Optimización del rendimiento de la carga: Comprender el proceso de carga asíncrono


A nadie le gustan las pantallas de carga. ¿Sabías que puedes ajustar rápidamente los parámetros de Async Upload Pipeline (AUP) para mejorar significativamente tus tiempos de carga? Este artículo detalla cómo se cargan las mallas y texturas a través de la AUP. Esta comprensión podría ayudarle a acelerar el tiempo de carga de forma significativa: ¡algunos proyectos han visto mejoras de rendimiento de más del doble!
Siga leyendo para saber cómo funciona la AUP desde un punto de vista técnico y qué API debe utilizar para sacarle el máximo partido.
La última y más óptima implementación del Asset Upload Pipeline está disponible en la beta 2018.3.
Descargue hoy la versión beta 2018.3
En primer lugar, veamos en detalle cuándo se utiliza la PUA y cómo funciona el proceso de carga.
Antes de 2018.3, la AUP solo gestionaba texturas. A partir de la beta 2018.3, el AUP carga ahora texturas y mallas, pero hay algunas excepciones. Las texturas habilitadas para lectura/escritura, o las mallas habilitadas para lectura/escritura o comprimidas, no utilizarán la AUP. (Ten en cuenta que Texture Mipmap Streaming, que se introdujo en 2018.2, también utiliza AUP).
Durante el proceso de compilación, el objeto de textura o malla se escribe en un archivo serializado y los datos binarios grandes (datos de textura o vértice) se escriben en un archivo .resS adjunto. Esta disposición se aplica tanto a los datos de los reproductores como a los paquetes de activos. La separación de los datos de objetos y binarios permite cargar más rápidamente el archivo serializado (que generalmente contendrá objetos pequeños) y agilizar la carga posterior de los datos binarios grandes del archivo .resS. Cuando el objeto de textura o malla se deserializa, envía un comando a la cola de comandos de la AUP. Una vez que ese comando se completa, los datos de Textura o Malla se han cargado en la GPU y el objeto puede ser integrado en el hilo principal.

Durante el proceso de carga, los grandes datos binarios del archivo .resS se leen en un búfer en anillo de tamaño fijo. Una vez en memoria, los datos se cargan en la GPU de forma secuencial en el subproceso de renderizado. El tamaño de la memoria cíclica y la duración del corte de tiempo son los dos parámetros que puedes cambiar para afectar al comportamiento del sistema.
El Async Upload Pipeline tiene el siguiente proceso para cada comando:
1. Espere hasta que la memoria necesaria esté disponible en el búfer circular.
2. Lee los datos del archivo .resS de origen en la memoria asignada.
3. Realiza el posprocesamiento (descompresión de texturas, generación de colisiones de malla, arreglo por plataforma, etc.).
4. Cargar de forma escalonada en el hilo de renderizado
5. Liberar memoria intermedia de anillo.
Varios comandos pueden estar en curso simultáneamente, pero todos deben asignar la memoria necesaria del mismo búfer de anillo compartido. Cuando el ring buffer se llene, los nuevos comandos esperarán; esta espera no causará bloqueos en el hilo principal ni afectará a la tasa de fotogramas, simplemente ralentiza el proceso de carga asíncrona.
A continuación se resumen estos impactos:

Para aprovechar al máximo la AUP en 2018.3, hay tres parámetros que se pueden ajustar en tiempo de ejecución para este sistema:
- QualitySettings.asyncUploadTimeSlice - La cantidad de tiempo en milisegundos dedicado a cargar texturas y datos de malla en el hilo de renderizado para cada fotograma. Cuando una operación de carga asíncrona está en curso, el sistema realizará dos cortes de tiempo de este tamaño. El valor por defecto es 2ms. Si este valor es demasiado pequeño, podría producirse un cuello de botella en la carga de texturas/mallas en la GPU. Un valor demasiado grande, por otro lado, podría dar lugar a problemas de framerate.
- QualitySettings.asyncUploadBufferSize - El tamaño del Ring Buffer en Megabytes. Cuando el intervalo de tiempo de carga se produce en cada fotograma, queremos estar seguros de que tenemos suficientes datos en la memoria cíclica para utilizar todo el intervalo de tiempo. Si la memoria cíclica es demasiado pequeña, el tiempo de carga se acortará. El valor por defecto era de 4MB en 2018.2 pero ha aumentado 16MB en 2018.3.
- QualitySettings.asyncUploadPersistentBuffer - Introducido en 2018.3, este indicador determina si el búfer de anillo de carga se desasigna cuando se completan todas las lecturas pendientes. La asignación y desasignación de este búfer a menudo puede causar fragmentación de memoria, por lo que generalmente debe dejarse en su valor predeterminado (true). Si realmente necesita recuperar memoria cuando no está cargando, puede establecer este valor en false.
Estos parámetros pueden ajustarse a través de la API de scripting o mediante el menú QualitySettings.

Examinemos una carga de trabajo con muchas texturas y mallas que se cargan a través del Async Upload Pipeline utilizando el intervalo de tiempo predeterminado de 2 ms y un búfer de anillo de 4 MB. Como estamos cargando, tenemos 2 time-slices por frame de render, así que deberíamos tener 4 milisegundos de tiempo de carga. Observando los datos del perfilador, sólo utilizamos alrededor de 1,5 milisegundos. También podemos ver que, inmediatamente después de la carga, se emite una nueva operación de lectura ahora que hay memoria disponible en la memoria intermedia en anillo. Esto es señal de que se necesita un búfer anular mayor.

Intentemos aumentar el Ring Buffer y ya que estamos en una pantalla de carga, también es una buena idea aumentar el time-slice de carga. Esto es lo que parece una memoria cíclica de 16 MB y un intervalo de tiempo de 4 milisegundos:

Ahora podemos ver que estamos gastando casi todo el tiempo de nuestro hilo de renderizado cargando, y sólo un corto tiempo entre cargas renderizando el fotograma.
A continuación se muestran los tiempos de carga de la carga de trabajo de muestra con una variedad de cortes de tiempo de carga y tamaños de Ring Buffer. Las pruebas se realizaron en un MacBook Pro, Intel Core i7 a 2,8 GHz con OS X El Capitan. Las velocidades de carga y de E/S varían según la plataforma y el dispositivo. La carga de trabajo es un subconjunto del proyecto de muestra Viking Village que utilizamos internamente para las pruebas de rendimiento. Como se están cargando otros objetos, no podemos obtener el rendimiento exacto de los distintos valores. Sin embargo, en este caso se puede afirmar que la carga de texturas y mallas es al menos el doble de rápida al pasar de la configuración de 4 MB/2 MS a la de 16 MB/4 MS.
La experimentación con estos parámetros arroja los siguientes resultados.
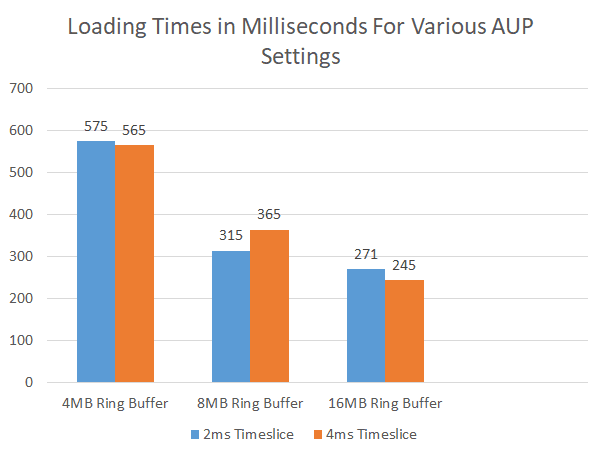
Para optimizar los tiempos de carga de este proyecto de ejemplo en particular, deberíamos, por lo tanto, configurar los parámetros de la siguiente manera:
Tipo de bloque desconocido "codeBlock", especifique un serializador para él en la propiedad `serializers.types`.
Recomendaciones generales para optimizar la velocidad de carga de texturas y mallas:
- Elija la mayor QualitySettings.asyncUploadTimeSlice que no provoque la caída de fotogramas.
- Durante las pantallas de carga, aumente temporalmente QualitySettings.asyncUploadTimeSlice.
- Utilice el perfilador para examinar la utilización de los intervalos de tiempo. El intervalo de tiempo se mostrará como AsyncUploadManager.AsyncResourceUpload en el perfilador. Aumente QualitySettings.asyncUploadBufferSize si su intervalo de tiempo no se utiliza completamente.
- Las cosas generalmente cargarán más rápido con un QualitySettings.asyncUploadBufferSize más grande, así que si puedes permitirte la memoria, auméntala a 16MB o 32MB.
- Deje QualitySettings.asyncUploadPersistentBuffer establecido en true a menos que tenga una razón de peso para reducir el uso de memoria en tiempo de ejecución mientras no se carga.
Q: ¿Con qué frecuencia se producirá la carga escalonada en el hilo de renderizado?
- La carga temporal se producirá una vez por fotograma de renderizado, o dos veces durante una operación de carga asíncrona. VSync afecta a este canal. Mientras el hilo de renderizado está esperando un VSync, podrías estar cargando. Si estás funcionando con fotogramas de 16ms y luego un fotograma se alarga, digamos 17ms, acabarás esperando el vsync durante 15ms. En general, cuanto mayor sea la frecuencia de fotogramas, más frecuentes serán los cortes de tiempo de carga.
Q: ¿Qué se carga a través de la AUP?
- Las texturas que no están habilitadas para lectura/escritura se cargan a través de la AUP.
- A partir de 2018.2, los mipmaps de textura se transmiten a través de la AUP.
- A partir de 2018.3, las mallas también se cargan a través de la AUP siempre que estén sin comprimir y no estén habilitadas para lectura/escritura.
Q: ¿Qué ocurre si la memoria cíclica no es lo suficientemente grande como para contener los datos que se cargan (por ejemplo, una textura muy grande)?
- Los comandos de carga que sean mayores que el búfer de anillo esperarán hasta que éste se consuma por completo, entonces el búfer de anillo se reasignará para ajustarse a la gran asignación. Una vez finalizada la carga, la memoria cíclica se reasignará a su tamaño original.
Q: ¿Cómo funcionan las API de carga síncrona? For example, Resources.Load, AssetBundle.LoadAsset, etc.
- Las llamadas de carga síncrona utilizan la AUP y esencialmente bloquearán el hilo principal hasta que se complete la operación de carga asíncrona. El tipo de API de carga utilizado no es relevante.
Siempre buscamos opiniones. ¡Dinos lo que piensas en los comentarios o en el foro de Unity 2018.3 beta!