텍스처 데이터 효율적으로 액세스하기


Unity 프로젝트에서 기본 텍스처 픽셀 데이터에 액세스하는 다양한 방법의 장단점에 대해 알아봅니다.
픽셀 데이터는 텍스처의 개별 픽셀 색상을 나타냅니다. Unity에서는 C# 스크립트로 픽셀 데이터를 읽거나 쓸 수 있는 다양한 메서드를 제공합니다.
이러한 메서드를 사용해 (플레이어의 프로필 사진에 디테일을 추가하는 등) 텍스처를 업데이트 또는 복제하거나, 오브젝트의 배치 위치를 결정하기 위해 월드 맵을 나타내는 텍스처를 읽는 등 특정한 방식으로 텍스처 데이터를 사용할 수 있습니다.
픽셀 데이터를 읽거나 쓰는 코드를 작성하는 방법에는 여러 가지가 있습니다. 데이터로 하려는 작업과 프로젝트가 요구하는 성능에 따라 적합한 방법을 선택하면 됩니다.
이 블로그의 내용과 함께 제공되는 샘플 프로젝트를 살펴보며 사용 가능한 API와 일반적인 성능 문제를 알아볼 수 있습니다. 이 블로그와 샘플 프로젝트를 이해하면 성능 기준을 만족하는 솔루션을 작성하거나 작업 중에 발생하는 성능 병목 현상을 해결하는 데 도움이 될 것입니다.
Unity는 대부분의 텍스처 타입에 두 개의 픽셀 데이터 사본을 저장합니다. 하나는 렌더링에 필요하며 GPU 메모리에 저장되고, 다른 하나는 CPU 메모리에 저장됩니다. 후자는 선택 사항이며 이를 통해 CPU에서 픽셀 데이터를 읽고, 쓰고, 조작할 수 있습니다. CPU 메모리에 픽셀 데이터의 사본이 저장되어 있는 텍스처를 읽기 가능 텍스처라고 합니다. 참고로 RenderTexture는 GPU 메모리에만 있습니다.
대부분의 하드웨어에서 CPU와 GPU는 서로 다른 메모리를 사용합니다. 부분적으로 메모리를 공유하는 형태의 기기도 있지만 이 블로그는 CPU는 메인보드에 연결된 RAM에만 직접 액세스할 수 있고, GPU는 자체 VRAM(비디오 RAM)에 의존하는 고전적인 PC 구성을 가정합니다. 이처럼 다른 환경으로 전송되는 데이터는 PCI 버스를 거쳐야 하므로 동일한 타입의 메모리 내에서 데이터를 전송하는 것보다 느립니다. 이 과정에서 소요되는 비용 때문에 프레임당 전송되는 데이터의 양을 제한해야 하기도 합니다.
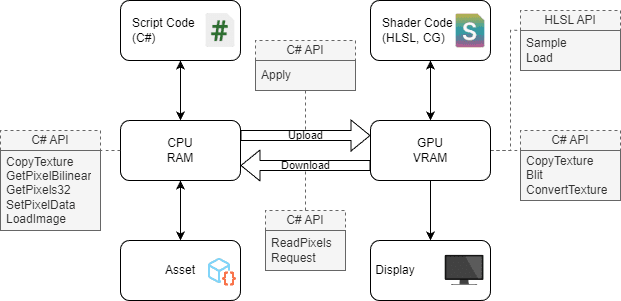
셰이더 텍스처의 샘플링은 가장 일반적인 GPU 픽셀 데이터 작업입니다. 텍스처 간에 복사하거나 셰이더를 사용해 텍스처로 렌더링하는 방식으로 이 데이터를 변경할 수 있습니다. 이 모든 작업은 GPU에서 빠르게 수행할 수 있습니다.
데이터 액세스 방식이 더 유연한 CPU에서 텍스처 데이터를 조작하는 것이 바람직한 경우도 있습니다. CPU 픽셀 데이터 작업은 해당 데이터의 CPU 사본에서만 실행되므로 읽기 가능 텍스처가 필요합니다. 업데이트된 픽셀 데이터를 셰이더에서 샘플링하려면 먼저 Apply를 호출해 CPU에서 GPU로 복사해야 합니다. 사용되는 텍스처와 작업 복잡도에 따라 CPU 작업을 고수하는 편이 더 빠르고 간단할 수 있습니다(예: 여러 2D 텍스처를 Texture2DArray 에셋에 복사).
Unity API는 텍스처 데이터 액세스 또는 처리를 위한 여러 가지 메서드를 제공합니다. 일부 작업은 GPU와 CPU 사본이 모두 존재하는 경우 양쪽에서 실행됩니다. 따라서 이 메서드는 텍스처의 읽기 가능 여부에 따라 성능이 달라집니다. 다양한 메서드로 동일한 결과를 얻을 수 있으나 각 메서드는 성능과 사용 편의적 특성에서 차이를 보입니다.
최적의 솔루션을 결정하려면 다음 질문에 답해 보세요.
- GPU가 CPU보다 더 빠르게 계산할 수 있나요?
- 프로세스가 텍스처 캐시에 얼마나 많은 부하를 주나요? 예를 들어 밉맵을 사용하지 않고 다수의 고해상도 텍스처를 샘플링하면 GPU 속도가 느려질 수 있습니다.
- 프로세스에 무작위 쓰기 텍스처가 필요한가요? 아니면 색상 또는 뎁스 연결부로 출력될 수 있나요? 텍스처의 무작위 픽셀에 쓰기 작업을 하려면 캐시를 자주 플러시해야 하므로 프로세스가 느려집니다.
- 프로젝트에 이미 GPU 병목 현상이 있나요? GPU가 CPU보다 빠르게 프로세스를 실행할 수 있더라도 GPU가 프레임 시간 예산을 초과하지 않으면서 더 많은 작업을 처리할 수 있나요?
- GPU와 CPU 메인 스레드가 모두 프레임 시간 제한에 근접하다면 CPU 워커 스레드가 프로세스의 느린 부분을 수행할 수도 있습니다.
- 결과를 계산하거나 처리하기 위해 GPU를 대상으로 얼마나 많은 데이터를 업로드하거나 다운로드해야 하나요?
- 필요한 대역폭을 줄이기 위해 셰이더 또는 C# 잡이 데이터를 더 작은 포맷으로 패킹할 수 있나요?
- RenderTexture를 더 작은 해상도 버전으로 다운샘플링해 대신 다운로드할 수 있나요?
- 프로세스를 청크 단위로 수행할 수 있나요? 대량의 데이터를 동시에 처리해야 하는 경우, GPU의 메모리가 작업을 처리하기에 부족할 위험이 있습니다.
- 결과가 얼마나 빨리 나와야 하나요? 계산이나 데이터 전송을 비동기적으로 수행하고 나중에 처리할 수 있나요? 한 프레임에서 너무 많은 작업을 수행하면 GPU가 프레임별 실제 그래픽스를 렌더링할 시간이 부족할 수 있습니다.
기본적으로 프로젝트에 임포트하는 텍스처 에셋은 읽기 불가 텍스처이며 스크립트로 생성된 텍스처는 읽기 가능 텍스처입니다.
읽기 가능 텍스처는 CPU RAM에 픽셀 데이터의 사본을 저장해야 하므로 읽기 불가 텍스처에 비해 두 배 많은 메모리를 사용합니다. 텍스처는 필요할 때만 읽기 가능 상태로 만들어야 하며 CPU에서 데이터 작업을 완료하면 읽기 불가 상태로 만들어야 합니다.
프로젝트의 텍스처 에셋이 읽기 가능 상태인지 확인하고 수정하려면 Texture Import Settings의 Read/Write Enabled 옵션이나 TextureImporter.isReadable API를 사용하세요.
텍스처를 읽기 불가 상태로 만들려면 makeNoLongerReadable 파라미터를 ‘true’로 설정한 상태로 해당 텍스처의 Apply 메서드를 호출합니다(예: Texture2D.Apply 또는 Cubemap.Apply). 읽기 불가 텍스처는 읽기 가능 텍스처로 되돌릴 수 없습니다.
편집 및 플레이 모드에서는 에디터에서 모든 텍스처를 읽을 수 있습니다. 텍스처를 읽기 불가 상태로 만들기 위해 Apply를 호출하면 isReadable 값이 업데이트되며 CPU 데이터 액세스가 제한됩니다. 그러나 일부 Unity 프로세스는 내부 CPU 데이터가 유효하다는 것을 확인하므로 텍스처가 읽기 가능 상태인 것처럼 작동합니다.

성능은 텍스처 데이터의 액세스 방식에 따라 큰 차이를 보이며 특히 CPU에서는 그 차이가 크게 나타납니다(낮은 해상도는 차이가 덜한 편). GitHub의 Unity 텍스처 액세스 API 예시 저장소에는 텍스처 데이터 액세스 또는 조작을 위한 여러 API별 성능 차이를 확인할 수 있는 예시가 다양하게 준비되어 있습니다. UI에는 메인 스레드 CPU 타이밍만 표시됩니다. 성능을 극대화하기 위해 버스트 및 잡 시스템 등의 DOTS 기능이 사용되기도 합니다.
GitHub 저장소에는 다음과 같은 예시가 있습니다.
- SimpleCopy: 한 텍스처의 모든 픽셀을 다른 텍스처에 복사
- PlasmaTexture: 프레임마다 CPU에서 업데이트되는 플라즈마 텍스처
- TransferGPUTexture: GPU의 모든 픽셀을 텍스처에서 RenderTexture로 전송(다른 크기나 포맷으로 복사)
GitHub의 예시에서 측정한 성능 수치를 아래에서 볼 수 있습니다. 이 수치는 아래의 권장 사항을 뒷받침하기 위해 제시되었습니다. 3.7 GHz 8-core Xeon® W-2145 CPU 및 RTX 2080이 장착된 시스템의 플레이어 빌드에서 측정된 수치입니다.
아래는 텍스처 크기가 2,048인 SimpleCopy.UpdateTestCase의 CPU 시간 중간값을 나타냅니다.
Graphics 메서드는 메인 스레드에서 거의 즉시 완료됩니다. 작업을 RenderThread에 푸시하여 나중에 GPU에서 실행되기 때문입니다. 다음 프레임이 렌더링되는 시점에 결과가 준비됩니다.
결과
- 1,326ms – foreach(mip) for(x in width) for(y in height) SetPixel(x, y, GetPixel(x, y, mip), mip)
- 32.14ms – foreach(mip) SetPixels(source.GetPixels(mip), mip)
- 6.96ms – foreach(mip) SetPixels32(source.GetPixels32(mip), mip)
- 6.74ms – LoadRawTextureData(source.GetRawTextureData())
- 3.54ms – Graphics.CopyTexture(readableSource, readableTarget)
- 2.87ms – foreach(mip) SetPixelData(mip, GetPixelData(mip))
- 2.87ms – LoadRawTextureData(source.GetRawTextureData())
- 0.00ms – Graphics.ConvertTexture(source, target)
- 0.00ms – Graphics.CopyTexture(nonReadableSource, target)
아래는 텍스처 크기가 512인 PlasmaTexture.UpdateTestCase의 CPU 시간 중간값을 나타냅니다.
예상외로 SetPixels32가 SetPixels보다 느린 것을 확인할 수 있습니다. 플라즈마 픽셀 계산의 플로트 기반 Color 결과를 바이트 기반 Color32 구조체로 전환해야 하므로 이런 현상이 발생합니다. SetPixels32NoConversion은 이 전환 과정을 건너뛰고 Color32 출력 배열에 기본값을 할당하므로 SetPixels보다 더 나은 성능을 발휘합니다. Unity가 수행하는 기본 색상 전환 및 SetPixels의 성능을 능가하려면 픽셀 계산 메서드를 수정해 직접 Color32 값을 출력하도록 해야 합니다. SetPixelData를 사용해 간단히 구현하는 것이 SetPixels 및 SetPixels32로 신중히 구현하는 것보다 대부분 더 나은 결과를 얻습니다.
결과
- 126.95ms – SetPixel
- 113.16ms – SetPixels32
- 88.96ms – SetPixels
- 86.30ms – SetPixels32NoConversion
- 16.91ms – SetPixelDataBurst
- 4.27ms – SetPixelDataBurstParallel
아래는 텍스처 크기가 8,196인 TransferGPUTexture.UpdateTestCase의 에디터 GPU 시간입니다.
- Blit – 1.584ms
- CopyTexture – 0.882ms
다양한 방법으로 픽셀 데이터에 액세스할 수 있습니다. 그러나 모든 메서드가 모든 포맷, 텍스처 타입, 사용 사례를 지원하지는 않으며 일부 메서드는 다른 메서드보다 실행에 더 오랜 시간이 걸립니다. 이 섹션에서는 권장하는 메서드를 살펴보고 다음 섹션에서는 주의해서 사용해야 하는 메서드를 알아봅니다.
CopyTexture는 한 텍스처에서 다른 텍스처로 GPU 데이터를 전송하는 가장 빠른 방법입니다. 포맷 전환은 일절 수행하지 않습니다. 영역의 너비 및 높이와 함께 소스 및 타겟 위치를 지정해 부분적으로 데이터를 복사할 수 있습니다. 두 텍스처가 모두 읽기 가능 상태라면 CPU 데이터의 복사 작업도 함께 수행되며, 이 메서드의 총 비용은 SetPixelData를 사용해 CPU만 복사하며 소스 텍스처에서 GetPixelData가 결과로 나올 때와 비슷해집니다.
Blit은 셰이더를 사용해 GPU 데이터를 RenderTexture에 전송하는 빠르고 강력한 메서드입니다. 사실상 이 메서드는 타겟 RenderTexture에 렌더링되도록 그래픽스 파이프라인 API 상태를 설정해야 합니다. 해상도와 무관한 설정 비용이 CopyTexture에 비해 적게 발생합니다. 이 메서드가 사용하는 기본 Blit 셰이더는 입력 텍스처를 타겟 RenderTexture로 렌더링합니다. 커스텀 머티리얼 또는 셰이더를 제공해 복잡한 텍스처 간 렌더링 프로세스를 정의할 수 있습니다.
GetPixelData 및 SetPixelData는 GetRawTextureData처럼 CPU 데이터만 조작할 때 사용할 수 있는 가장 빠른 메서드입니다. 두 메서드 모두 데이터를 재해석하는 데 사용할 템플릿 파라미터로 구조체 타입을 제공해야 합니다. 메서드 자체는 올바른 크기를 도출하는 데만 이 구조체가 필요하므로, 텍스처 포맷을 나타내는 커스텀 구조체를 정의하고 싶지 않은 경우 바이트를 사용해도 됩니다.
개별 픽셀에 액세스할 때는 쉽게 사용할 수 있도록 유틸리티 메서드가 있는 커스텀 구조체를 정의하면 좋습니다. 예를 들어 R5G5B5A1 포맷 구조체는 개별 채널을 바이트로 액세스하는 몇 개의 get/set 메서드와 ushort 데이터 멤버로 구성할 수 있습니다.
public struct FormatR5G5B5A1 { public ushort data; const ushort redOffset = 11; const ushort greenOffset = 6; const ushort blueOffset = 1; const ushort alphaOffset = 0; const ushort redMask = 31 << redOffset; const ushort greenMask = 31 << greenOffset; const ushort blueMask = 31 << blueOffset; const ushort alphaMask = 1; public byte red { get { return (byte)((data & redMask) >> redOffset); } } public byte green { get { return (byte)((data & greenMask) >> greenOffset); } } public byte blue { get { return (byte)((data & blueMask) >> blueOffset); } } public byte alpha { get { return (byte)((data & alphaMask) >> alphaOffset); } } }
위 코드는 R5G5B5A5A1 포맷의 픽셀을 나타내는 오브젝트를 구현한 예시입니다. 간결하게 표시하기 위해 각 프로퍼티의 setter는 생략했습니다.
SetPixelData를 사용해 데이터의 전체 밉 레벨을 타겟 텍스처에 복사할 수 있습니다. GetPixelData는 Unity의 내부 CPU 텍스처 데이터의 한 밉 레벨을 실제로 가리키는 NativeArray를 반환합니다. 이를 통해 복사 작업 없이 해당 데이터를 직접 읽고 쓸 수 있습니다. 다만 GetPixelData가 반환하는 NativeArray는 MonoBehaviour.Update처럼 GetPixelData를 호출하는 사용자 코드가 Unity에 컨트롤을 반환할 때까지만 유효하다는 점에 유의해야 합니다. 프레임 간에 GetPixelData의 결과를 저장하는 대신, 데이터를 액세스하려는 모든 프레임마다 GetPixelData에서 올바른 NativeArray를 가져와야 합니다.
Apply 메서드는 CPU 데이터가 GPU에 업로드된 후에 반환됩니다. 업로드 후 CPU 데이터의 메모리를 비우기 위해 가능하다면 makeNoLongerReadable 파라미터를 ‘true’로 설정해야 합니다.
RequestIntoNativeArray 및 RequestIntoNativeSlice 메서드는 지정된 텍스처에서 사용자가 제공한 NativeArray 조각으로 GPU 데이터를 비동기적으로 다운로드합니다.
이 메서드를 호출하면 요청된 데이터의 다운로드가 완료되었는지 나타내는 요청 핸들이 반환됩니다. 소수의 포맷만 한정적으로 지원하므로 FormatUsage.ReadPixels와 함께 SystemInfo.IsFormatSupported를 사용해 포맷 지원 여부를 확인하세요. AsyncGPUReadback 클래스에도 NativeArray를 할당해 주는 Request 메서드가 존재합니다. 이 작업을 반복해야 하는 경우, 재사용할 NativeArray를 대신 할당해 성능을 개선할 수 있습니다.
성능에 심각한 영향을 줄 수 있으므로 주의해서 사용해야 하는 몇 가지 메서드가 있습니다. 관련해서 자세히 살펴보겠습니다.
다음 메서드는 다양한 복잡도의 픽셀 포맷 전환을 수행합니다. Pixels32 배리언트가 가장 준수한 성능을 보이지만, 텍스처의 기본 포맷이 Color32 구조체와 완벽하게 부합하지 않는 경우에는 Pixels32도 포맷 전환을 수행할 수 있습니다. 다음 메서드를 사용할 때는 픽셀 수가 늘어날수록 성능에 미치는 영향이 다양한 수준으로 크게 증가한다는 점을 기억하세요.
GetRawTextureData 및 LoadRawTextureData는 모든 밉 레벨의 원시 픽셀 데이터가 담긴 배열을 차례로 작업하는 Texture2D 전용 메서드입니다. 레이아웃은 가장 큰 밉에서 가장 작은 밉 순이며 각 밉은 ‘너비’ 픽셀 값의 ‘높이’ 양에 해당합니다. 빠른 CPU 데이터 액세스를 제공하는 함수입니다. GetRawTextureData는 템플릿화되지 않은 배리언트가 데이터 사본을 반환하는 의외의 문제가 있긴 합니다. 이 경우는 약간 더 느리고 Unity가 관리하는 기본 버퍼의 직접적인 조작을 허용하지 않습니다. GetPixelData는 이러한 문제가 없으며, 사용자 코드가 Unity에 컨트롤을 반환할 때까지 유효하고 기본 버퍼를 가리키는 NativeArray만 반환할 수 있습니다.
ConvertTexture를 사용하면 소스와 대상 텍스처의 크기 또는 포맷이 서로 다를 때도 텍스처 간에 GPU 데이터를 전송할 수 있습니다. 이 전환 프로세스는 상황에 따라 효율적으로 작동하지만 비용이 저렴하진 않습니다. 내부 프로세스는 다음과 같습니다.
1. 대상 텍스처가 일치하는 임시 RenderTexture를 할당합니다.
2. 소스 텍스처에서 임시 RenderTexture로 Blit을 수행합니다.
3. Blit 결과를 임시 RenderTexture에서 대상 텍스처로 복사합니다.
다음 질문에 답하며 이 메서드가 본인의 사용 사례에 적합한지 확인해 보세요.
- 이 전환을 꼭 수행해야 하나요?
- 임포트 시 소스 텍스처가 타겟 플랫폼에 적합한 크기/포맷으로 생성된다고 확신할 수 있나요?
- 동일한 포맷을 사용하도록 프로세스를 수정하여 한 프로세스 결과를 곧바로 다른 프로세스의 입력으로 사용하도록 만들 수 있나요?
- RenderTexture를 대상으로 대신 생성하고 사용할 수 있나요? 그렇게 하면 대상 RenderTexture에 대한 단일 Blit으로 전환 프로세스가 단축될 수 있습니다.
ReadPixels 메서드는 활성 RenderTexture(RenderTexture.active)에서 Texture2D의 CPU 데이터로 GPU 데이터를 동기적으로 다운로드합니다. 이렇게 하면 렌더링 작업의 출력을 저장하거나 처리할 수 있습니다. 소수의 포맷만 한정적으로 지원하므로 FormatUsage.ReadPixels와 함께 SystemInfo.IsFormatSupported를 사용해 포맷 지원 여부를 확인하세요.
GPU에서 데이터를 다시 다운로드하는 프로세스는 속도가 느립니다. 다운로드를 시작하려면 ReadPixels는 GPU가 이전 작업을 모두 완료할 때까지 기다려야 합니다. 요청된 데이터가 사용 가능할 때까지 반환이 이루어지지 않아 성능이 저하되므로 이 메서드는 사용하지 않는 것이 좋습니다. GPU 데이터가 현재 활성 상태로 설정된 RenderTexture에 있어야 하므로 사용성에도 문제가 있습니다. 앞서 설명한 AsyncGPUReadback 메서드를 사용하는 것이 사용성과 성능 측면에서 모두 바람직합니다.
ImageConversion 클래스는 Texture2D와 여러 이미지 파일 포맷을 서로 전환하는 메서드가 있습니다. LoadImage를 사용하면 JPG, PNG, EXR(2023.1부터 지원) 데이터를 Texture2D로 로드해 GPU로 업로드할 수 있습니다. 로드된 픽셀 데이터는 Texture2D의 원본 포맷이 무엇인지에 따라 즉시 압축될 수 있습니다. 다른 메서드는 Texture2D 또는 픽셀 데이터 배열을 JPG, PNG, TGA, EXR 데이터 배열로 전환할 수 있습니다.
특별히 빠른 메서드는 아니지만 일반적인 이미지 파일 포맷으로 픽셀 데이터를 전달해야 하는 프로젝트에서 유용할 수 있습니다. 디스크에서 사용자 아바타를 로드해 네트워크를 통해 다른 플레이어와 공유하는 경우를 일반적인 사용 사례로 들 수 있습니다.
다양한 리소스를 통해 Unity의 그래픽스 최적화, 관련 주제, 베스트 프랙티스에 대해 자세히 알아볼 수 있습니다. 우선 기술 자료의 그래픽스 성능 및 프로파일링 섹션부터 살펴보시기 바랍니다.
Unity 게임 프로파일링 완벽 가이드, 모바일 게임 성능 최적화, 콘솔 및 PC 게임 성능 최적화 같은 고급 사용자를 위한 기술 전자책을 참조하는 것도 좋습니다.
Unity 사용법 소개 허브에서 더 많은 고급 베스트 프랙티스를 찾아볼 수 있습니다.
다음은 기억해야 하는 핵심 요약입니다.
- 텍스처를 조작할 때는 최적의 성능을 위해 GPU에서 어떤 작업을 수행할 수 있는지 평가하는 것이 우선입니다. CPU/GPU의 기존 워크로드와 입력/출력 데이터의 크기를 고려해야 합니다.
- 필요한 위치에 특정 전환 경로를 구현하기 위해 GetRawTextureData 같은 로우 레벨 함수를 사용하면 편의성은 좋지만 대개 불필요한 복사 및 전환을 수행하는 메서드를 사용할 때보다 성능이 개선될 수 있습니다.
- 대규모 리드백(되읽기) 및 픽셀 계산 등 복잡한 작업은 비동기 또는 병렬 형태로만 CPU에서 수행할 수 있습니다. 버스트 및 잡 시스템을 조합하면 보통은 GPU에서만 가능한 특정 작업을 C#에서 수행하도록 만들 수 있습니다.
- 자주 프로파일링해야 합니다. 개발 도중에는 예기치 못한 불필요한 전환부터 다른 프로세스를 기다리는 지연까지 다양한 문제에 직면할 수 있습니다. 어떤 성능 문제는 게임 규모가 커지고 특정 코드 부분의 사용량이 늘어나야만 비로소 모습을 드러내기도 합니다. 예시 프로젝트를 통해 텍스처 해상도가 조금만 증가해도 특정 API에서 성능 문제가 발생하는 것을 볼 수 있습니다.
스크립팅 또는 일반 그래픽스 포럼에서 텍스처 데이터에 대한 피드백을 공유해 주세요. 연재 중인 Tech from the Trenches 시리즈에서 다른 유니티 개발자들의 새로운 기술 블로그도 확인할 수 있습니다.