instancias de vegetación.
Durante la mayor parte del proyecto, el equipo estaba utilizando una solución de terceros, que funcionaba bien, excepto que era muy dependiente de la CPU, costaba alrededor de 3 milisegundos y el juego estaba muy limitado por la CPU. Dado que tenían un requisito de sistema bastante bajo, decidieron transferir la mayoría de los cálculos a la GPU y necesitaban un tipo diferente de solución.
“Decidimos hacer nuestro propio sistema y, al mismo tiempo, integrarlo con la naturaleza basada en mosaicos del juego. El sistema original tenía su propia forma de trabajar, y ciertas interacciones a nivel de cada baldosa eran demasiado costosas”, dice Hau.
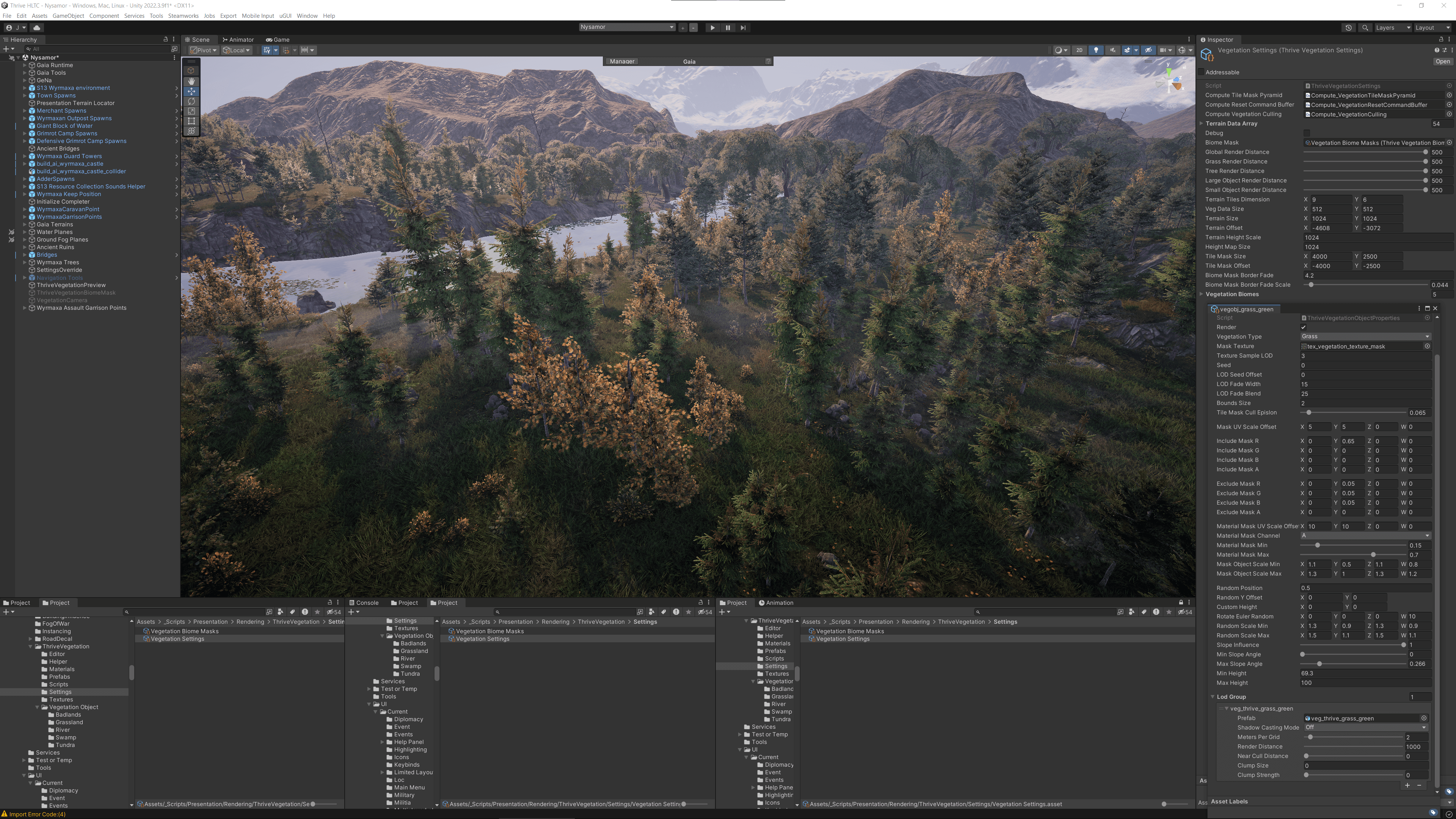
Querían solucionar eso y poder tener vegetación de mayor densidad. Dado que estaban calculando en la GPU en su nuevo sistema, tenían más margen de rendimiento y la oportunidad de crear un bosque floreciente.
Otro objetivo clave era obtener enmascaramiento por baldosa. “Antes, cuando colocabas una carretera, no se podía enmascarar de manera eficiente, así que la vegetación simplemente crecía sobre las carreteras,” dice Hau. Dado que el método inicial dependía de la CPU, cada máscara adicional la sobrecargaba, y querían que las carreteras, o cualquier cosa en realidad, enmascarara el césped o la vegetación sin consumir mucho rendimiento.
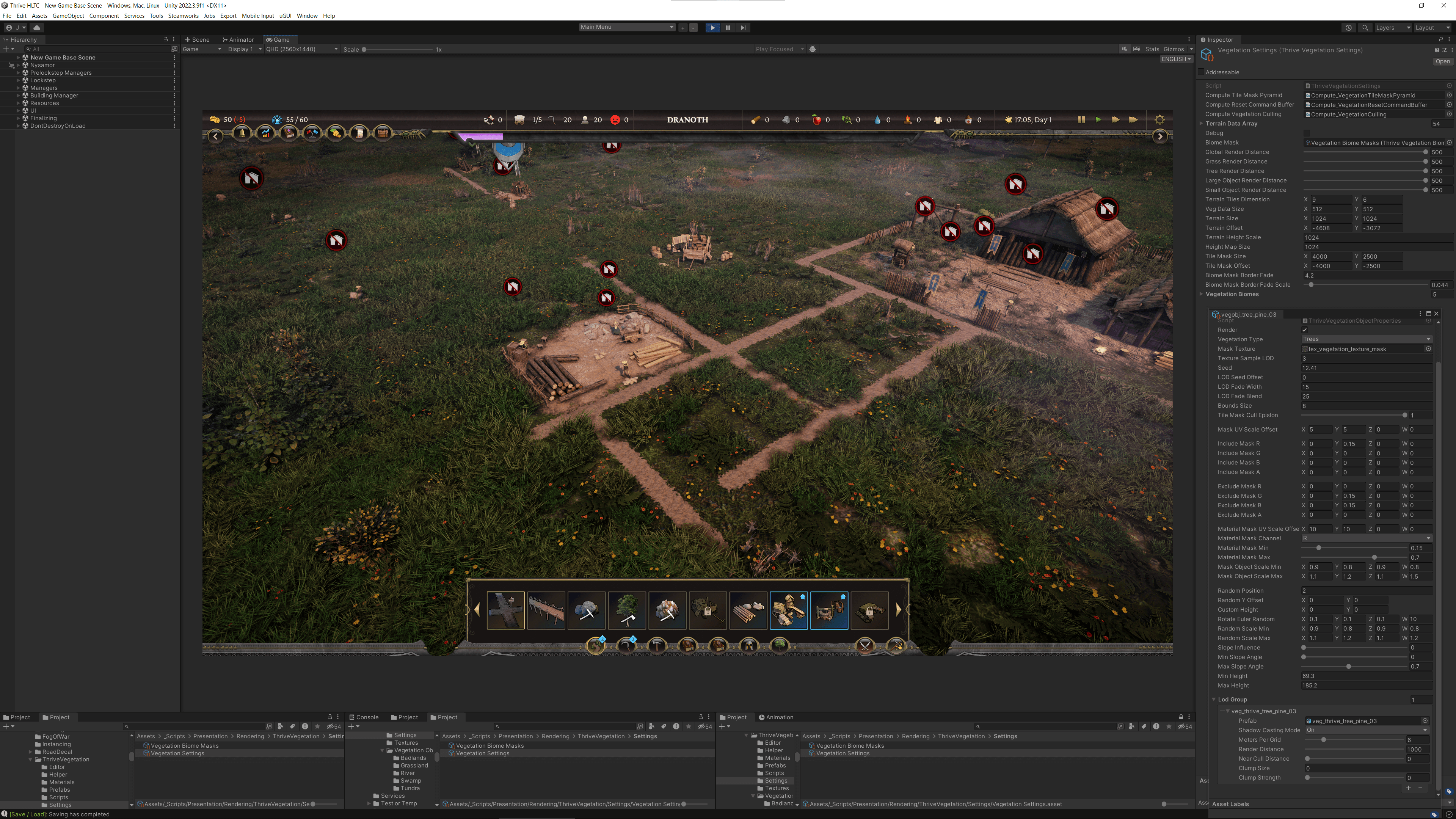
Ejecutando con sombreadores de cómputo
El equipo también experimentó un gran cuello de botella cuando se trataba de generar la vegetación en su gran mapa. Dado que el juego tiene una abundancia de vegetación y una cámara realmente alta que puede moverse rápidamente por el mapa, era importante que la vegetación apareciera sin detener al jugador. Esto resultó ser muy difícil.
“Cuando miras la vegetación, ves que necesitas generar potencialmente cientos de miles de instancias. Así que elegimos la instanciación en GPU, que fue diseñada para este propósito exacto, permitiendo potencialmente millones de instancias,” dice Li.
Para comenzar, el equipo preparó los datos para la instanciación en GPU. Necesitaban construir y alimentar a la GPU un arreglo de todas las posiciones donde querían generar su vegetación. La vegetación realmente no interactúa con el lado de la CPU fuera del enmascaramiento de baldosas, así que ejecutaron esto con un sombreador de cómputo. Dado que el shader de cómputo se ejecutó en la GPU antes de que se ejecutaran sus shaders de renderizado, prepararon los datos en su shader de cómputo y luego alimentaron los datos resultantes para la instanciación. Esto también se conoce como instancia indirecta.

El siguiente paso fue averiguar cómo usar los shaders de cómputo, lo cual resultó ser relativamente fácil. Li explica que, “Un shader de cómputo es solo una operación multihilo en la GPU. En nuestro caso, cada dato de instancia puede ser calculado individualmente en cada hilo. Piénsalo como el Sistema de Trabajo de Unity, pero en la GPU.”
Al trabajar en un entorno multihilo, la carga de trabajo de cada hilo debe ser diseñada de manera que no dependan de ejecuciones en otros hilos para maximizar el rendimiento.
Li dice, “Por ejemplo, al agregar aleatoriedad, usaríamos cosas como ruido de Perlin, ruido Simplex o funciones hash. La superficie evaluada actual también se divide en una cuadrícula uniforme, con cada hilo operando dentro de cada punto de la cuadrícula para que no tengamos que preocuparnos por generar vegetación duplicada una encima de la otra.”
Dado que el terreno no era deformable en tiempo de ejecución, recuperaron estos datos al inicio del desarrollo y los pasaron a la GPU. Esto permitió el preprocesamiento de los datos de altura, notablemente para calcular la pendiente en cada posición de altura, de modo que la vegetación pudiera personalizarse para seguir el contorno del terreno.
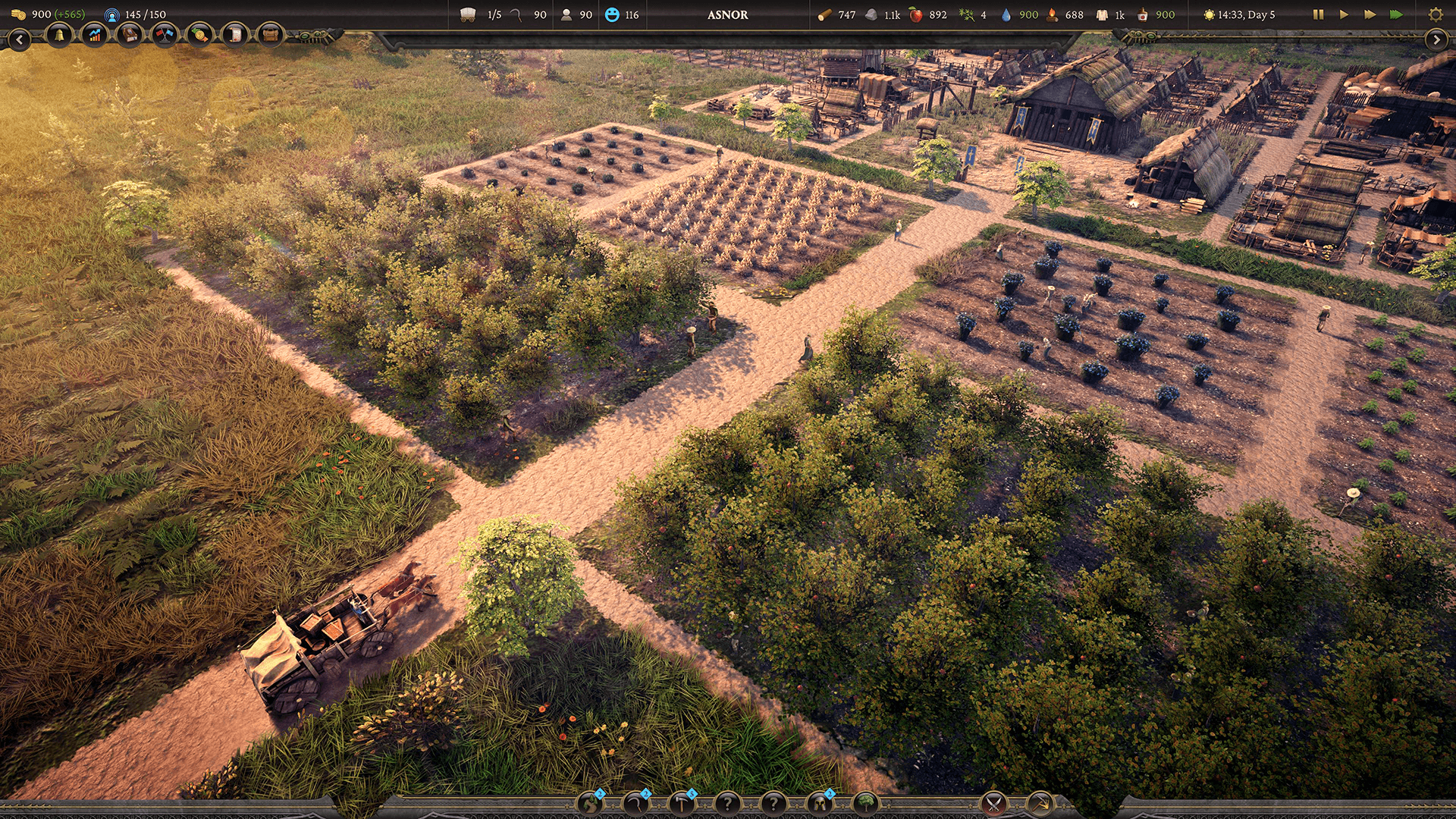
Consolidando shaders de cómputo
Aunque el equipo estaba usando shaders de cómputo, tuvieron que ejecutar muchos de ellos para obtener los datos que querían. De manera similar a las llamadas de dibujo, menos es mejor. Buscaban reducir el número de comandos de GPU eliminando la mitad de las llamadas de despacho y luego combinando la transferencia de datos de la CPU a la GPU en una sola llamada a la API.
“Nuestro sistema de vegetación está compuesto por muchos tipos diferentes de vegetación, cada tipo de vegetación requiere un despacho de cómputo,” explica Li. “Con 50 vegetaciones, eso serían 50 despachos, cada uno con n número de hilos.”
El objetivo de cada hilo era calcular una posición de instancia, junto con algunos otros datos, pero también era muy posible que un hilo calculara una posición eliminada, ya sea por ser una posición enmascarada o fuera del frustrum de la cámara, en cuyo caso los datos no se añaden a la matriz de instancias que luego se utiliza para dibujar la vegetación.
Dado que un hilo puede o no añadir a la matriz, utilizamos alguna forma de lista segura para hilos como estructura de datos, donde añadimos el valor válido a la lista. HLSL proporciona convenientemente esta característica en forma de un búfer de adición. “Usar un búfer de adición tiene una pequeña desventaja”, dice Li. “Tuve que ejecutar comandos adicionales de GPU para obtener el conteo de elementos añadidos y también para limpiar ese conteo para que el búfer de adición pudiera ser reutilizado.”
Sin embargo, el sombreador de cómputo proporcionó una variable conveniente conocida como groupshared, que permitió la comunicación de hilo a hilo. Y eso, en combinación con la función Interlocked , permitió que cada despacho mantuviera un contador de índice global, permitiendo que los datos de instancia válidos se empaquetaran de manera compacta, y que los comandos de dibujo indirecto se actualizaran todo dentro de la misma llamada de despacho que estaba calculando la posición de instancia.
Al enviar los datos de la CPU, el equipo enfrentó inicialmente una penalización de rendimiento. Tuvieron que actualizar las propiedades del sombreador para los diferentes tipos de vegetación, que cambiaban de un fotograma a otro.
“Originalmente, estaba enviando los datos por separado, resultando en 50 comandos SetData()”, dice Li. “Sin embargo, dado que el tipo de datos subyacente era el mismo, consolidamos todos los datos en un solo búfer, y luego proporcionamos a cada tipo de vegetación un índice de desplazamiento en ese búfer. Esto permitió solo un comando SetData().”
El equipo estima de manera conservadora que ahorraron 0.1 milisegundos de tiempo de CPU, representando el 20% del total de 0.5 milisegundos.
Enviando datos de mosaico de la CPU a la GPU
Dado que el mapa era muy grande, aproximadamente 10 millones de mosaicos, el equipo luchó por obtener los datos de mosaico de la CPU a la GPU. “Intentar enviar millones de mosaicos por fotograma a la GPU iba a ser muy costoso porque es una gran cantidad de datos para enviar. Necesitábamos poder enviar un subconjunto de datos justo suficiente para ocupar la pantalla,” dice Hau.
Usaron el Sistema de Trabajo de Unity para lograr eso. Ayudó en el lado de la CPU y proporcionó una forma multihilo de obtener los datos y enviarlos a la GPU. Hau explica que, “Cuando se trata de obtener datos de un arreglo, es una carga de trabajo perfecta que puede ser acelerada por el Sistema de Trabajo.”
Cada hilo puede ejecutarse para obtener un segmento de datos, que luego se copia a un arreglo de destino. Al mismo tiempo, convirtieron los datos originales de 16 bits en datos empaquetados de 32 bits utilizados en el shader de cómputo.
El equipo también aplicó el Compilador Burst a los datos del Sistema de Trabajo para crear código optimizado. “El Compilador Burst mejoró significativamente el rendimiento multihilo. Una vez que puse el atributo allí, rápidamente pasó de más de un milisegundo a menos de 0.3 milisegundos. Fue muy impresionante por solo agregar una línea de código,” dice Hau.
Mientras el equipo experimentó grandes ganancias de optimización, también son conscientes de que el rendimiento de renderizar toda la vegetación es algo a tener en cuenta.
“Aunque estamos emocionados con el ahorro de rendimiento, el sobre-dibujo sigue siendo un problema que mi sistema no resuelve,” explica Li. “Necesitamos tener eso en mente. Sin embargo, estamos más que felices con cómo resultó el juego.”
Para leer más sobre proyectos hechos con Unity, visita la Página de Recursos.