优化加载性能:了解异步上传管道


没人喜欢加载屏幕。您是否知道,您可以快速调整同步上传管道 (AUP) 参数,从而显著改善加载时间?本文详细介绍了如何通过 AUP 加载网格和纹理。这种理解可以帮助您大大加快加载时间--有些项目的性能提高了 2 倍以上!
请继续阅读,了解 AUP 如何从技术角度发挥作用,以及您应该使用哪些 API 来最大限度地利用它。
在 2018.3 版之前,AUP 只处理纹理。从2018.3 测试版开始,AUP 现在可以加载纹理和网格,但也有一些例外。启用读/写功能的纹理或启用读/写功能或压缩的网格不会使用 AUP。(请注意,2018.2 中引入的纹理 Mipmap 流也使用 AUP)。
在构建过程中,纹理或网格对象会被写入序列化文件,大型二进制数据(纹理或顶点数据)会被写入随附的 .resS 文件。该布局同时适用于播放器数据和资产包。将对象和二进制数据分开,可以更快地加载序列化文件(通常包含较小的对象),还能简化从 .resS 文件加载大型二进制数据的过程。纹理或网格对象反序列化后,会向 AUP 的命令队列提交一条命令。该命令完成后,纹理或网格数据就已上传到 GPU,对象就可以集成到主线程中了。

在上传过程中,.resS 文件中的大型二进制数据会被读入一个固定大小的环形缓冲区。数据一旦进入内存,就会在渲染线程上以时间分割的方式上传到 GPU。您可以更改环形缓冲区的大小和时间片的持续时间这两个参数来影响系统的行为。
异步上传管道对每条命令都有以下流程:
1.等待,直到环形缓冲区中有所需内存。
2.将源 .resS 文件中的数据读取到分配的内存中。
3.进行后期处理(纹理解压缩、网格碰撞生成、每个平台修复等)。
4.在渲染线程上以分时方式上传
5.释放环形缓冲区内存。
可以同时执行多个命令,但所有命令都必须从同一个共享环形缓冲区中分配所需的内存。当环形缓冲区填满时,新命令将等待;这种等待不会导致主线程阻塞或影响帧频,只会减慢异步加载过程。
这些影响概述如下:

为了充分利用 2018.3 中的 AUP,该系统有三个参数可以在运行时进行调整:
- QualitySettings.asyncUploadTimeSlice- 每帧在渲染线程上上传纹理和网格数据所用的时间(毫秒)。当异步加载操作正在进行时,系统将执行两个此大小的时间片。默认值为 2ms。如果该值太小,在纹理/网格 GPU 上传时可能会遇到瓶颈。反之,如果数值过大,可能会导致帧频不稳。
- QualitySettings.asyncUploadBufferSize 异步上传缓冲区大小- 环形缓冲区的大小(兆字节)。当每帧出现上传时间片时,我们要确保环形缓冲区中有足够的数据来利用整个时间片。如果环形缓冲区太小,上传时间片就会被缩短。2018.2 中的默认值为 4MB,但在 2018.3 中增加了 16MB。
- QualitySettings.asyncUploadPersistentBuffer- 在 2018.3 中引入,此标志决定上传环形缓冲区是否会在所有待读取完成后重新分配。分配和取消分配该缓冲区通常会导致内存碎片,因此一般应将其设置为默认值(true)。如果真的需要在不加载时回收内存,可以将此值设为 false。
这些设置可通过脚本 API 或质量设置菜单进行调整。

让我们使用默认的 2 毫秒时间片和 4MB 环形缓冲区,检查通过异步上传管道上传大量纹理和网格的工作负载。由于我们正在加载,每个渲染帧会有 2 个时间片,因此我们应该有 4 毫秒的上传时间。从剖析器的数据来看,我们只用了大约 1.5 毫秒。我们还可以看到,在上传之后,由于环形缓冲区中的内存可用,会立即发出新的读取操作。这表明需要更大的环形缓冲器。

让我们尝试增加 "环形缓冲区",由于我们正处于加载屏幕中,因此增加上传时间片也是个不错的主意。下面是一个 16MB 的环形缓冲区和 4 毫秒的时间片:

现在我们可以看到,我们几乎把所有的渲染线程时间都花在了上传上,而只是在上传与渲染之间的短暂时间内渲染帧。
以下是样本工作负载在不同上传时间片和环形缓冲区大小下的加载时间。测试在运行 OS X El Capitan 的 2.8GHz Intel Core i7 MacBook Pro 上进行。上传速度和 I/O 速度因平台和设备而异。工作负载是维京村示例项目的子集,我们内部使用它进行性能测试。由于还在加载其他对象,我们无法获得不同值的精确性能。不过可以肯定地说,在这种情况下,从 4MB/2MS 设置切换到 16MB/4MS 设置时,纹理和网格加载速度至少快了一倍。
对这些参数进行试验后得出以下结果。
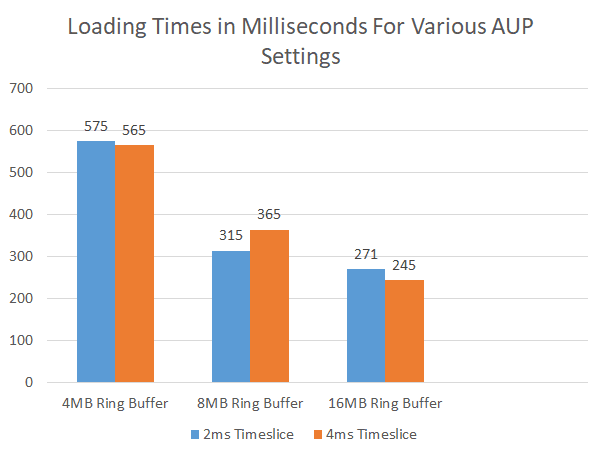
因此,为了优化这个特定示例项目的加载时间,我们应该这样配置设置:
未知块类型 "codeBlock",请在 "serializers.type "道具中为其指定一个序列化器
优化纹理和网格加载速度的一般建议:
- 选择不会导致丢帧的最大 QualitySettings.asyncUploadTimeSlice 值。
- 在加载屏幕时,暂时增加 QualitySettings.asyncUploadTimeSlice.
- 使用剖析器检查时间片的利用率。时间片将在剖析器中显示为 AsyncUploadManager.AsyncResourceUpload。如果您的时间片没有得到充分利用,请增加 QualitySettings.asyncUploadBufferSize 大小。
- 一般来说,QualitySettings.asyncUploadBufferSize 越大,加载速度就越快,因此如果内存容量允许,可将其增加到 16MB 或 32MB。
- 将 QualitySettings.asyncUploadPersistentBuffer 设置为 true,除非你有充分的理由在不加载时减少运行时内存使用量。
Q:渲染线程多久进行一次分时上传?
- 分时上传将在每个渲染帧中进行一次,或在异步加载操作中进行两次。VSync 会影响该管道。当渲染线程在等待 VSync 时,你可以进行上传。如果您以 16ms 帧运行,然后有一帧帧长,比如 17ms,您最终将等待 15ms 的 vsync。一般来说,帧频越高,上传时间片的频率就越高。
Q:AUP 装载了哪些内容?
- 未启用读/写功能的纹理通过 AUP 上传。
- 从 2018.2 版开始,纹理贴图通过 AUP 流式传输。
- 自 2018.3 版起,只要网格未压缩且未启用读/写功能,也可通过 AUP 上传。
Q:如果环形缓冲区不够大,无法容纳上传的数据(例如非常大的纹理),该怎么办?
- 大于环形缓冲区的上传命令将等待环形缓冲区完全耗尽,然后重新分配环形缓冲区以适应大的分配。上传完成后,环形缓冲区将重新分配为原来的大小。
Q:同步加载 API 如何工作?例如,Resources.Load、AssetBundle.LoadAsset 等。
- 同步加载调用使用 AUP,基本上会阻塞主线程,直到异步上传操作完成。所使用的加载 API 类型无关紧要。
我们一直在寻求反馈。请在评论中或Unity 2018.3 测试版论坛上告诉我们你的想法!